This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Natural Language Processing (NLP) has experienced some of the most impactful breakthroughs in recent years, primarily due to the the transformer architecture. The introduction of word embeddings, most notably Word2Vec, was a pivotal moment in NLP. One-hot encoding is a prime example of this limitation.
Transformers in NLP In 2017, Cornell University published an influential paper that introduced transformers. These are deep learning models used in NLP. Hugging Face , started in 2016, aims to make NLP models accessible to everyone. This discovery fueled the development of large language models like ChatGPT.
This article explores an innovative way to streamline the estimation of Scope 3 GHG emissions leveraging AI and Large Language Models (LLMs) to help categorize financial transaction data to align with spend-based emissions factors. Why are Scope 3 emissions difficult to calculate?
Labeling the wellness dimensions requires a clear understanding of social and psychological factors; we have invited an expert panel, including a clinical psychologist, rehabilitation counselor, and social NLP researcher. What are wellness dimensions? Considering its structure, we have taken Halbert L.
Natural Language Processing (NLP) is integral to artificial intelligence, enabling seamless communication between humans and computers. This interdisciplinary field incorporates linguistics, computer science, and mathematics, facilitating automatic translation, text categorization, and sentiment analysis.
It needed to intelligently categorize transactions based on their descriptions and other contextual factors about the business to ensure they are mapped to the appropriate classification. They have seen an increase of 56% transaction classification accuracy after moving to the new BERT based model.
This advancement has spurred the commercial use of generative AI in natural language processing (NLP) and computer vision, enabling automated and intelligent data extraction. Named Entity Recognition ( NER) Named entity recognition (NER), an NLP technique, identifies and categorizes key information in text.
We’ll start with a seminal BERT model from 2018 and finish with this year’s latest breakthroughs like LLaMA by Meta AI and GPT-4 by OpenAI. BERT by Google Summary In 2018, the Google AI team introduced a new cutting-edge model for Natural Language Processing (NLP) – BERT , or B idirectional E ncoder R epresentations from T ransformers.
While large language models (LLMs) have claimed the spotlight since the debut of ChatGPT, BERT language models have quietly handled most enterprise natural language tasks in production. Additionally, while the data and code needed to train some of the latest generation of models is still closed-source, open source variants of BERT abound.
Foundation models can be trained to perform tasks such as data classification, the identification of objects within images (computer vision) and natural language processing (NLP) (understanding and generating text) with a high degree of accuracy. An open-source model, Google created BERT in 2018. All watsonx.ai
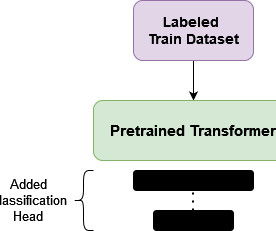
Introduction The idea behind using fine-tuning in Natural Language Processing (NLP) was borrowed from Computer Vision (CV). Despite the popularity and success of transfer learning in CV, for many years it wasnt clear what the analogous pretraining process was for NLP. How is Fine-tuning Different from Pretraining?
Consequently, there’s been a notable uptick in research within the natural language processing (NLP) community, specifically targeting interpretability in language models, yielding fresh insights into their internal operations.
Introduction In natural language processing, text categorization tasks are common (NLP). transformer.ipynb” uses the BERT architecture to classify the behaviour type for a conversation uttered by therapist and client, i.e, The architecture of BERT is represented in Figure 14. Uysal and Gunal, 2014).
Types of summarizations There are several techniques to summarize text, which are broadly categorized into two main approaches: extractive and abstractive summarization. Extractive summarization Extractive summarization is a technique used in NLP and text analysis to create a summary by extracting key sentences.
With advancements in deep learning, natural language processing (NLP), and AI, we are in a time period where AI agents could form a significant portion of the global workforce. Transformers and Advanced NLP Models : The introduction of transformer architectures revolutionized the NLP landscape.
Blockchain technology can be categorized primarily on the basis of the level of accessibility and control they offer, with Public, Private, and Federated being the three main types of blockchain technologies.
They serve as a core building block in many natural language processing (NLP) applications today, including information retrieval, question answering, semantic search and more. More recent methods based on pre-trained language models like BERT obtain much better context-aware embeddings. Adding it provided negligible improvements.
Natural language processing (NLP) activities, including speech-to-text, sentiment analysis, text summarization, spell-checking, token categorization, etc., RoBERTa (Robustly Optimized BERT Approach) is the outcome, and it achieves XLNet-level performance on the GLUE (General Language Understanding Evaluation) test.
These advanced AI deep learning models have seamlessly integrated into various applications, from Google's search engine enhancements with BERT to GitHub’s Copilot, which harnesses the capability of Large Language Models (LLMs) to convert simple code snippets into fully functional source codes. How Are LLMs Used?
Manually analyzing and categorizing large volumes of unstructured data, such as reviews, comments, and emails, is a time-consuming process prone to inconsistencies and subjectivity. By using the pre-trained knowledge of LLMs, zero-shot and few-shot approaches enable models to perform NLP with minimal or no labeled data.
Natural Language Processing (NLP) is a subfield of artificial intelligence. Machine translation, summarization, ticket categorization, and spell-checking are among the examples. BERT (Bidirectional Encoder Representations from Transformers) — developed by Google. T5 (Text-to-Text Transfer Transformer) — developed by Google.
Huge transformer models like BERT, GPT-2 and XLNet have set a new standard for accuracy on almost every NLP leaderboard. It features consistent and easy-to-use interfaces to several models, which can extract features to power your NLP pipelines. In this post we introduce our new wrapping library, spacy-transformers.
The development of Large Language Models (LLMs), such as GPT and BERT, represents a remarkable leap in computational linguistics. The system’s error detection mechanism is designed to identify and categorize failures during execution promptly. Training these models, however, is challenging. Check out the Paper.
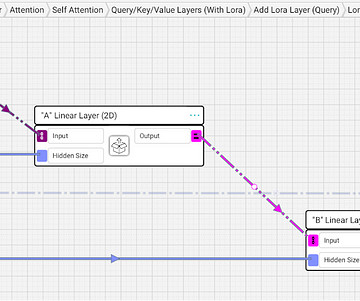
Back when BERT and GPT2 were first revolutionizing natural language processing (NLP), there was really only one playbook for fine-tuning. BERT LoRA First, I’ll show LoRA in the BERT implementation, and then I’ll do the same for GPT. You had to be very careful with fine-tuning because of catastrophic forgetting.
Be sure to check out his talk, “ Bagging to BERT — A Tour of Applied NLP ,” there! If a Natural Language Processing (NLP) system does not have that context, we’d expect it not to get the joke. I’ll be making use of the powerful SpaCy library which makes swapping architectures in NLP pipelines a breeze.
ChatGPT released by OpenAI is a versatile Natural Language Processing (NLP) system that comprehends the conversation context to provide relevant responses. Question Answering has been an active research area in NLP for many years so there are several datasets that have been created for evaluating QA systems.
In this solution, we train and deploy a churn prediction model that uses a state-of-the-art natural language processing (NLP) model to find useful signals in text. In addition to textual inputs, this model uses traditional structured data inputs such as numerical and categorical fields. Solution overview.
Calculate a ROUGE-N score You can use the following steps to calculate a ROUGE-N score: Tokenize the generated summary and the reference summary into individual words or tokens using basic tokenization methods like splitting by whitespace or natural language processing (NLP) libraries.
These embeddings are useful for various natural language processing (NLP) tasks such as text classification, clustering, semantic search, and information retrieval. M5 LLMS are BERT-based LLMs fine-tuned on internal Amazon product catalog data using product title, bullet points, description, and more. str.split("|").str[0]
In this post, we explore the utilization of pre-trained models within the Healthcare NLP library by John Snow Labs to map medical terminology to the MedDRA ontology. Specifically, our aim is to facilitate standardized categorization for enhanced medical data analysis and interpretation. that map clinical terms to MedDRA codes.
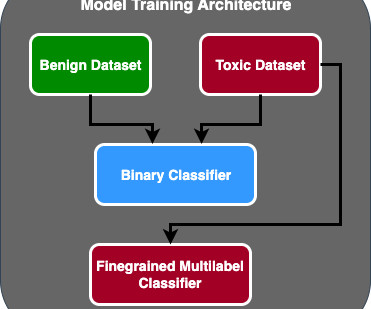
Lastly, with the help of expert annotators, we were successful in categorizing the data based on the respective criteria for both escapism and PTSD. So, how did we work on the categorizing? were used to capture nuanced language patterns.
As an added inherent challenge, natural language processing (NLP) classifiers are historically known to be very costly to train and require a large set of vocabulary, known as a corpus , to produce accurate predictions. Due to the sequential nature of text, recurrent neural networks (RNNs) had been the state of the art for NLP modeling.
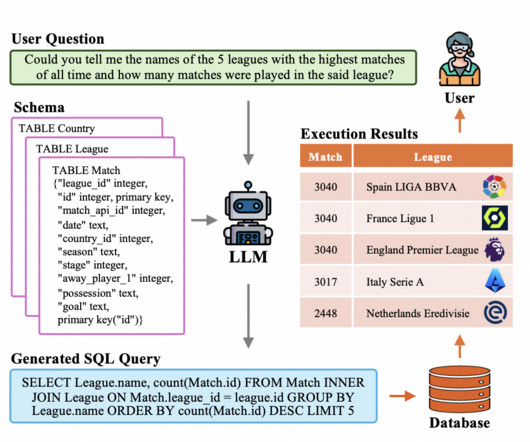
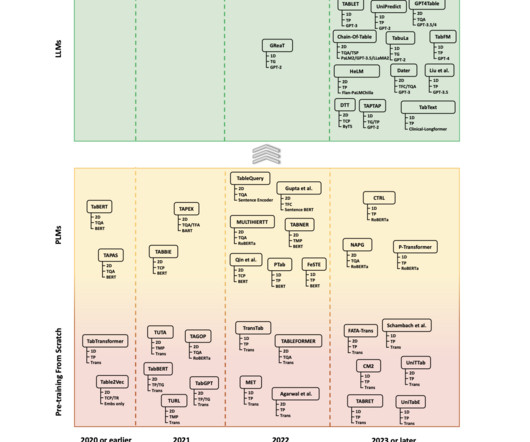
Evolutionary Process Since its inception, text-to-SQL has seen tremendous growth within the natural language processing (NLP) community, moving from rule-based to deep learning-based methodologies and, most recently, merging PLMs and LLMs. However, with minimum domain-specific training, they can be effectively adapted.
More recently, techniques from NLP have been adapted for tabular data; more specifically, transformer-based architectures are increasingly implemented. Against this backdrop, researchers began using PLMs like BERT, which required less data and provided better predictive performance.
Automated document analysis AI tools designed for law firms use advanced technologies like NLP and machine learning to analyze extensive legal documents swiftly. By extracting information, identifying patterns, and categorizing content within minutes, these tools enhance efficiency for legal professionals.
BERTBERT, an acronym that stands for “Bidirectional Encoder Representations from Transformers,” was one of the first foundation models and pre-dated the term by several years. BERT proved useful in several ways, including quantifying sentiment and predicting the words likely to follow in unfinished sentences.
But if you’re working on the same sort of Natural Language Processing (NLP) problems that businesses have been trying to solve for a long time, what’s the best way to use them? We want to aggregate it, link it, filter it, categorize it, generate it and correct it. We want to recommend people text based on other text they liked.
The previous year saw a significant increase in the amount of work that concentrated on Computer Vision (CV) and Natural Language Processing (NLP). MusicLM is specifically trained on SoundStream, w2v-BERT, and MuLan pre-trained modules. MusicCaps is a publicly available dataset with 5.5k
While large language models (LLMs) have demonstrated impressive capabilities in various natural language processing (NLP) tasks, their performance in this domain has been limited by the inherent complexities of medical language and the nuances involved in interpreting clinical narratives.
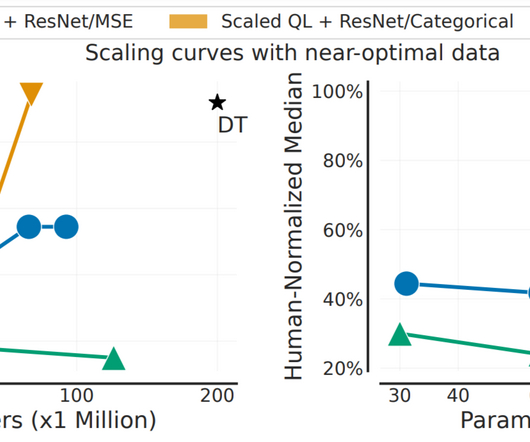
Pre-training on diverse datasets has proven to enable data-efficient fine-tuning for individual downstream tasks in natural language processing (NLP) and vision problems. Additionally, we utilized a categorical distributional RL loss for Q-learning, which is known to provide richer representations that improve downstream task performance.
Natural language processing (NLP) is a critical branch of artificial intelligence devoted to understanding and generating natural language. However, NLP systems are susceptible to biases, often mirroring the prejudices found in their training data. How to use the LangTest library to evaluate LLM for bias using CrowS-Pairs dataset?
In the general language domain, there are two main branches of pre-trained language models: BERT (and its variants) and GPT (and its variants). The first one, BERT (and its variants), has received the most attention in the biomedical domain; examples include BioBERT and PubMedBERT, while the second one has received less attention.
Here are a few examples across various domains: Natural Language Processing (NLP) : Predictive NLP models can categorize text into predefined classes (e.g., spam vs. not spam), while generative NLP models can create new text based on a given prompt (e.g., a social media post or product description).
Prasanna Balaprakash, research and development lead from Argonne National Laboratory gave a presentation entitled “Extracting the Impact of Climate Change from Scientific Literature using Snorkel-Enabled NLP” at Snorkel AI’s Future of Data-Centric AI Workshop in August, 2022. Even for NLP folks, this is a pretty remarkable thing.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content