This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
NaturalLanguageProcessing (NLP) has experienced some of the most impactful breakthroughs in recent years, primarily due to the the transformer architecture. BERT T5 (Text-to-Text Transfer Transformer) : Introduced by Google in 2020 , T5 reframes all NLP tasks as a text-to-text problem, using a unified text-based format.
NaturalLanguageProcessing (NLP) is integral to artificial intelligence, enabling seamless communication between humans and computers. This interdisciplinary field incorporates linguistics, computer science, and mathematics, facilitating automatic translation, text categorization, and sentiment analysis.
This article explores an innovative way to streamline the estimation of Scope 3 GHG emissions leveraging AI and Large Language Models (LLMs) to help categorize financial transaction data to align with spend-based emissions factors. Why are Scope 3 emissions difficult to calculate? This is where LLMs come into play.
This advancement has spurred the commercial use of generative AI in naturallanguageprocessing (NLP) and computer vision, enabling automated and intelligent data extraction. Named Entity Recognition ( NER) Named entity recognition (NER), an NLP technique, identifies and categorizes key information in text.
Figure 1: adversarial examples in computer vision (left) and naturallanguageprocessing tasks (right). This is generally a positive thing, but it sometimes over-generalizes , leading to examples such as this: Figure 4: BERT guesses that the masked token should be a color, but fails to predict the correct color.
Consequently, there’s been a notable uptick in research within the naturallanguageprocessing (NLP) community, specifically targeting interpretability in language models, yielding fresh insights into their internal operations. Recent approaches automate circuit discovery, enhancing interpretability.
Naturallanguageprocessing (NLP) activities, including speech-to-text, sentiment analysis, text summarization, spell-checking, token categorization, etc., rely on Language Models as their foundation. Unigrams, N-grams, exponential, and neural networks are valid forms for the Language Model.
Applications for naturallanguageprocessing (NLP) have exploded in the past decade. Modern techniques can capture the nuance, context, and sophistication of language, just as humans do. Each participant will be provided with dedicated access to a fully configured, GPU-accelerated server in the cloud.
A foundation model is built on a neural network model architecture to process information much like the human brain does. A specific kind of foundation model known as a large language model (LLM) is trained on vast amounts of text data for NLP tasks. An open-source model, Google created BERT in 2018.
Photo by Shubham Dhage on Unsplash Introduction Large language Models (LLMs) are a subset of Deep Learning. Image by YouTube video “Introduction to large language models” on YouTube Channel “Google Cloud Tech” What are Large Language Models? NaturalLanguageProcessing (NLP) is a subfield of artificial intelligence.
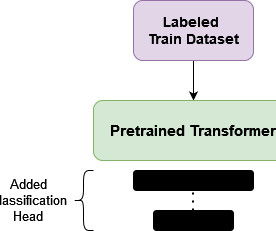
Well do so in three levels: first, by manually adding a classification head in PyTorch* and training the model so you can see the full process; second, by using the Hugging Face* Transformers library to streamline the process; and third, by leveraging PyTorch Lightning* and accelerators to optimize training performance.
They serve as a core building block in many naturallanguageprocessing (NLP) applications today, including information retrieval, question answering, semantic search and more. More recent methods based on pre-trained language models like BERT obtain much better context-aware embeddings.
In the rapidly evolving field of artificial intelligence, naturallanguageprocessing has become a focal point for researchers and developers alike. We’ll start with a seminal BERT model from 2018 and finish with this year’s latest breakthroughs like LLaMA by Meta AI and GPT-4 by OpenAI. billion word corpus).
ChatGPT released by OpenAI is a versatile NaturalLanguageProcessing (NLP) system that comprehends the conversation context to provide relevant responses. Although little is known about construction of this model, it has become popular due to its quality in solving naturallanguage tasks.
Manually analyzing and categorizing large volumes of unstructured data, such as reviews, comments, and emails, is a time-consuming process prone to inconsistencies and subjectivity. Businesses can use LLMs to gain valuable insights, streamline processes, and deliver enhanced customer experiences. No explanation is required.
Blockchain technology can be categorized primarily on the basis of the level of accessibility and control they offer, with Public, Private, and Federated being the three main types of blockchain technologies.
With advancements in deep learning, naturallanguageprocessing (NLP), and AI, we are in a time period where AI agents could form a significant portion of the global workforce. Systems like ChatGPT by OpenAI, BERT, and T5 have enabled breakthroughs in human-AI communication.
Introduction In naturallanguageprocessing, text categorization tasks are common (NLP). transformer.ipynb” uses the BERT architecture to classify the behaviour type for a conversation uttered by therapist and client, i.e, The architecture of BERT is represented in Figure 14. Uysal and Gunal, 2014).
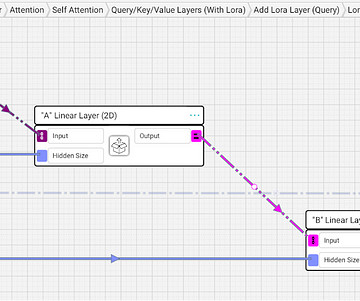
Back when BERT and GPT2 were first revolutionizing naturallanguageprocessing (NLP), there was really only one playbook for fine-tuning. BERT LoRA First, I’ll show LoRA in the BERT implementation, and then I’ll do the same for GPT. 768), and an integer r.
Lastly, with the help of expert annotators, we were successful in categorizing the data based on the respective criteria for both escapism and PTSD. So, how did we work on the categorizing? were used to capture nuanced language patterns.
In modern machine learning and artificial intelligence frameworks, transformers are one of the most widely used components across various domains including GPT series, and BERT in NaturalLanguageProcessing, and Vision Transformers in computer vision tasks.
In this solution, we train and deploy a churn prediction model that uses a state-of-the-art naturallanguageprocessing (NLP) model to find useful signals in text. In addition to textual inputs, this model uses traditional structured data inputs such as numerical and categorical fields. BERT + Random Forest.
Huge transformer models like BERT, GPT-2 and XLNet have set a new standard for accuracy on almost every NLP leaderboard. Transformers and transfer-learning NaturalLanguageProcessing (NLP) systems face a problem known as the “knowledge acquisition bottleneck”. We have updated our library and this blog post accordingly.
These embeddings are useful for various naturallanguageprocessing (NLP) tasks such as text classification, clustering, semantic search, and information retrieval. M5 LLMS are BERT-based LLMs fine-tuned on internal Amazon product catalog data using product title, bullet points, description, and more. str.split("|").str[0]
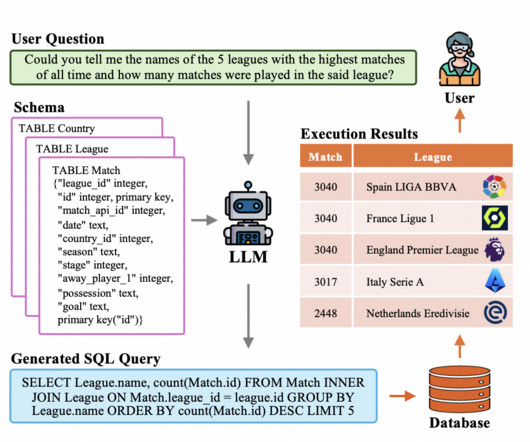
Evolutionary Process Since its inception, text-to-SQL has seen tremendous growth within the naturallanguageprocessing (NLP) community, moving from rule-based to deep learning-based methodologies and, most recently, merging PLMs and LLMs. However, with minimum domain-specific training, they can be effectively adapted.
Be sure to check out his talk, “ Bagging to BERT — A Tour of Applied NLP ,” there! If a NaturalLanguageProcessing (NLP) system does not have that context, we’d expect it not to get the joke. Raw text is fed into the Language object, which produces a Doc object. It’s all about context! We’ll be mainly using the “.cats”
This process results in generalized models capable of a wide variety of tasks, such as image classification, naturallanguageprocessing, and question-answering, with remarkable accuracy. BERT proved useful in several ways, including quantifying sentiment and predicting the words likely to follow in unfinished sentences.
The previous year saw a significant increase in the amount of work that concentrated on Computer Vision (CV) and NaturalLanguageProcessing (NLP). Because of this, academics worldwide are looking at the potential benefits deep learning and large language models (LLMs) might bring to audio generation.
Here are a few examples across various domains: NaturalLanguageProcessing (NLP) : Predictive NLP models can categorize text into predefined classes (e.g., For example, large language models (LLMs) are trained by randomly replacing some of the tokens in training data with a special token, such as [MASK].
Calculate a ROUGE-N score You can use the following steps to calculate a ROUGE-N score: Tokenize the generated summary and the reference summary into individual words or tokens using basic tokenization methods like splitting by whitespace or naturallanguageprocessing (NLP) libraries.
Naturallanguageprocessing (NLP) is a critical branch of artificial intelligence devoted to understanding and generating naturallanguage. report() Output of the.report() In this snippet, we defined the task as crows-pairs , the model as bert-base-uncased from huggingface , and the data as CrowS-Pairs.
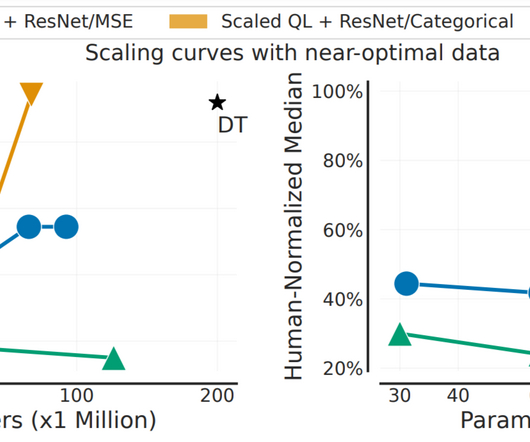
Pre-training on diverse datasets has proven to enable data-efficient fine-tuning for individual downstream tasks in naturallanguageprocessing (NLP) and vision problems. However, running RL algorithms in the real world requires expensive active data collection.
In this article, we will explore about ALBERT ( A lite weighted version of BERT machine learning model) What is ALBERT? ALBERT (A Lite BERT) is a language model developed by Google Research in 2019. BERT, GPT-2, and XLNet are some examples of models that can be used as teacher models for ALBERT.
Summary : Sentiment Analysis is a naturallanguageprocessing technique that interprets and classifies emotions expressed in text. Sentiment Analysis is a popular task in naturallanguageprocessing. It uses various NaturalLanguageProcessing algorithms such as Rule-based, Automatic, and Hybrid.
LLMs apply powerful NaturalLanguageProcessing (NLP), machine translation, and Visual Question Answering (VQA). Categorization of LLMs – Source One of the most common examples of an LLM is a virtual voice assistant such as Siri or Alexa. GPT-4, BERT) based on your specific task requirements.
A brief history of large language models Large language models grew out of research and experiments with neural networks to allow computers to processnaturallanguage. In the 2010s, this research intersected with the then-bustling field of neural networks, setting the ground for the first large language model.
A brief history of large language models Large language models grew out of research and experiments with neural networks to allow computers to processnaturallanguage. In the 2010s, this research intersected with the then-bustling field of neural networks, setting the ground for the first large language model.
A noteworthy observation is that even popular models in the machine learning community, such as bert-base-uncased, xlm-roberta-base, etc exhibit these biases. Thus highlighting the importance of identifying and remedying gender-occupational stereotypes within AI and naturallanguageprocessing.
This innovative approach is transforming applications in computer vision, NaturalLanguageProcessing, healthcare, and more. Flexibility The ability of ZSL models to adapt quickly to new tasks without retraining makes them highly flexible tools for various applications, from image recognition to NaturalLanguageProcessing.
In this workshop, you’ll learn how deep learning works through hands-on exercises in computer vision and naturallanguageprocessing. In this workshop, you’ll learn how deep learning works through hands-on exercises in computer vision and naturallanguageprocessing.
Introducing NaturalLanguageProcessing (NLP) , a branch of artificial intelligence (AI) specifically designed to give computers the ability to understand text and spoken words in much the same way as human beings. Text Classification : Categorizing text into predefined categories based on its content.
AI is accelerating complaint resolution for banks AI can help banks automate many of the tasks involved in complaint handling, such as: Identifying, categorizing, and prioritizing complaints. Naturallanguageprocessing to extract key information quickly. Assigning complaints to staff. Tracking the status of complaints.
AI is accelerating complaint resolution for banks AI can help banks automate many of the tasks involved in complaint handling, such as: Identifying, categorizing, and prioritizing complaints. Naturallanguageprocessing to extract key information quickly. Assigning complaints to staff. Tracking the status of complaints.
AI is accelerating complaint resolution for banks AI can help banks automate many of the tasks involved in complaint handling, such as: Identifying, categorizing, and prioritizing complaints. Naturallanguageprocessing to extract key information quickly. Assigning complaints to staff. Tracking the status of complaints.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































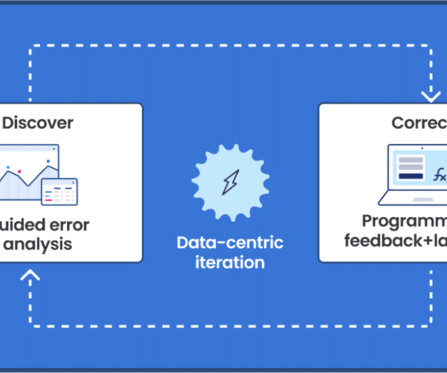
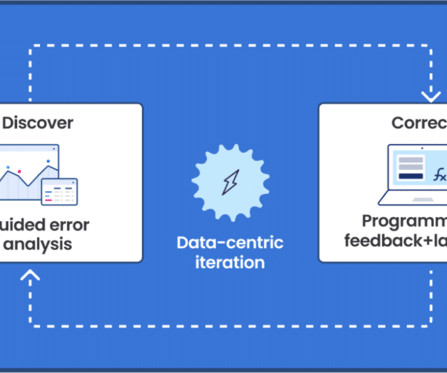
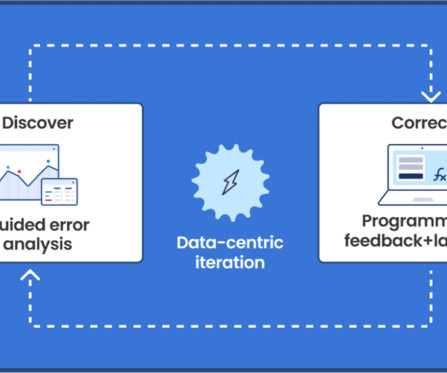






Let's personalize your content