This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
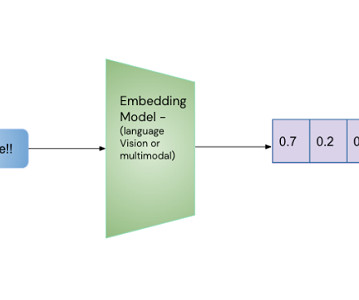
They use real-time data and machinelearning (ML) to offer customized loans that fuel sustainable growth and solve the challenges of accessing capital. This approach combines the efficiency of machinelearning with human judgment in the following way: The ML model processes and classifies transactions rapidly.
This panel has designed the guidelines for annotating the wellness dimensions and categorized the posts into the six wellness dimensions based on the sensitive content of each post. Using BERT and MentalBERT, we could capture these subtleties effectively by contextualizing each word based on the surrounding text.
This article explores an innovative way to streamline the estimation of Scope 3 GHG emissions leveraging AI and Large Language Models (LLMs) to help categorize financial transaction data to align with spend-based emissions factors. Why are Scope 3 emissions difficult to calculate?
Experiments proceed iteratively, with results categorized as improvements, maintenance, or declines. to close the gap between BERT-base and BERT-large performance. It automatically generates and debugs code using an exception-traceback-guided process. improvement over baseline models.
It’s the underlying engine that gives generative models the enhanced reasoning and deep learning capabilities that traditional machinelearning models lack. BERT (Bi-directional Encoder Representations from Transformers) is one of the earliest LLM foundation models developed.
Be sure to check out their talk, “ Getting Up to Speed on Real-Time MachineLearning ,” there! The benefits of real-time machinelearning are becoming increasingly apparent. Anomaly detection, including fraud detection and network intrusion monitoring, particularly exemplifies the challenges of real-time machinelearning.
Manually analyzing and categorizing large volumes of unstructured data, such as reviews, comments, and emails, is a time-consuming process prone to inconsistencies and subjectivity. We provide a prompt example for feedback categorization. Extracting valuable insights from customer feedback presents several significant challenges.
While large language models (LLMs) have claimed the spotlight since the debut of ChatGPT, BERT language models have quietly handled most enterprise natural language tasks in production. Additionally, while the data and code needed to train some of the latest generation of models is still closed-source, open source variants of BERT abound.
M5 LLMS are BERT-based LLMs fine-tuned on internal Amazon product catalog data using product title, bullet points, description, and more. XGBoost classification XGBoost (Extreme Gradient Boosting) classification is a machinelearning technique used for classification tasks. str.split("|").str[0] All other code remains the same.
Transformer architectures give a machinelearning model the ability to use self-attention mechanisms to recognize links between words in a phrase, independent of where they appear in the text sequence. Machine translation, summarization, ticket categorization, and spell-checking are among the examples.
A model’s parameters are the components learned from previous training data and, in essence, establish the model’s proficiency on a task, such as text generation. Natural language processing (NLP) activities, including speech-to-text, sentiment analysis, text summarization, spell-checking, token categorization, etc.,
In the case of GPT models, this self-supervised learning includes predicting the next word (unidirectional) based on their training data, which is often webpages. In the case of BERT (Bidirectional Encoder Representations from Transformers), learning involves predicting randomly masked words (bidirectional) and sentence-order prediction.
Amazon SageMaker JumpStart is the MachineLearning (ML) hub of SageMaker providing pre-trained, publicly available models for a wide range of problem types to help you get started with machinelearning. Understanding customer behavior is top of mind for every business today. For more details, refer to the GitHub repo.
Introduction In natural language processing, text categorization tasks are common (NLP). transformer.ipynb” uses the BERT architecture to classify the behaviour type for a conversation uttered by therapist and client, i.e, Figure 1 Preprocessing Data preprocessing is an essential step in building a MachineLearning model.
In modern machinelearning and artificial intelligence frameworks, transformers are one of the most widely used components across various domains including GPT series, and BERT in Natural Language Processing, and Vision Transformers in computer vision tasks. So let’s get started. MambaOut: Is Mamba Really Needed for Vision?
Huge transformer models like BERT, GPT-2 and XLNet have set a new standard for accuracy on almost every NLP leaderboard. In a recent talk at Google Berlin, Jacob Devlin described how Google are using his BERT architectures internally. In this post we introduce our new wrapping library, spacy-transformers.
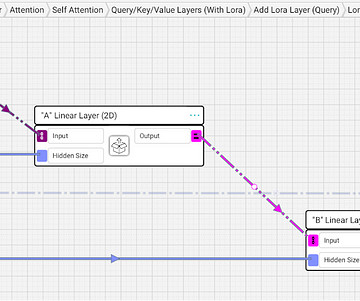
Visualized Implementation of LoRA Fine-tuning, which is the learning or updating of weights in a transformer model, can be the delta between a model that’s not ready for production to one that is robust enough to put in front of customers. BERT LoRA First, I’ll show LoRA in the BERT implementation, and then I’ll do the same for GPT.
The most common techniques used for extractive summarization are term frequency-inverse document frequency (TF-IDF), sentence scoring, text rank algorithm, and supervised machinelearning (ML). It uses BERT, a popular NLP technique, to understand the meaning and context of words in the candidate summary and reference summary.
As an Edge AI implementation, TensorFlow Lite greatly reduces the barriers to introducing large-scale computer vision with on-device machinelearning, making it possible to run machinelearning everywhere. TensorFlow Lite is specially optimized for on-device machinelearning (Edge ML).
The DeepPavlov Library uses BERT base models to deal with Question Answering, such as RoBERTa. BERT is a pre-trained transformer-based deep learning model for natural language processing that achieved state-of-the-art results across a wide array of natural language processing tasks when this model was proposed.
The development of Large Language Models (LLMs), such as GPT and BERT, represents a remarkable leap in computational linguistics. The system’s error detection mechanism is designed to identify and categorize failures during execution promptly. Training these models, however, is challenging.
Recognizing the critical need for addressing mental health fallouts, we have developed an annotated dataset and machinelearning framework to monitor and assess mental health conditions within the metaverse. So, how did we work on the categorizing? Here we are, with our shield of protection!
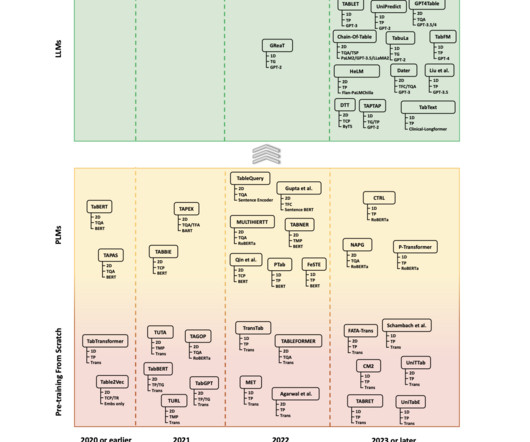
Traditional machinelearning models stay far away when considering the complex relationships inside tabular datasets, especially for large and complex datasets. Early techniques relied largely on conventional machinelearning, most of which needed a lot of feature engineering to model the subtleties of the data.
In this article, we will review the key machine-learning techniques driving these two major classes of AI approaches, the unique benefits and challenges associated with them, and their respective real-world business applications. It is usually based on supervised learning, which is a type of machinelearning that requires labeled data.
We’ll start with a seminal BERT model from 2018 and finish with this year’s latest breakthroughs like LLaMA by Meta AI and GPT-4 by OpenAI. BERT by Google Summary In 2018, the Google AI team introduced a new cutting-edge model for Natural Language Processing (NLP) – BERT , or B idirectional E ncoder R epresentations from T ransformers.
a low-code enterprise graph machinelearning (ML) framework to build, train, and deploy graph ML solutions on complex enterprise-scale graphs in days instead of months. This allows GuardDuty to categorize previously unseen domains as highly likely to be malicious or benign based on their association to known malicious domains.
Automated document analysis AI tools designed for law firms use advanced technologies like NLP and machinelearning to analyze extensive legal documents swiftly. By extracting information, identifying patterns, and categorizing content within minutes, these tools enhance efficiency for legal professionals.
Traditionally, this task required extensive manual labeling and a deep understanding of machinelearning techniques, presenting significant barriers to entry. For instance, a BERT model with 86 million parameters can perform NLI tasks, while the smallest effective zero-shot generative LLMs require 7-8 billion parameters.
Foundation Models (FMs), such as GPT-3 and Stable Diffusion, mark the beginning of a new era in machinelearning and artificial intelligence. Foundation models are large AI models trained on enormous quantities of unlabeled data—usually through self-supervised learning. What is self-supervised learning?
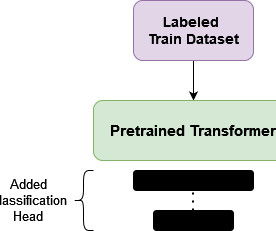
Amazon SageMaker Studio provides a fully managed solution for data scientists to interactively build, train, and deploy machinelearning (ML) models. The SST2 dataset is a text classification dataset with two labels (0 and 1) and a column of text to categorize.
Be sure to check out his talk, “ Bagging to BERT — A Tour of Applied NLP ,” there! cats” component of Docs, for which we’ll be training a text categorization model to classify sentiment as “positive” or “negative.” Editor’s note: Benjamin Batorsky, PhD is a speaker for ODSC East 2023. These can be customized and trained.
Small-size IoT (Internet of Things) devices and light machinelearning models are becoming increasingly popular due to the growing demand for connected devices and intelligent automation in various industries. In this article, we will explore about ALBERT ( A lite weighted version of BERTmachinelearning model) What is ALBERT?
This system comprises a lightweight BERT-based router categorizing incoming queries into predefined domains such as health, science, and coding. Researchers from the University of Melbourne introduced a groundbreaking solution named MoDEM (Mixture of Domain Expert Models).
BERT, the first breakout large language model In 2019, a team of researchers at Goole introduced BERT (which stands for bidirectional encoder representations from transformers). By making BERT bidirectional, it allowed the inputs and outputs to take each others’ context into account. BERT), or consist of both (e.g.,
BERT, the first breakout large language model In 2019, a team of researchers at Goole introduced BERT (which stands for bidirectional encoder representations from transformers). By making BERT bidirectional, it allowed the inputs and outputs to take each others’ context into account. BERT), or consist of both (e.g.,
Often featuring tens of billions of parameters, these models are significantly more resource-intensive than established augmentation methods such as back translation paraphrasing or BERT-based techniques. and Llama-3-8B.
It employs various approaches, including lexicon-based, MachineLearning, and hybrid methods. Various approaches include lexicon-based, MachineLearning, and rule-based methods. Hybrid Approaches Hybrid methods combine lexicon-based and MachineLearning techniques to leverage the strengths of both approaches.
Famous models like BERT and others, begin their journey with initial training on massive datasets encompassing vast swaths of internet text. I really recommend going over the paper to learn more. So as you can see above in the picture the taxonomy can be broadly categorized into: 1.
Transformer-based models, such as Bidirectional Encoder Representations from Transformers (BERT), have revolutionized NLP by offering accuracy comparable to human baselines on benchmarks like SQuAD for question-answer, entity recognition, intent recognition, sentiment analysis, and more. DGX/EGX family, GPU-based Embedded Platforms i.e
The concept of Zero-Shot Learning is not merely a technical novelty; it addresses real-world challenges faced by industries reliant on AI. Traditional MachineLearning models require extensive labelled datasets for every class they need to predict. Can Zero-Shot Learning Be Applied in Real-Time Systems?
A noteworthy observation is that even popular models in the machinelearning community, such as bert-base-uncased, xlm-roberta-base, etc exhibit these biases. It can identify entities (NER), categorize texts (Text Classification), flag inappropriate content (Toxicity), and even facilitate question-answering capabilities.
Text Classification : Categorizing text into predefined categories based on its content. Machine Translation : Translating text from one language to another. It is used to automatically detect and categorize posts or comments into various groups such as ‘offensive’, ‘non-offensive’, ‘spam’, ‘promotional’, and others.
In today’s digital world, Artificial Intelligence (AI) and Machinelearning (ML) models are used everywhere, from face detection in electronic devices to real-time language translation. Efficient, quick, and cost-effective learning processes are crucial for scaling these models. Book a demo to learn more.
Machinelearning especially Deep Learning is the backbone of every LLM. LLMs apply powerful Natural Language Processing (NLP), machine translation, and Visual Question Answering (VQA). Categorization of LLMs – Source One of the most common examples of an LLM is a virtual voice assistant such as Siri or Alexa.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content