
MARKLLM: An Open-Source Toolkit for LLM Watermarking
Unite.AI
JULY 9, 2024
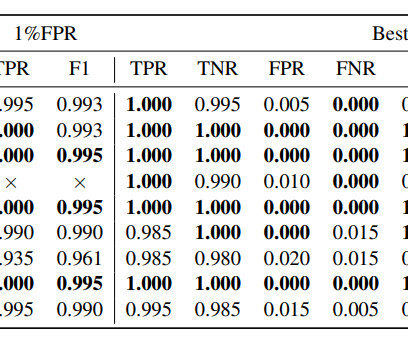
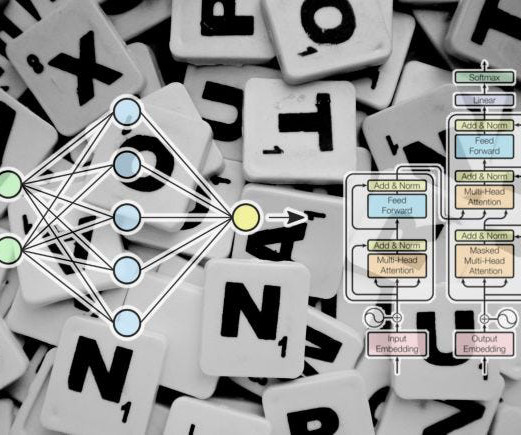
LLM watermarking, which integrates imperceptible yet detectable signals within model outputs to identify text generated by LLMs, is vital for preventing the misuse of large language models. Conversely, the Christ Family alters the sampling process during LLM text generation, embedding a watermark by changing how tokens are selected.









































Let's personalize your content