This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
How Hugging Face Facilitates NLP and LLM Projects Hugging Face has made working with LLMs simpler by offering: A range of pre-trained models to choose from. A great resource available through Hugging Face is the Open LLM Leaderboard. Tools and examples to fine-tune these models to your specific needs.
Experiments proceed iteratively, with results categorized as improvements, maintenance, or declines. to close the gap between BERT-base and BERT-large performance. It automatically generates and debugs code using an exception-traceback-guided process. improvement over baseline models. Dont Forget to join our 65k+ ML SubReddit.
LLM watermarking, which integrates imperceptible yet detectable signals within model outputs to identify text generated by LLMs, is vital for preventing the misuse of large language models. Conversely, the Christ Family alters the sampling process during LLM text generation, embedding a watermark by changing how tokens are selected.
We want to aggregate it, link it, filter it, categorize it, generate it and correct it. I don’t want to undersell how impactful LLMs are for this sort of use-case. You can give an LLM a group of comments and ask it to summarize the texts or identify key themes. You can’t pass that straight into an LLM — it’s much too expensive.
Named Entity Recognition ( NER) Named entity recognition (NER), an NLP technique, identifies and categorizes key information in text. Source: A pipeline on Generative AI This figure of a generative AI pipeline illustrates the applicability of models such as BERT, GPT, and OPT in data extraction.
In this world of complex terminologies, someone who wants to explain Large Language Models (LLMs) to some non-tech guy is a difficult task. So that’s why I tried in this article to explain LLM in simple or to say general language. No training examples are needed in LLM Development but it’s needed in Traditional Development.
Therefore, text-to-SQL research can benefit from the unique opportunities, enhancements, and solutions that can be brought about by integrating LLM-based implementation, such as improved query accuracy, better handling of complex queries, and increased system robustness. Join our Telegram Channel and LinkedIn Gr oup.
Generative AI Types: Text to Text, Text to Image Transformers & LLM The paper “ Attention Is All You Need ” by Google Brain marked a shift in the way we think about text modeling. Large Language Models (LLMs) like GPT-4, Bard, and LLaMA, are colossal constructs designed to decipher and generate human language, code, and more.
More recent methods based on pre-trained language models like BERT obtain much better context-aware embeddings. Existing methods predominantly use smaller BERT-style architectures as the backbone model. They are unable to take advantage of more advanced LLMs and related techniques. Adding it provided negligible improvements.
Tools like LangChain , combined with a large language model (LLM) powered by Amazon Bedrock or Amazon SageMaker JumpStart , simplify the implementation process. Types of summarizations There are several techniques to summarize text, which are broadly categorized into two main approaches: extractive and abstractive summarization.
A specific kind of foundation model known as a large language model (LLM) is trained on vast amounts of text data for NLP tasks. BERT (Bi-directional Encoder Representations from Transformers) is one of the earliest LLM foundation models developed. An open-source model, Google created BERT in 2018.
Large Language Models (LLMs) have revolutionized natural language processing in recent years. The pre-train and fine-tune paradigm, exemplified by models like ELMo and BERT, has evolved into prompt-based reasoning used by the GPT family. SMs play a crucial role in enhancing LLMs through data curation.
Manually analyzing and categorizing large volumes of unstructured data, such as reviews, comments, and emails, is a time-consuming process prone to inconsistencies and subjectivity. The raw data is processed by an LLM using a preconfigured user prompt. The LLM generates output based on the user prompt.
While large language models (LLMs) have claimed the spotlight since the debut of ChatGPT, BERT language models have quietly handled most enterprise natural language tasks in production. As foundation models , large LLMs like GPT-4 and Gemini consolidate internet-scale text datasets and excel at a wide range of tasks.
The development of Large Language Models (LLMs), such as GPT and BERT, represents a remarkable leap in computational linguistics. Meet ‘Unicron,’ a novel system that Alibaba Group and Nanjing University researchers developed to enhance and streamline the LLM training process.
AWS received about 100 samples of labeled data from the customer, which is a lot less than the 1,000 samples recommended for fine-tuning an LLM in the data science community. The solution was to find and fine-tune an LLM to classify toxic language. LLMs are truly capable of learning from internet-scale data.
Natural language processing (NLP) activities, including speech-to-text, sentiment analysis, text summarization, spell-checking, token categorization, etc., Applications of LLMs The chart below summarises the present state of the Large Language Model (LLM) landscape in terms of features, products, and supporting software.
The primary issue lies in the substantial computational costs of LLM-based augmentation, resulting in high power consumption and CO2 emissions. Researchers need help with the need to balance the improved performance of LLM-augmented classifiers against their environmental and economic costs. and Llama-3-8B.
Systems like ChatGPT by OpenAI, BERT, and T5 have enabled breakthroughs in human-AI communication. link] The process can be categorized into three agents: Execution Agent : The heart of the system, this agent leverages OpenAI’s API for task processing.
TL;DR Hallucinations are an inherent feature of LLMs that becomes a bug in LLM-based applications. This “making up” event is what we call a hallucination, a term popularized by Andrej Karpathy in 2015 in the context of RNNs and extensively used nowadays for large language models (LLMs). What are LLM hallucinations?
We showcase two different sentence transformers, paraphrase-MiniLM-L6-v2 and a proprietary Amazon large language model (LLM) called M5_ASIN_SMALL_V2.0 , and compare their results. M5 LLMS are BERT-based LLMs fine-tuned on internal Amazon product catalog data using product title, bullet points, description, and more.
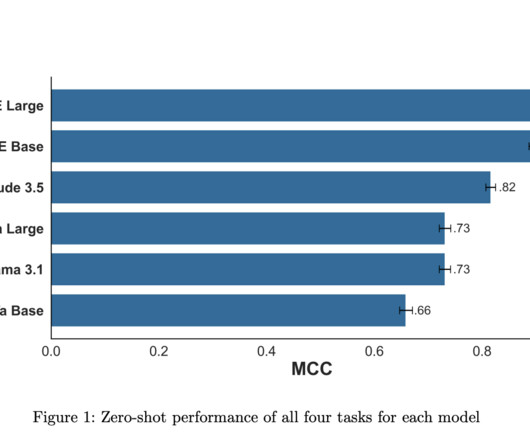
NLI models offer significant advantages in terms of efficiency, as they can operate with much smaller parameter counts compared to generative LLMs. For instance, a BERT model with 86 million parameters can perform NLI tasks, while the smallest effective zero-shot generative LLMs require 7-8 billion parameters. Also, Claude 3.5
It uses BERT, a popular NLP technique, to understand the meaning and context of words in the candidate summary and reference summary. The more similar the words and meanings captured by BERT, the higher the BERTScore. It uses neural networks like BERT to measure semantic similarity beyond just exact word or phrase matching.
Combined with large language models (LLM) and Contrastive Language-Image Pre-Training (CLIP) trained with a large quantity of multimodality data, visual language models (VLMs) are particularly adept at tasks like image captioning, object detection and segmentation, and visual question answering.
By extracting information, identifying patterns, and categorizing content within minutes, these tools enhance efficiency for legal professionals. By creating custom LLM-based applications using clients’ proprietary legal data, ZBrain optimizes legal research workflows, ensuring operational efficiency and delivering improved legal insights.
Its categorical power is brittle. Even if the total text length fits within the context window, users may want to avoid in-context learning for tasks with high cardinality; when using LLM APIs, users pay by the token. Sends the prompt to the LLM. Over thousands of executions, those extra tokens can add up.
Its categorical power is brittle. Even if the total text length fits within the context window, users may want to avoid in-context learning for tasks with high cardinality; when using LLM APIs, users pay by the token. Sends the prompt to the LLM. Over thousands of executions, those extra tokens can add up.
Its categorical power is brittle. Even if the total text length fits within the context window, users may want to avoid in-context learning for tasks with high cardinality; when using LLM APIs, users pay by the token. Sends the prompt to the LLM. Over thousands of executions, those extra tokens can add up.
At inference time, users provide “prompts” to the LLM—snippets of text that the model uses as a jumping-off point. BERT, the first breakout large language model In 2019, a team of researchers at Goole introduced BERT (which stands for bidirectional encoder representations from transformers). The new tool caused a stir.
At inference time, users provide “prompts” to the LLM—snippets of text that the model uses as a jumping-off point. BERT, the first breakout large language model In 2019, a team of researchers at Goole introduced BERT (which stands for bidirectional encoder representations from transformers). The new tool caused a stir.
It also serves as a powerful lever for refining the abilities of LLMs. Famous models like BERT and others, begin their journey with initial training on massive datasets encompassing vast swaths of internet text. So as you can see above in the picture the taxonomy can be broadly categorized into: 1.
BERTBERT, an acronym that stands for “Bidirectional Encoder Representations from Transformers,” was one of the first foundation models and pre-dated the term by several years. BERT proved useful in several ways, including quantifying sentiment and predicting the words likely to follow in unfinished sentences.
If a computer program is trained on enough data such that it can analyze, understand, and generate responses in natural language and other forms of content, it is called a Large Language Model (LLM). An easy way to describe LLM is an AI algorithm capable of understanding and generating human language.
How to use the LangTest library to evaluate LLM for bias using CrowS-Pairs dataset? report() Output of the.report() In this snippet, we defined the task as crows-pairs , the model as bert-base-uncased from huggingface , and the data as CrowS-Pairs. We can check the detailed results using .generated_results()
Like other large language models, including BERT and GPT-3, LaMDA is trained on terabytes of text data to learn how words relate to one another and then predict what words are likely to come next. The second pre-training stage performs vision-to-language generative learning by connecting the output of the Q-Former to a frozen LLM.
Here are a few examples across various domains: Natural Language Processing (NLP) : Predictive NLP models can categorize text into predefined classes (e.g., For example, large language models (LLMs) are trained by randomly replacing some of the tokens in training data with a special token, such as [MASK].
AI is accelerating complaint resolution for banks AI can help banks automate many of the tasks involved in complaint handling, such as: Identifying, categorizing, and prioritizing complaints. For businesses to get the greatest value out of an LLM, they need to customize it with their proprietary data—something Snorkel can help with.
AI is accelerating complaint resolution for banks AI can help banks automate many of the tasks involved in complaint handling, such as: Identifying, categorizing, and prioritizing complaints. For businesses to get the greatest value out of an LLM, they need to customize it with their proprietary data—something Snorkel can help with.
AI is accelerating complaint resolution for banks AI can help banks automate many of the tasks involved in complaint handling, such as: Identifying, categorizing, and prioritizing complaints. For businesses to get the greatest value out of an LLM, they need to customize it with their proprietary data—something Snorkel can help with.
AI is accelerating complaint resolution for banks AI can help banks automate many of the tasks involved in complaint handling, such as: Identifying, categorizing, and prioritizing complaints. For businesses to get the greatest value out of an LLM, they need to customize it with their proprietary data—something Snorkel can help with.
Specifically, our aim is to facilitate standardized categorization for enhanced medical data analysis and interpretation. Spark NLP & LLM The Healthcare Library is a powerful component of John Snow Labs’ Spark NLP platform, designed to facilitate NLP tasks within the healthcare domain. In the latest release, v5.3.0,
Spark NLP & LLM The Healthcare Library is a powerful component of John Snow Labs’ Spark NLP platform, designed to facilitate NLP tasks within the healthcare domain. When applied to new unlabeled files, the models can categorize them at high accuracy. setInputCol("text").setOutputCol("document")
RWKV (pronounced as RWaKuV) is an RNN with GPT-level LLM performance, which can also be directly trained like a GPT transformer (parallelizable). Despite extensive research on traditional machine learning models, there has been limited work studying MIA on the pre-training data of large language models (LLMs). Reference-based ( ref ).
Case study: Creating an LLM-based application using LLM-based tools To best illustrate how LLM-based tools can be used, let me use a real-life example. We tried Vectara, an LLM-based platform for search. BERT), GPT is a generative model. Step 5: LLM customization 5.1. But why settle on GPT?
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content