This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
They serve as a core building block in many natural language processing (NLP) applications today, including information retrieval, question answering, semantic search and more. vector embedding Recent advances in largelanguagemodels (LLMs) like GPT-3 have shown impressive capabilities in few-shot learning and natural language generation.
These are deep learning models used in NLP. This discovery fueled the development of largelanguagemodels like ChatGPT. Largelanguagemodels or LLMs are AI systems that use transformers to understand and create human-like text.
In this world of complex terminologies, someone who wants to explain LargeLanguageModels (LLMs) to some non-tech guy is a difficult task. So that’s why I tried in this article to explain LLM in simple or to say general language. A transformer architecture is typically implemented as a Largelanguagemodel.
Computer programs called largelanguagemodels provide software with novel options for analyzing and creating text. It is not uncommon for largelanguagemodels to be trained using petabytes or more of text data, making them tens of terabytes in size. rely on LanguageModels as their foundation.
This article explores an innovative way to streamline the estimation of Scope 3 GHG emissions leveraging AI and LargeLanguageModels (LLMs) to help categorize financial transaction data to align with spend-based emissions factors. Why are Scope 3 emissions difficult to calculate?
Counselling session by a therapist In our work on medical diagnosis, we have focused on identifying conditions such as depression and anxiety for suicide risk detection using largelanguagemodels (LLMs). Dunns wellness model as a base for our MULTIWD dataset. What are wellness dimensions?
This interdisciplinary field incorporates linguistics, computer science, and mathematics, facilitating automatic translation, text categorization, and sentiment analysis. In sequential single interaction, retrievers identify relevant documents, which the languagemodel then uses to predict the output.
Overview: How Lumi uses machine learning for intelligent credit decisions As part of Lumis customer onboarding and loan application process, Lumi needed a robust solution for processing large volumes of business transaction data. They fine-tuned this model using their proprietary dataset and in-house data science expertise.
Named Entity Recognition ( NER) Named entity recognition (NER), an NLP technique, identifies and categorizes key information in text. Unlocking Unstructured Data with LLMs Leveraging largelanguagemodels (LLMs) for unstructured data extraction is a compelling solution with distinct advantages that address critical challenges.
Experiments proceed iteratively, with results categorized as improvements, maintenance, or declines. improvement over baseline models. to close the gap between BERT-base and BERT-large performance. It automatically generates and debugs code using an exception-traceback-guided process.
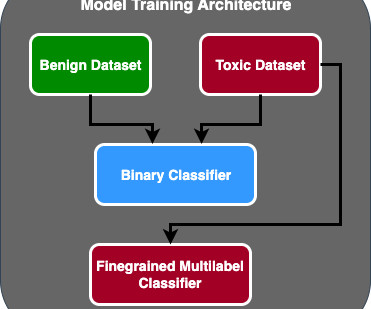
Part 2 will delve into the productionized solution, explaining the design decisions, data flow, and illustration of the model training and deployment architecture. Thus the basis of the transformer model was born. Later versions of the GPT model, namely GPT3 and GPT4, are the engine that powers the ChatGPT application.
Pre-trained languagemodels have received more consideration in recent studies as a result of their outstanding performance in the general natural language domain. In the general language domain, there are two main branches of pre-trained languagemodels: BERT (and its variants) and GPT (and its variants).
These advanced AI deep learning models have seamlessly integrated into various applications, from Google's search engine enhancements with BERT to GitHub’s Copilot, which harnesses the capability of LargeLanguageModels (LLMs) to convert simple code snippets into fully functional source codes.
What are LargeLanguageModels (LLMs)? In generative AI, human language is perceived as a difficult data type. If a computer program is trained on enough data such that it can analyze, understand, and generate responses in natural language and other forms of content, it is called a LargeLanguageModel (LLM).
Since the public unveiling of ChatGPT, largelanguagemodels (or LLMs) have had a cultural moment. But what are largelanguagemodels? Table of contents What are largelanguagemodels (LLMs)? Their new model combined several ideas into something surprisingly simple and powerful.
Since the public unveiling of ChatGPT, largelanguagemodels (or LLMs) have had a cultural moment. But what are largelanguagemodels? Table of contents What are largelanguagemodels (LLMs)? Their new model combined several ideas into something surprisingly simple and powerful.
Tools like LangChain , combined with a largelanguagemodel (LLM) powered by Amazon Bedrock or Amazon SageMaker JumpStart , simplify the implementation process. Types of summarizations There are several techniques to summarize text, which are broadly categorized into two main approaches: extractive and abstractive summarization.
Transformers and Advanced NLP Models : The introduction of transformer architectures revolutionized the NLP landscape. Systems like ChatGPT by OpenAI, BERT, and T5 have enabled breakthroughs in human-AI communication. The diagram visualizes the architecture of an AI system powered by a LargeLanguageModel and Agents.
For example, a foundation model might be used as the basis for a generative AI model that is then fine-tuned with additional manufacturing datasets to assist in the discovery of safer and faster ways to manufacturer a type of product. An open-source model, Google created BERT in 2018.
LLM watermarking, which integrates imperceptible yet detectable signals within model outputs to identify text generated by LLMs, is vital for preventing the misuse of largelanguagemodels. These watermarking techniques are mainly divided into two categories: the KGW Family and the Christ Family. So let’s get started.
While largelanguagemodels (LLMs) have claimed the spotlight since the debut of ChatGPT, BERTlanguagemodels have quietly handled most enterprise natural language tasks in production. While the performance of these models is impressive, so too are their computational costs.
In this article, we will delve into the latest advancements in the world of large-scale languagemodels, exploring enhancements introduced by each model, their capabilities, and potential applications. The Most Important LargeLanguageModels (LLMs) in 2023 1. billion word corpus).
The development of LargeLanguageModels (LLMs), such as GPT and BERT, represents a remarkable leap in computational linguistics. Training these models, however, is challenging. The system’s error detection mechanism is designed to identify and categorize failures during execution promptly.
LargeLanguageModels (LLMs) have revolutionized natural language processing in recent years. The pre-train and fine-tune paradigm, exemplified by models like ELMo and BERT, has evolved into prompt-based reasoning used by the GPT family. KD methods can be categorized into white-box and black-box approaches.
While earlier surveys predominantly centred on encoder-based models such as BERT, the emergence of decoder-only Transformers spurred advancements in analyzing these potent generative models. Existing surveys detail a range of techniques utilized in Explainable AI analyses and their applications within NLP.
We showcase two different sentence transformers, paraphrase-MiniLM-L6-v2 and a proprietary Amazon largelanguagemodel (LLM) called M5_ASIN_SMALL_V2.0 , and compare their results. M5 LLMS are BERT-based LLMs fine-tuned on internal Amazon product catalog data using product title, bullet points, description, and more.
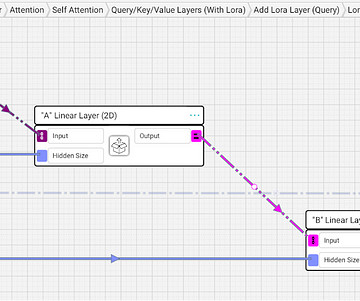
Visualized Implementation of LoRA Fine-tuning, which is the learning or updating of weights in a transformer model, can be the delta between a model that’s not ready for production to one that is robust enough to put in front of customers. BERT LoRA First, I’ll show LoRA in the BERT implementation, and then I’ll do the same for GPT.
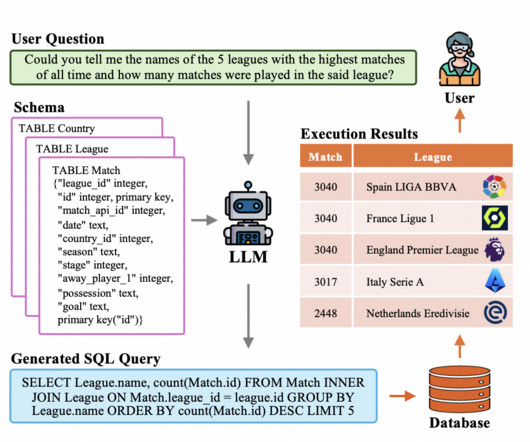
Methodology Based on Pre-Trained LanguageModels (PLMs): Text-to-SQL jobs were optimized using the semantic knowledge of pre-trained languagemodels (PLMs) such as BERT and RoBERTa. To provide more precise SQL queries, schema-aware PLMs integrated knowledge of database structures.
Manually analyzing and categorizinglarge volumes of unstructured data, such as reviews, comments, and emails, is a time-consuming process prone to inconsistencies and subjectivity. Largelanguagemodels (LLMs) have transformed the way we engage with and process natural language. No explanation is required.
In modern machine learning and artificial intelligence frameworks, transformers are one of the most widely used components across various domains including GPT series, and BERT in Natural Language Processing, and Vision Transformers in computer vision tasks.
Infini-gram achieves millisecond-level query processing, demonstrating that classical statistical languagemodeling approaches remain relevant and they are complementary to neural methods in the era of largelanguagemodels(LLMs). tokens), Pile (380B tokens), and C4 (200B tokens).
So, fine-tuning is a way that helps improve model performance by training on specific examples of prompts and desired responses. Famous models like BERT and others, begin their journey with initial training on massive datasets encompassing vast swaths of internet text. I really recommend going over the paper to learn more.
The previous year saw a significant increase in the amount of work that concentrated on Computer Vision (CV) and Natural Language Processing (NLP). Because of this, academics worldwide are looking at the potential benefits deep learning and largelanguagemodels (LLMs) might bring to audio generation.
The advent of largelanguagemodels (LLMs) like ChatGPT has revolutionized this field, enabling zero-shot classification without additional training. Consequently, there is a growing call for researchers to prioritize open-source models and provide strong justification when opting for closed systems.
Against this backdrop, researchers began using PLMs like BERT, which required less data and provided better predictive performance. Researchers from the National University of Singapore provided a comprehensive survey of the various languagemodeling techniques developed for tabular data.
Largelanguagemodels (LLMs) are best suited for abstractive summarization because the transformer models use attention mechanisms to focus on relevant parts of the input text when generating summaries. The more similar the words and meanings captured by BERT, the higher the BERTScore.
Researchers from the University of Melbourne introduced a groundbreaking solution named MoDEM (Mixture of Domain Expert Models). This system comprises a lightweight BERT-based router categorizing incoming queries into predefined domains such as health, science, and coding. If you like our work, you will love our newsletter.
For example, some largelanguagemodels generate embedding values for words by showing the model a sentence with a missing word and asking the model to predict the missing word. Some image models use a similar approach, masking a portion of the image and then asking the model to predict what exists within the mask.
LargeLanguageModels (LLMs) like GPT-4, Gemini, and Llama have revolutionized textual dataset augmentation, offering new possibilities for enhancing small downstream classifiers. However, this approach faces significant challenges. and Llama-3-8B.
Generated with Bing and edited with Photoshop Predictive AI has been driving companies’ ROI for decades through advanced recommendation algorithms, risk assessment models, and fraud detection tools. spam vs. not spam), while generative NLP models can create new text based on a given prompt (e.g.,
If you’d like to skip around, here are the languagemodels we featured: GPT-3 by OpenAI LaMDA by Google PaLM by Google Flamingo by DeepMind BLIP-2 by Salesforce LLaMA by Meta AI GPT-4 by OpenAI If this in-depth educational content is useful for you, you can subscribe to our AI research mailing list to be alerted when we release new material.
While Snorkel has worked with partners to build valuable applications using image and cross-modal genAI models, this post will focus exclusively on largelanguagemodels. Its categorical power is brittle. After this training, the model achieved an accuracy of 78%. BERT for misinformation.
While Snorkel has worked with partners to build valuable applications using image and cross-modal genAI models, this post will focus exclusively on largelanguagemodels. Its categorical power is brittle. After this training, the model achieved an accuracy of 78%. BERT for misinformation.
While Snorkel has worked with partners to build valuable applications using image and cross-modal genAI models, this post will focus exclusively on largelanguagemodels. Its categorical power is brittle. After this training, the model achieved an accuracy of 78%. BERT for misinformation.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content