This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
One-hot encoding is a process by which categorical variables are converted into a binary vector representation where only one bit is “hot” (set to 1) while all others are “cold” (set to 0). It results in sparse and high-dimensional vectors that do not capture any semantic or syntactic information about the words.
Going anonymous for self-expression has bundled these forums with information that is quite useful for mental health studies. This panel has designed the guidelines for annotating the wellness dimensions and categorized the posts into the six wellness dimensions based on the sensitive content of each post. What are wellness dimensions?
This article explores an innovative way to streamline the estimation of Scope 3 GHG emissions leveraging AI and Large Language Models (LLMs) to help categorize financial transaction data to align with spend-based emissions factors. Why are Scope 3 emissions difficult to calculate?
This method involves hand-keying information directly into the target system. But these solutions cannot guarantee 100% accurate results. Text Pattern Matching Text pattern matching is a method for identifying and extracting specific information from text using predefined rules or patterns.
This interdisciplinary field incorporates linguistics, computer science, and mathematics, facilitating automatic translation, text categorization, and sentiment analysis. RALMs’ language models are categorized into autoencoder, autoregressive, and encoder-decoder models.
Blockchain technology can be categorized primarily on the basis of the level of accessibility and control they offer, with Public, Private, and Federated being the three main types of blockchain technologies. Ethereum is a decentralized blockchain platform that upholds a shared ledger of information collaboratively using multiple nodes.
A foundation model is built on a neural network model architecture to process information much like the human brain does. BERT (Bi-directional Encoder Representations from Transformers) is one of the earliest LLM foundation models developed. An open-source model, Google created BERT in 2018.
They serve as a core building block in many natural language processing (NLP) applications today, including information retrieval, question answering, semantic search and more. More recent methods based on pre-trained language models like BERT obtain much better context-aware embeddings. Adding it provided negligible improvements.
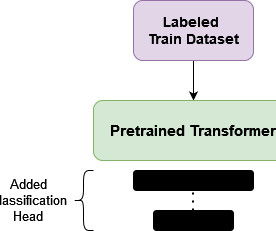
In the case of BERT (Bidirectional Encoder Representations from Transformers), learning involves predicting randomly masked words (bidirectional) and sentence-order prediction. For concreteness, we will use BERT as the base model and set the number of classification labels to 4.
While earlier surveys predominantly centred on encoder-based models such as BERT, the emergence of decoder-only Transformers spurred advancements in analyzing these potent generative models. They explore methods to decode information in neural network models, especially in natural language processing.
Manually analyzing and categorizing large volumes of unstructured data, such as reviews, comments, and emails, is a time-consuming process prone to inconsistencies and subjectivity. For more information, see Customize models in Amazon Bedrock with your own data using fine-tuning and continued pre-training. No explanation is required.
Natural language processing (NLP) activities, including speech-to-text, sentiment analysis, text summarization, spell-checking, token categorization, etc., Personal decision making With the aid of Oogway, people can better arrange their options and make informed judgments. rely on Language Models as their foundation.
Systems like ChatGPT by OpenAI, BERT, and T5 have enabled breakthroughs in human-AI communication. Outputs : Once processed, the information is transformed into a user-friendly format and then relayed to devices that can act upon or influence the external surroundings. BabyAGI Then, there's BabyAGI , a simplified yet powerful agent.
Huge transformer models like BERT, GPT-2 and XLNet have set a new standard for accuracy on almost every NLP leaderboard. In a recent talk at Google Berlin, Jacob Devlin described how Google are using his BERT architectures internally. In this post we introduce our new wrapping library, spacy-transformers.
Introduction In natural language processing, text categorization tasks are common (NLP). transformer.ipynb” uses the BERT architecture to classify the behaviour type for a conversation uttered by therapist and client, i.e, The fourth model which is also used for multi-class classification is built using the famous BERT architecture.
In addition to textual inputs, this model uses traditional structured data inputs such as numerical and categorical fields. This post aims to build a model that can process and relate information from multiple modalities such as tabular and textual features. The solution outlined in the post is available on GitHub. Fraud detection.
The development of Large Language Models (LLMs), such as GPT and BERT, represents a remarkable leap in computational linguistics. The system’s error detection mechanism is designed to identify and categorize failures during execution promptly. Training these models, however, is challenging.
In modern machine learning and artificial intelligence frameworks, transformers are one of the most widely used components across various domains including GPT series, and BERT in Natural Language Processing, and Vision Transformers in computer vision tasks. Due to its causal nature, this method is suited for autoregressive generation tasks.
These embeddings are useful for various natural language processing (NLP) tasks such as text classification, clustering, semantic search, and information retrieval. M5 LLMS are BERT-based LLMs fine-tuned on internal Amazon product catalog data using product title, bullet points, description, and more. str.split("|").str[0]
Organizations across industries are using automatic text summarization to more efficiently handle vast amounts of information and make better decisions. This leads to better comprehension and retention of critical information. The system selects parts of the text deemed most informative or representative of the whole.
The KGW Family modifies the logits produced by the LLM to create watermarked output by categorizing the vocabulary into a green list and a red list based on the preceding token. These watermarking techniques are mainly divided into two categories: the KGW Family and the Christ Family.
One of the advantages of this model is that it can generate answers in diverse styles: formal, informal, and humorous. There are several types of Question Answering tasks, such as factoid QA, where the answer is a short fact or a piece of information, and non-factoid QA, where the answer is an opinion or a longer explanation.
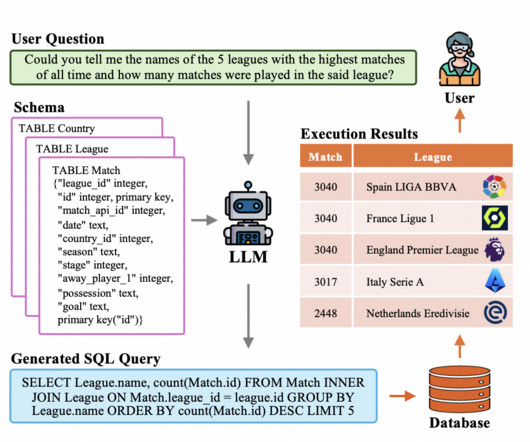
The third step uses the parsing information to build SQL queries that may retrieve the desired answer by predicting the correct syntax. Methodology Based on Pre-Trained Language Models (PLMs): Text-to-SQL jobs were optimized using the semantic knowledge of pre-trained language models (PLMs) such as BERT and RoBERTa.
Legal professionals now leverage powerful AI tools with sophisticated algorithms for more efficient and precise processing of vast information repositories. By extracting information, identifying patterns, and categorizing content within minutes, these tools enhance efficiency for legal professionals.
We’ll start with a seminal BERT model from 2018 and finish with this year’s latest breakthroughs like LLaMA by Meta AI and GPT-4 by OpenAI. BERT by Google Summary In 2018, the Google AI team introduced a new cutting-edge model for Natural Language Processing (NLP) – BERT , or B idirectional E ncoder R epresentations from T ransformers.
BERTBERT, an acronym that stands for “Bidirectional Encoder Representations from Transformers,” was one of the first foundation models and pre-dated the term by several years. BERT proved useful in several ways, including quantifying sentiment and predicting the words likely to follow in unfinished sentences.
Be sure to check out his talk, “ Bagging to BERT — A Tour of Applied NLP ,” there! Each has a single representation for the word “well”, which combines the information for “doing well” with “wishing well”. cats” component of Docs, for which we’ll be training a text categorization model to classify sentiment as “positive” or “negative.”
Against this backdrop, researchers began using PLMs like BERT, which required less data and provided better predictive performance. The methodology proposed by the research team categorizes tabular data into two major categories: 1D and 2D.
In this article, we will explore about ALBERT ( A lite weighted version of BERT machine learning model) What is ALBERT? ALBERT (A Lite BERT) is a language model developed by Google Research in 2019. BERT, GPT-2, and XLNet are some examples of models that can be used as teacher models for ALBERT.
This allows GuardDuty to categorize previously unseen domains as highly likely to be malicious or benign based on their association to known malicious domains. The Jupyter notebook also generates BERT embeddings on the entities with text data, such as papers. Check out our GitHub repository for more information.
Here are a few examples across various domains: Natural Language Processing (NLP) : Predictive NLP models can categorize text into predefined classes (e.g., Masking in BERT architecture ( illustration by Misha Laskin ) Another common type of generative AI model are diffusion models for image and video generation and editing.
To make an informed decision, prioritize your primary constraint: model size, data size, inference speed , or accuracy. Text Classification: Categorize text into predefined groups for content moderation and tone detection. Natural Language Question Answering : Use BERT to answer questions based on text passages.
BERT, the first breakout large language model In 2019, a team of researchers at Goole introduced BERT (which stands for bidirectional encoder representations from transformers). By making BERT bidirectional, it allowed the inputs and outputs to take each others’ context into account. BERT), or consist of both (e.g.,
BERT, the first breakout large language model In 2019, a team of researchers at Goole introduced BERT (which stands for bidirectional encoder representations from transformers). By making BERT bidirectional, it allowed the inputs and outputs to take each others’ context into account. BERT), or consist of both (e.g.,
report() Output of the.report() In this snippet, we defined the task as crows-pairs , the model as bert-base-uncased from huggingface , and the data as CrowS-Pairs. Output of the.generated_results() We can continue with this dataframe with our own methods, we can categorize by bias-type or even do more filtration for the probabilities.
In the same way that BERT or GPT-3 models provide general-purpose initialization for NLP, large RL–pre-trained models could provide general-purpose initialization for decision-making. Our shared vision backbone also utilized a learned position embedding (akin to Transformer models) to keep track of spatial information in the game.
The ability to precisely comprehend the intricate details documented in clinical reports is essential for informing subsequent treatment decisions, adjusting therapeutic strategies, and ultimately improving patient outcomes. This allows systems to pinpoint key information pertaining to the patient’s condition, treatment regimen, and outcomes.
They can write poems, recite common knowledge, and extract information from submitted text. Its categorical power is brittle. BERT for misinformation. Researchers using a BERT derivative—a non-generative LLM— achieved 91% accuracy in predicting COVID misinformation. A GPT-3 model—82.5%
They can write poems, recite common knowledge, and extract information from submitted text. Its categorical power is brittle. BERT for misinformation. Researchers using a BERT derivative—a non-generative LLM— achieved 91% accuracy in predicting COVID misinformation. A GPT-3 model—82.5%
They can write poems, recite common knowledge, and extract information from submitted text. Its categorical power is brittle. BERT for misinformation. Researchers using a BERT derivative—a non-generative LLM— achieved 91% accuracy in predicting COVID misinformation. A GPT-3 model—82.5%
For example, you’ll be able to use the information that certain spans of text are definitely not PERSON entities, without having to provide the complete gold-standard annotations for the given example. spacy-dbpedia-spotlight Use DBpedia Spotlight to link entities ✍️ contextualSpellCheck Contextual spell correction using BERT ?
Effective mitigation strategies involve enhancing data quality, alignment, information retrieval methods, and prompt engineering. The interactions between the Query, Key, and Value matrices determine which information is emphasized or prioritized and will carry more weight in the final prediction. In 2022, when GPT-3.5
This information is invaluable for product development and innovation. Cleaning and standardising the data, including removing irrelevant information (e.g., This involves three phases: aspect detection, sentiment categorization, and aggregation of results. HTML tags, special characters). Word2Vec, GloVe).
Specifically, our aim is to facilitate standardized categorization for enhanced medical data analysis and interpretation. This library provides over 2,200 pre-trained models and pipelines tailored for medical data, enabling accurate information extraction, NER for clinical and medical concepts, and text analysis capabilities.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























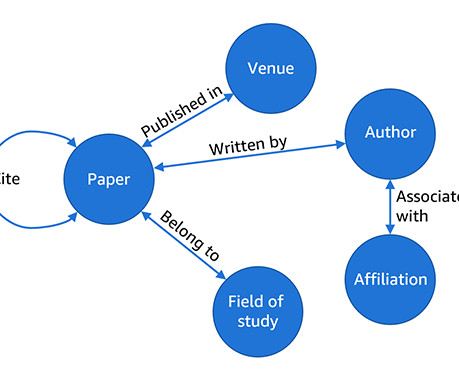





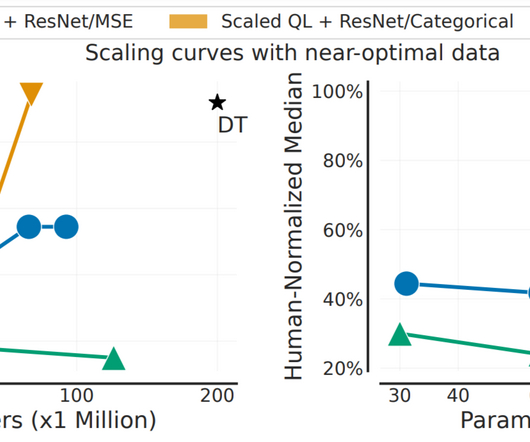














Let's personalize your content