This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
True to their name, generativeAI models generate text, images, code , or other responses based on a user’s prompt. But what makes the generative functionality of these models—and, ultimately, their benefits to the organization—possible? An open-source model, Google created BERT in 2018.
This advancement has spurred the commercial use of generativeAI in natural language processing (NLP) and computer vision, enabling automated and intelligent data extraction. Named Entity Recognition ( NER) Named entity recognition (NER), an NLP technique, identifies and categorizes key information in text.
It needed to intelligently categorize transactions based on their descriptions and other contextual factors about the business to ensure they are mapped to the appropriate classification. Conclusion By implementing SageMaker AI, Lumi has achieved significant improvements to their business. Follow him on LinkedIn.
While large language models (LLMs) have claimed the spotlight since the debut of ChatGPT, BERT language models have quietly handled most enterprise natural language tasks in production. Additionally, while the data and code needed to train some of the latest generation of models is still closed-source, open source variants of BERT abound.
Manually analyzing and categorizing large volumes of unstructured data, such as reviews, comments, and emails, is a time-consuming process prone to inconsistencies and subjectivity. With Amazon Bedrock, developers can experiment, evaluate, and deploy generativeAI applications without worrying about infrastructure management.
Systems like ChatGPT by OpenAI, BERT, and T5 have enabled breakthroughs in human-AI communication. Current Landscape of AI Agents AI agents, including Auto-GPT, AgentGPT, and BabyAGI, are heralding a new era in the expansive AI universe.
So that’s why I tried in this article to explain LLM in simple or to say general language. Machine translation, summarization, ticket categorization, and spell-checking are among the examples. BERT (Bidirectional Encoder Representations from Transformers) — developed by Google.
M5 LLMS are BERT-based LLMs fine-tuned on internal Amazon product catalog data using product title, bullet points, description, and more. Fine-tune the sentence transformer M5_ASIN_SMALL_V20 Now we create a sentence transformer from a BERT-based model called M5_ASIN_SMALL_V2.0. str.split("|").str[0] All other code remains the same.
Generated with Bing and edited with Photoshop Predictive AI has been driving companies’ ROI for decades through advanced recommendation algorithms, risk assessment models, and fraud detection tools. However, the recent surge in generativeAI has made it the new hot topic. a social media post or product description).
Its categorical power is brittle. The main challenges of deploying genAI for predictive into production Given the relative ease of building predictive pipelines using generativeAI, it might be tempting to set one up for large-scale use. BERT for misinformation. The largest version of BERT contains 340 million parameters.
Its categorical power is brittle. Why you should not deploy genAI for predictive into production Given the relative ease of building predictive pipelines using generativeAI, it might be tempting to set one up for large-scale use. BERT for misinformation. The largest version of BERT contains 340 million parameters.
Its categorical power is brittle. Why you should not deploy genAI for predictive into production Given the relative ease of building predictive pipelines using generativeAI, it might be tempting to set one up for large-scale use. BERT for misinformation. The largest version of BERT contains 340 million parameters.
We’ll start with a seminal BERT model from 2018 and finish with this year’s latest breakthroughs like LLaMA by Meta AI and GPT-4 by OpenAI. BERT by Google Summary In 2018, the Google AI team introduced a new cutting-edge model for Natural Language Processing (NLP) – BERT , or B idirectional E ncoder R epresentations from T ransformers.
Automated document analysis AI tools designed for law firms use advanced technologies like NLP and machine learning to analyze extensive legal documents swiftly. By extracting information, identifying patterns, and categorizing content within minutes, these tools enhance efficiency for legal professionals.
music-text pairs annotated with detailed human-generated descriptions. MusicLM is specifically trained on SoundStream, w2v-BERT, and MuLan pre-trained modules. This includes 78,366 categorized sound events across 44 categories and 39,187 non-categorized sound events. MusicCaps is a publicly available dataset with 5.5k
It uses BERT, a popular NLP technique, to understand the meaning and context of words in the candidate summary and reference summary. The more similar the words and meanings captured by BERT, the higher the BERTScore. It uses neural networks like BERT to measure semantic similarity beyond just exact word or phrase matching.
How do foundation models generate responses? Foundation models underpin generativeAI capabilities, from text-generation to music creation to image generation. BERT proved useful in several ways, including quantifying sentiment and predicting the words likely to follow in unfinished sentences.
Complete training materials for FastText and Bert implementation accompany the dataset, with upcoming suggestions for data proportioning based on RegMix methodology. URL labeling utilizes GPT-4 to process the top million root URLs, categorizing them into Domain-of-Interest (DoI) and Domain-of-Non-Interest (DoNI) URLs.
In generativeAI, human language is perceived as a difficult data type. If a computer program is trained on enough data such that it can analyze, understand, and generate responses in natural language and other forms of content, it is called a Large Language Model (LLM). GPT-4, BERT) based on your specific task requirements.
AI is accelerating complaint resolution for banks AI can help banks automate many of the tasks involved in complaint handling, such as: Identifying, categorizing, and prioritizing complaints. Generating reports on complaint trends. Assigning complaints to staff. Tracking the status of complaints. Book a demo today.
AI is accelerating complaint resolution for banks AI can help banks automate many of the tasks involved in complaint handling, such as: Identifying, categorizing, and prioritizing complaints. Generating reports on complaint trends. Assigning complaints to staff. Tracking the status of complaints.
AI is accelerating complaint resolution for banks AI can help banks automate many of the tasks involved in complaint handling, such as: Identifying, categorizing, and prioritizing complaints. Generating reports on complaint trends. Assigning complaints to staff. Tracking the status of complaints.
AI is accelerating complaint resolution for banks AI can help banks automate many of the tasks involved in complaint handling, such as: Identifying, categorizing, and prioritizing complaints. Generating reports on complaint trends. Assigning complaints to staff. Tracking the status of complaints.
In November 2022, ChatGPT was released, a large language model (LLM) that used the transformer architecture, and is widely credited with starting the current generativeAI boom. Machine learning GenerativeAI is the most topical ML application at this point in time.
Despite Bard being often labeled as boring , it could be seen as evidence of Google’s commitment to prioritizing safety, even amidst the intense rivalry between Google and Microsoft to establish dominance in the field of generativeAI. Content generation for marketing, social media, or creative writing. What is the goal?
As we unpack the principles and practices of prompt engineering, you will learn how to utilize Langchain's powerful features to leverage the strengths of SOTA GenerativeAI models like GPT-4. LangChain categorizes its chains into three types: Utility chains, Generic chains, and Combine Documents chains.
In summary, EDS is a serious, practical issue affecting all areas of GenAI, most notably LLMs [10, 11], and image generation (GANs [12], Diffusion Models [13]). source: The Missing Link in GenerativeAI | Fiddler AI Blog ]. In this section, we’ll delve into the ‘hard’/technical factors behind EDS in GenerativeAI.
That is GenerativeAI. Generative models have blurred the line between humans and machines. With the advent of models like GPT-4, which employs transformer modules, we have stepped closer to natural and context-rich language generation. billion R&D budget to generativeAI, as indicated by CEO Tim Cook.
To install and import the library, use the following commands: pip install -q transformers from transformers import pipeline Having done that, you can execute NLP tasks starting with sentiment analysis, which categorizes text into positive or negative sentiments. We choose a BERT model fine-tuned on the SQuAD dataset.
Types of summarizations There are several techniques to summarize text, which are broadly categorized into two main approaches: extractive and abstractive summarization. In this post, we focus on the BERT extractive summarizer. It works by first embedding the sentences in the text using BERT.
AWS ProServe solved this use case through a joint effort between the GenerativeAI Innovation Center (GAIIC) and the ProServe ML Delivery Team (MLDT). For example, the original BERT model was pre-trained on the BookCorpus and entire English Wikipedia text datasets. Thus the basis of the transformer model was born.
Visual language processing (VLP) is at the forefront of generativeAI, driving advancements in multimodal learning that encompasses language intelligence, vision understanding, and processing. Solution overview The proposed VLP solution integrates a suite of state-of-the-art generativeAI modules to yield accurate multimodal outputs.
The first two can be categorized as inductive bias of humans and the last one is introducing compute over human element; which provides the following advantages: Unbiased Exploration: Evolutionary algorithms can systematically explore a vast space of potential model combinations, significantly exceeding human capabilities.
This is where LLMs can be beneficial by helping organize and categorize event data following a specific template, thereby aiding comprehension, and helping analysts quickly determine the appropriate next actions. It determines the similarity between the generated summary and the reference summary using cosine similarity.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















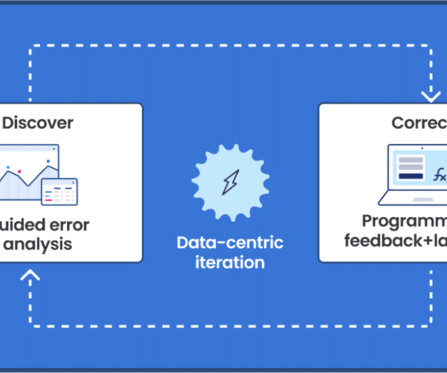
















Let's personalize your content