This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While large language models (LLMs) have claimed the spotlight since the debut of ChatGPT, BERT language models have quietly handled most enterprise natural language tasks in production. Additionally, while the data and code needed to train some of the latest generation of models is still closed-source, open source variants of BERT abound.
In addition to textual inputs, this model uses traditional structured data inputs such as numerical and categorical fields. We show you how to train, deploy and use a churn prediction model that has processed numerical, categorical, and textual features to make its prediction. BERT + Random Forest.
We’ll start with a seminal BERT model from 2018 and finish with this year’s latest breakthroughs like LLaMA by Meta AI and GPT-4 by OpenAI. BERT by Google Summary In 2018, the Google AI team introduced a new cutting-edge model for Natural Language Processing (NLP) – BERT , or B idirectional E ncoder R epresentations from T ransformers.
The KGW Family modifies the logits produced by the LLM to create watermarked output by categorizing the vocabulary into a green list and a red list based on the preceding token. Additionally, MARKLLM provides two types of automated demo pipelines, whose modules can be customized and assembled flexibly, allowing for easy configuration and use.
The DeepPavlov Library uses BERT base models to deal with Question Answering, such as RoBERTa. BERT is a pre-trained transformer-based deep learning model for natural language processing that achieved state-of-the-art results across a wide array of natural language processing tasks when this model was proposed.
Viso Suite is the End-to-End, No-Code Computer Vision Solution – Request a Demo. Text Classification: Categorize text into predefined groups for content moderation and tone detection. Natural Language Question Answering : Use BERT to answer questions based on text passages. What is Tensorflow Lite?
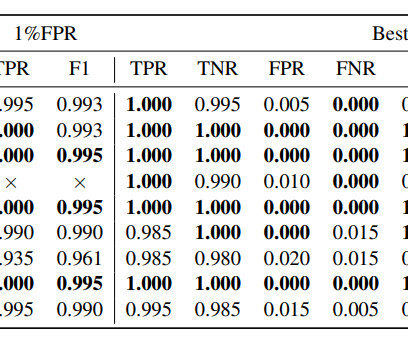
Its categorical power is brittle. BERT for misinformation. Researchers using a BERT derivative—a non-generative LLM— achieved 91% accuracy in predicting COVID misinformation. The largest version of BERT contains 340 million parameters. Book a demo today. After this training, the model achieved an accuracy of 78%.
Types of commonsense: Commonsense knowledge can be categorized according to types, including but not limited to: Social commonsense: people are capable of making inferences about other people's mental states, e.g. what motivates them, what they are likely to do next, etc. Using the AllenNLP demo. Check out our demo !
Specifically, our aim is to facilitate standardized categorization for enhanced medical data analysis and interpretation. After getting the appropriate entities, we feed these entity chunks to the Sentence BERT (SBERT) stage, which generates embeddings for each entity. In the latest release, v5.3.0, setOutputCol("mappings").setRels(["icd10_code"])
AI is accelerating complaint resolution for banks AI can help banks automate many of the tasks involved in complaint handling, such as: Identifying, categorizing, and prioritizing complaints. Book a demo today. Bank agents may also struggle to track the status of complaints and ensure that they are resolved in a timely manner.
John Snow Labs’ demo page provides a user-friendly interface for exploring the capabilities of the library, allowing users to interactively test and visualize various functionalities and models, facilitating a deeper understanding of how these tools can be applied to real-world scenarios in healthcare and other domains.
Book a demo to learn more. But, there are open source models like German-BERT that are already trained on huge data corpora, with many parameters. Through transfer learning, representation learning of German-BERT is utilized and additional subtitle data is provided. What is Transfer Learning? Let us understand how this works.
Learn more by booking a demo. Source ) This has led to groundbreaking models like GPT for generative tasks and BERT for understanding context in Natural Language Processing ( NLP ). Viso Suite: The only truly end-to-end computer vision solution, Viso Suite eliminates the need for point solutions.
This leap forward is due to the influence of foundation models in NLP, such as GPT and BERT. Segment Anything Model demo example, the detection is performed without the need to annotate images The SA-1B Dataset: A New Milestone in AI Training SAM’s true superpower is its training data, called the SA-1B Dataset.
Demos of GPT-4 will still require human cherry picking.” – Gary Marcus, CEO and founder of Robust.ai. Like other large language models, including BERT and GPT-3, LaMDA is trained on terabytes of text data to learn how words relate to one another and then predict what words are likely to come next. How is the problem approached?
Key strengths of VLP include the effective utilization of pre-trained VLMs and LLMs, enabling zero-shot or few-shot predictions without necessitating task-specific modifications, and categorizing images from a broad spectrum through casual multi-round dialogues. The demo implementation code is available in the following GitHub repo.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















Let's personalize your content