This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This panel has designed the guidelines for annotating the wellness dimensions and categorized the posts into the six wellness dimensions based on the sensitive content of each post. Using BERT and MentalBERT, we could capture these subtleties effectively by contextualizing each word based on the surrounding text.
Overview: How Lumi uses machine learning for intelligent credit decisions As part of Lumis customer onboarding and loan application process, Lumi needed a robust solution for processing large volumes of business transaction data. They fine-tuned this model using their proprietary dataset and in-house datascience expertise.
A specific kind of foundation model known as a large language model (LLM) is trained on vast amounts of text data for NLP tasks. BERT (Bi-directional Encoder Representations from Transformers) is one of the earliest LLM foundation models developed. An open-source model, Google created BERT in 2018.
While large language models (LLMs) have claimed the spotlight since the debut of ChatGPT, BERT language models have quietly handled most enterprise natural language tasks in production. Additionally, while the data and code needed to train some of the latest generation of models is still closed-source, open source variants of BERT abound.
Be sure to check out his talk, “ Bagging to BERT — A Tour of Applied NLP ,” there! cats” component of Docs, for which we’ll be training a text categorization model to classify sentiment as “positive” or “negative.” Since 2014, he has been working in datascience for government, academia, and the private sector.
Systems like ChatGPT by OpenAI, BERT, and T5 have enabled breakthroughs in human-AI communication. link] The process can be categorized into three agents: Execution Agent : The heart of the system, this agent leverages OpenAI’s API for task processing.
This is due to a deep disconnect between data engineering and datascience practices. Historically, our space has perceived streaming as a complex technology reserved for experienced data engineers with a deep understanding of incremental event processing.
The DeepPavlov Library uses BERT base models to deal with Question Answering, such as RoBERTa. BERT is a pre-trained transformer-based deep learning model for natural language processing that achieved state-of-the-art results across a wide array of natural language processing tasks when this model was proposed.
The SST2 dataset is a text classification dataset with two labels (0 and 1) and a column of text to categorize. Training – Take the shaped CSV file and run fine-tuning with BERT for text classification utilizing Transformers libraries. Note that this is different from using the built-in Transform or Capture steps via Pipelines.
In this article, we will explore about ALBERT ( A lite weighted version of BERT machine learning model) What is ALBERT? ALBERT (A Lite BERT) is a language model developed by Google Research in 2019. BERT, GPT-2, and XLNet are some examples of models that can be used as teacher models for ALBERT.
This allows GuardDuty to categorize previously unseen domains as highly likely to be malicious or benign based on their association to known malicious domains. The Jupyter notebook also generates BERT embeddings on the entities with text data, such as papers.
BERT, the first breakout large language model In 2019, a team of researchers at Goole introduced BERT (which stands for bidirectional encoder representations from transformers). By making BERT bidirectional, it allowed the inputs and outputs to take each others’ context into account. BERT), or consist of both (e.g.,
BERT, the first breakout large language model In 2019, a team of researchers at Goole introduced BERT (which stands for bidirectional encoder representations from transformers). By making BERT bidirectional, it allowed the inputs and outputs to take each others’ context into account. BERT), or consist of both (e.g.,
Transformer-based models, such as Bidirectional Encoder Representations from Transformers (BERT), have revolutionized NLP by offering accuracy comparable to human baselines on benchmarks like SQuAD for question-answer, entity recognition, intent recognition, sentiment analysis, and more.
Transformer-based models, such as Bidirectional Encoder Representations from Transformers (BERT), have revolutionized NLP by offering accuracy comparable to human baselines on benchmarks like SQuAD for question-answer, entity recognition, intent recognition, sentiment analysis, and more. DGX/EGX family, GPU-based Embedded Platforms i.e
We want to aggregate it, link it, filter it, categorize it, generate it and correct it. This generative output could be a complete game-changer, finally delivering the “insights” that datascience projects have generally over-promised and under-delivered. We want to recommend people text based on other text they liked.
Then, compile the model, harnessing the power of the Adam optimizer and categorical cross-entropy loss. This aids in organizing and categorizing large image datasets, enabling efficient search and retrieval of images based on their content. This setup enables the prediction of class probabilities.
E-commerce E-commerce platforms use ZSL for product categorization and recommendation systems, allowing them to suggest items based on user preferences without requiring exhaustive labelling of all products. The post Zero-Shot Learning: Unlocking the Power of AI Without Training Data appeared first on Pickl.AI.
Research models such as BERT and T5 have become much more accessible while the latest generation of language and multi-modal models are demonstrating increasingly powerful capabilities. Given the general nature of these models, they can be applied to various types of data including images [7] , video [8] , and audio [9]. Joshi et al.
Types of summarizations There are several techniques to summarize text, which are broadly categorized into two main approaches: extractive and abstractive summarization. In this post, we focus on the BERT extractive summarizer. It works by first embedding the sentences in the text using BERT.
AWS received about 100 samples of labeled data from the customer, which is a lot less than the 1,000 samples recommended for fine-tuning an LLM in the datascience community. LLMs are truly capable of learning from internet-scale data. Thus the basis of the transformer model was born.
Key strengths of VLP include the effective utilization of pre-trained VLMs and LLMs, enabling zero-shot or few-shot predictions without necessitating task-specific modifications, and categorizing images from a broad spectrum through casual multi-round dialogues. This model achieves a 91.3% Dr. Changsha Ma is an AI/ML Specialist at AWS.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







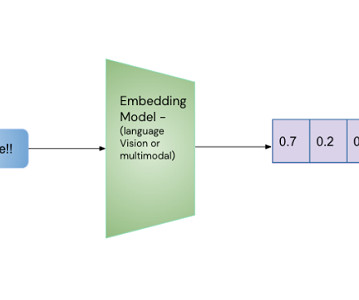



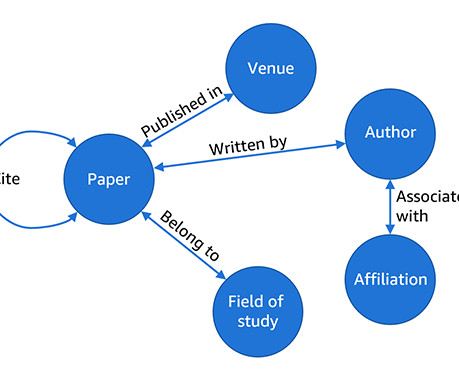









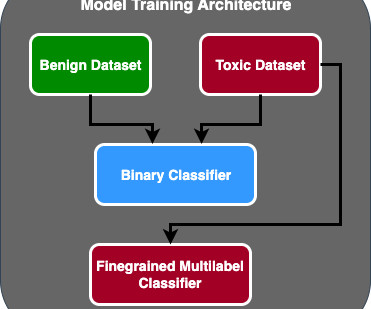







Let's personalize your content