This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As an Edge AI implementation, TensorFlow Lite greatly reduces the barriers to introducing large-scale computervision with on-device machine learning, making it possible to run machine learning everywhere. About us: At viso.ai, we power the most comprehensive computervision platform Viso Suite. What is TensorFlow?
This advancement has spurred the commercial use of generative AI in natural language processing (NLP) and computervision, enabling automated and intelligent data extraction. Named Entity Recognition ( NER) Named entity recognition (NER), an NLP technique, identifies and categorizes key information in text.
Foundation models can be trained to perform tasks such as data classification, the identification of objects within images (computervision) and natural language processing (NLP) (understanding and generating text) with a high degree of accuracy. An open-source model, Google created BERT in 2018.
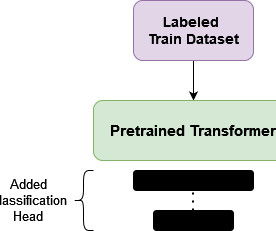
Introduction The idea behind using fine-tuning in Natural Language Processing (NLP) was borrowed from ComputerVision (CV). In the case of BERT (Bidirectional Encoder Representations from Transformers), learning involves predicting randomly masked words (bidirectional) and sentence-order prediction.
Types of summarizations There are several techniques to summarize text, which are broadly categorized into two main approaches: extractive and abstractive summarization. In this post, we focus on the BERT extractive summarizer. It works by first embedding the sentences in the text using BERT.
Blockchain technology can be categorized primarily on the basis of the level of accessibility and control they offer, with Public, Private, and Federated being the three main types of blockchain technologies.
In modern machine learning and artificial intelligence frameworks, transformers are one of the most widely used components across various domains including GPT series, and BERT in Natural Language Processing, and Vision Transformers in computervision tasks.
Manually analyzing and categorizing large volumes of unstructured data, such as reviews, comments, and emails, is a time-consuming process prone to inconsistencies and subjectivity. We provide a prompt example for feedback categorization. Extracting valuable insights from customer feedback presents several significant challenges.
In addition to textual inputs, this model uses traditional structured data inputs such as numerical and categorical fields. We show you how to train, deploy and use a churn prediction model that has processed numerical, categorical, and textual features to make its prediction. Computervision. Credit rating prediction.
We’ll start with a seminal BERT model from 2018 and finish with this year’s latest breakthroughs like LLaMA by Meta AI and GPT-4 by OpenAI. BERT by Google Summary In 2018, the Google AI team introduced a new cutting-edge model for Natural Language Processing (NLP) – BERT , or B idirectional E ncoder R epresentations from T ransformers.
The previous year saw a significant increase in the amount of work that concentrated on ComputerVision (CV) and Natural Language Processing (NLP). MusicLM is specifically trained on SoundStream, w2v-BERT, and MuLan pre-trained modules. MusicCaps is a publicly available dataset with 5.5k
BERTBERT, an acronym that stands for “Bidirectional Encoder Representations from Transformers,” was one of the first foundation models and pre-dated the term by several years. BERT proved useful in several ways, including quantifying sentiment and predicting the words likely to follow in unfinished sentences.
This enhances the interpretability of AI systems for applications in computervision and natural language processing (NLP). Viso Suite: The only truly end-to-end computervision solution, Viso Suite eliminates the need for point solutions. Viso Suite is the end-to-End, No-Code ComputerVision Solution.
About us : Viso Suite is our end-to-end computervision infrastructure for enterprises. The powerful solution enables teams to develop, deploy, manage, and secure computervision applications in one place. Some common free-to-use pre-trained models include BERT, ResNet , YOLO etc. Book a demo to learn more.
Categorization of LLMs – Source One of the most common examples of an LLM is a virtual voice assistant such as Siri or Alexa. The models, such as BERT and GPT-3 (improved version of GPT-1 and GPT-2), made NLP tasks better and polished. GPT-4, BERT) based on your specific task requirements.
This innovative approach is transforming applications in computervision, Natural Language Processing, healthcare, and more. E-commerce E-commerce platforms use ZSL for product categorization and recommendation systems, allowing them to suggest items based on user preferences without requiring exhaustive labelling of all products.
Transformer-based models, such as Bidirectional Encoder Representations from Transformers (BERT), have revolutionized NLP by offering accuracy comparable to human baselines on benchmarks like SQuAD for question-answer, entity recognition, intent recognition, sentiment analysis, and more. DGX/EGX family, GPU-based Embedded Platforms i.e
The Segment Anything Model (SAM), a recent innovation by Meta’s FAIR (Fundamental AI Research) lab, represents a pivotal shift in computervision. SAM performs segmentation, a computervision task , to meticulously dissect visual data into meaningful segments, enabling precise analysis and innovations across industries.
Here are a few examples across various domains: Natural Language Processing (NLP) : Predictive NLP models can categorize text into predefined classes (e.g., Masking in BERT architecture ( illustration by Misha Laskin ) Another common type of generative AI model are diffusion models for image and video generation and editing.
Using deep learning, computers can learn and recognize patterns from data that are considered too complex or subtle for expert-written software. In this workshop, you’ll learn how deep learning works through hands-on exercises in computervision and natural language processing.
Figure 1: adversarial examples in computervision (left) and natural language processing tasks (right). This is generally a positive thing, but it sometimes over-generalizes , leading to examples such as this: Figure 4: BERT guesses that the masked token should be a color, but fails to predict the correct color.
Cross-modal retrieval is a branch of computervision and natural language processing that links visual and verbal descriptions. The shape (224, 224, 3) corresponds to a standard RGB image size commonly used in computervision tasks. !pip pip install tensorflow --q !pip
Like other large language models, including BERT and GPT-3, LaMDA is trained on terabytes of text data to learn how words relate to one another and then predict what words are likely to come next. Text classification for spam filtering, topic categorization, or document organization. How is the problem approached?
Research models such as BERT and T5 have become much more accessible while the latest generation of language and multi-modal models are demonstrating increasingly powerful capabilities. 92] categorized the languages of the world into six different categories based on the amount of labeled and unlabeled data available in them.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























Let's personalize your content