This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
One-hot encoding is a process by which categorical variables are converted into a binary vector representation where only one bit is “hot” (set to 1) while all others are “cold” (set to 0). GPT Architecture Here's a more in-depth comparison of the T5, BERT, and GPT models across various dimensions: 1.
To install and import the library, use the following commands: pip install -q transformers from transformers import pipeline Having done that, you can execute NLP tasks starting with sentiment analysis, which categorizes text into positive or negative sentiments. We choose a BERT model fine-tuned on the SQuAD dataset.
This panel has designed the guidelines for annotating the wellness dimensions and categorized the posts into the six wellness dimensions based on the sensitive content of each post. Using BERT and MentalBERT, we could capture these subtleties effectively by contextualizing each word based on the surrounding text.
Experiments proceed iteratively, with results categorized as improvements, maintenance, or declines. to close the gap between BERT-base and BERT-large performance. It automatically generates and debugs code using an exception-traceback-guided process. improvement over baseline models.
This article explores an innovative way to streamline the estimation of Scope 3 GHG emissions leveraging AI and Large Language Models (LLMs) to help categorize financial transaction data to align with spend-based emissions factors. Why are Scope 3 emissions difficult to calculate?
This interdisciplinary field incorporates linguistics, computer science, and mathematics, facilitating automatic translation, text categorization, and sentiment analysis. RALMs’ language models are categorized into autoencoder, autoregressive, and encoder-decoder models.
It needed to intelligently categorize transactions based on their descriptions and other contextual factors about the business to ensure they are mapped to the appropriate classification. They have seen an increase of 56% transaction classification accuracy after moving to the new BERT based model.
Named Entity Recognition ( NER) Named entity recognition (NER), an NLP technique, identifies and categorizes key information in text. Source: A pipeline on Generative AI This figure of a generative AI pipeline illustrates the applicability of models such as BERT, GPT, and OPT in data extraction.
Types of summarizations There are several techniques to summarize text, which are broadly categorized into two main approaches: extractive and abstractive summarization. In this post, we focus on the BERT extractive summarizer. It works by first embedding the sentences in the text using BERT.
While large language models (LLMs) have claimed the spotlight since the debut of ChatGPT, BERT language models have quietly handled most enterprise natural language tasks in production. Additionally, while the data and code needed to train some of the latest generation of models is still closed-source, open source variants of BERT abound.
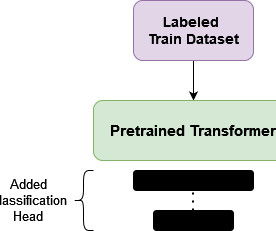
In the case of BERT (Bidirectional Encoder Representations from Transformers), learning involves predicting randomly masked words (bidirectional) and sentence-order prediction. For concreteness, we will use BERT as the base model and set the number of classification labels to 4.
BERT (Bi-directional Encoder Representations from Transformers) is one of the earliest LLM foundation models developed. An open-source model, Google created BERT in 2018. A specific kind of foundation model known as a large language model (LLM) is trained on vast amounts of text data for NLP tasks.
Natural language processing (NLP) activities, including speech-to-text, sentiment analysis, text summarization, spell-checking, token categorization, etc., XLNet obtains state-of-the-art performance on 18 tasks, including question answering, natural language inference, sentiment analysis, and document rating, and it beats BERT on 20 tasks.
While earlier surveys predominantly centred on encoder-based models such as BERT, the emergence of decoder-only Transformers spurred advancements in analyzing these potent generative models. Existing surveys detail a range of techniques utilized in Explainable AI analyses and their applications within NLP.
More recent methods based on pre-trained language models like BERT obtain much better context-aware embeddings. Existing methods predominantly use smaller BERT-style architectures as the backbone model. For model training, they opted for fine-tuning the open-source 7B parameter Mistral model instead of smaller BERT-style architectures.
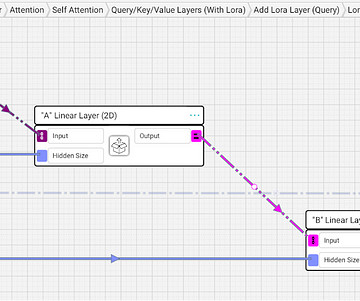
Back when BERT and GPT2 were first revolutionizing natural language processing (NLP), there was really only one playbook for fine-tuning. BERT LoRA First, I’ll show LoRA in the BERT implementation, and then I’ll do the same for GPT. You had to be very careful with fine-tuning because of catastrophic forgetting.
Introduction In natural language processing, text categorization tasks are common (NLP). transformer.ipynb” uses the BERT architecture to classify the behaviour type for a conversation uttered by therapist and client, i.e, The fourth model which is also used for multi-class classification is built using the famous BERT architecture.
Huge transformer models like BERT, GPT-2 and XLNet have set a new standard for accuracy on almost every NLP leaderboard. In a recent talk at Google Berlin, Jacob Devlin described how Google are using his BERT architectures internally. We provide an example component for text categorization.
The pre-train and fine-tune paradigm, exemplified by models like ELMo and BERT, has evolved into prompt-based reasoning used by the GPT family. These sources can be categorized into three types: textual documents (e.g., KD methods can be categorized into white-box and black-box approaches.
These advanced AI deep learning models have seamlessly integrated into various applications, from Google's search engine enhancements with BERT to GitHub’s Copilot, which harnesses the capability of Large Language Models (LLMs) to convert simple code snippets into fully functional source codes.
Machine translation, summarization, ticket categorization, and spell-checking are among the examples. BERT (Bidirectional Encoder Representations from Transformers) — developed by Google. BERT (Bidirectional Encoder Representations from Transformers) — developed by Google.
The development of Large Language Models (LLMs), such as GPT and BERT, represents a remarkable leap in computational linguistics. The system’s error detection mechanism is designed to identify and categorize failures during execution promptly. Training these models, however, is challenging.
Manually analyzing and categorizing large volumes of unstructured data, such as reviews, comments, and emails, is a time-consuming process prone to inconsistencies and subjectivity. We provide a prompt example for feedback categorization. Extracting valuable insights from customer feedback presents several significant challenges.
Blockchain technology can be categorized primarily on the basis of the level of accessibility and control they offer, with Public, Private, and Federated being the three main types of blockchain technologies.
M5 LLMS are BERT-based LLMs fine-tuned on internal Amazon product catalog data using product title, bullet points, description, and more. Fine-tune the sentence transformer M5_ASIN_SMALL_V20 Now we create a sentence transformer from a BERT-based model called M5_ASIN_SMALL_V2.0. str.split("|").str[0] All other code remains the same.
In addition to textual inputs, this model uses traditional structured data inputs such as numerical and categorical fields. We show you how to train, deploy and use a churn prediction model that has processed numerical, categorical, and textual features to make its prediction. BERT + Random Forest.
In modern machine learning and artificial intelligence frameworks, transformers are one of the most widely used components across various domains including GPT series, and BERT in Natural Language Processing, and Vision Transformers in computer vision tasks.
Systems like ChatGPT by OpenAI, BERT, and T5 have enabled breakthroughs in human-AI communication. link] The process can be categorized into three agents: Execution Agent : The heart of the system, this agent leverages OpenAI’s API for task processing.
Lastly, with the help of expert annotators, we were successful in categorizing the data based on the respective criteria for both escapism and PTSD. So, how did we work on the categorizing? were used to capture nuanced language patterns.
We’ll start with a seminal BERT model from 2018 and finish with this year’s latest breakthroughs like LLaMA by Meta AI and GPT-4 by OpenAI. BERT by Google Summary In 2018, the Google AI team introduced a new cutting-edge model for Natural Language Processing (NLP) – BERT , or B idirectional E ncoder R epresentations from T ransformers.
In the general language domain, there are two main branches of pre-trained language models: BERT (and its variants) and GPT (and its variants). The first one, BERT (and its variants), has received the most attention in the biomedical domain; examples include BioBERT and PubMedBERT, while the second one has received less attention.
The DeepPavlov Library uses BERT base models to deal with Question Answering, such as RoBERTa. BERT is a pre-trained transformer-based deep learning model for natural language processing that achieved state-of-the-art results across a wide array of natural language processing tasks when this model was proposed.
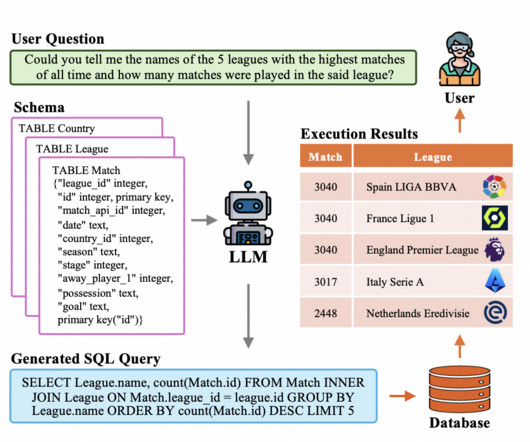
Methodology Based on Pre-Trained Language Models (PLMs): Text-to-SQL jobs were optimized using the semantic knowledge of pre-trained language models (PLMs) such as BERT and RoBERTa. To provide more precise SQL queries, schema-aware PLMs integrated knowledge of database structures.
For instance, a BERT model with 86 million parameters can perform NLI tasks, while the smallest effective zero-shot generative LLMs require 7-8 billion parameters. This approach allows the use of smaller encoder language models like BERT for classification tasks, dramatically reducing computational requirements compared to generative LLMs.
The KGW Family modifies the logits produced by the LLM to create watermarked output by categorizing the vocabulary into a green list and a red list based on the preceding token. These watermarking techniques are mainly divided into two categories: the KGW Family and the Christ Family.
MusicLM is specifically trained on SoundStream, w2v-BERT, and MuLan pre-trained modules. This includes 78,366 categorized sound events across 44 categories and 39,187 non-categorized sound events. MusicCaps is a publicly available dataset with 5.5k music-text pairs annotated with detailed human-generated descriptions.
It uses BERT, a popular NLP technique, to understand the meaning and context of words in the candidate summary and reference summary. The more similar the words and meanings captured by BERT, the higher the BERTScore. It uses neural networks like BERT to measure semantic similarity beyond just exact word or phrase matching.
Against this backdrop, researchers began using PLMs like BERT, which required less data and provided better predictive performance. The methodology proposed by the research team categorizes tabular data into two major categories: 1D and 2D.
This system comprises a lightweight BERT-based router categorizing incoming queries into predefined domains such as health, science, and coding. Researchers from the University of Melbourne introduced a groundbreaking solution named MoDEM (Mixture of Domain Expert Models).
The transformer architecture was the foundation for two of the most well-known and popular LLMs in use today, the Bidirectional Encoder Representations from Transformers (BERT) 4 (Radford, 2018) and the Generative Pretrained Transformer (GPT) 5 (Devlin 2018). RoBERTa: A Robustly Optimized BERT Pretraining Approach” Marcos Zampieri et al.,
Be sure to check out his talk, “ Bagging to BERT — A Tour of Applied NLP ,” there! cats” component of Docs, for which we’ll be training a text categorization model to classify sentiment as “positive” or “negative.” Editor’s note: Benjamin Batorsky, PhD is a speaker for ODSC East 2023. These can be customized and trained.
BERTBERT, an acronym that stands for “Bidirectional Encoder Representations from Transformers,” was one of the first foundation models and pre-dated the term by several years. BERT proved useful in several ways, including quantifying sentiment and predicting the words likely to follow in unfinished sentences.
Complete training materials for FastText and Bert implementation accompany the dataset, with upcoming suggestions for data proportioning based on RegMix methodology. URL labeling utilizes GPT-4 to process the top million root URLs, categorizing them into Domain-of-Interest (DoI) and Domain-of-Non-Interest (DoNI) URLs.
Often featuring tens of billions of parameters, these models are significantly more resource-intensive than established augmentation methods such as back translation paraphrasing or BERT-based techniques. and Llama-3-8B.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content