This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ArticleVideo Book This article was published as a part of the Data Science Blogathon BERT is too kind — so this article will be touching. The post Measuring Text Similarity Using BERT appeared first on Analytics Vidhya.
They find numerous applications across different industries, such as providing personalized product recommendations to customers, offering round-the-clock customer support for query resolution, assisting with customer bookings, and much more.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction NLP or Natural Language Processing is an exponentially growing field. The post Why and how to use BERT for NLP Text Classification? appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Training hugging face most famous model on TPU for social media. The post Training BERT Text Classifier on Tensor Processing Unit (TPU) appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Natural Language processing, a sub-field of machine learning has gained. The post Amazon Product review Sentiment Analysis using BERT appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction to BERT: BERT stands for Bidirectional Encoder Representations from Transformers. The post BERT for Natural Language Inference simplified in Pytorch! appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Machines understand language through language representations. The post All You Need to know about BERT appeared first on Analytics Vidhya. These language representations are.
In 2024, ChatGPT is still one of the most trending topics, and this article lists the top ChatGPT books one should read to augment their understanding of the topic. It provides codes for working with various models, such as GPT-4, BERT, T5, etc., It provides codes for working with various models, such as GPT-4, BERT, T5, etc.,
This article lists the top LangChain books one should read in 2024 to deepen one’s understanding of this trending topic. Quick Start Guide to Large Language Models This book guides how to work with, integrate, and deploy LLMs to solve real-world problems.
A few years back, two groundbreaking models, BERT and GPT, emerged as game-changers. While BERT and GPT laid a strong foundation and opened doors to possibilities, researchers and technologists are now building upon that, pushing boundaries and exploring uncharted territories. Then there’s GPT, the Generative Pre-trained Transformer.
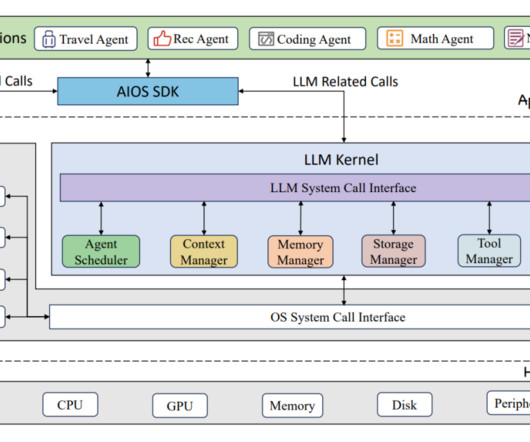
In recent years, Natural Language Processing (NLP) has undergone a pivotal shift with the emergence of Large Language Models (LLMs) like OpenAI's GPT-3 and Google’s BERT. The Brain (LLM Core) At the core of every LLM-based agent lies its brain, typically represented by a pre-trained language model like GPT-3 or BERT.
Transformer Models & BERT Models Image Source Course difficulty: Beginner-level Completion time: ~ 45 minutes Prerequisites: Intermediate knowledge of ML, understanding of word embeddings and attention mechanism, and experience with Python and TensorFlow. Covers the different NLP tasks for which a BERT model is used.
The following is a brief tutorial on how BERT and Transformers work in NLP-based analysis using the Masked Language Model (MLM). Introduction In this tutorial, we will provide a little background on the BERT model and how it works. The BERT model was pre-trained using text from Wikipedia. What is BERT? How Does BERT Work?
Photo by Abiyyu Zahy on Unsplash If youre diving into AI and want to understand the secret sauce behind modern language models like ChatGPT or BERT, you need to get familiar with Transformers and their game-changing attention mechanism.
While large language models (LLMs) have claimed the spotlight since the debut of ChatGPT, BERT language models have quietly handled most enterprise natural language tasks in production. Additionally, while the data and code needed to train some of the latest generation of models is still closed-source, open source variants of BERT abound.
While large language models (LLMs) have claimed the spotlight since the debut of ChatGPT, BERT language models have quietly handled most enterprise natural language tasks in production. Additionally, while the data and code needed to train some of the latest generation of models is still closed-source, open source variants of BERT abound.
Large Language Models (LLMs) like ChatGPT, Google’s Bert, Gemini, Claude Models, and others have emerged as central figures, redefining our interaction with digital interfaces. LLMs like ChatGPT, Google’s BERT, and others exemplify the advancements in this field.
Handpicked blogs, tutorials, books and… For free. Do you wish to build and deploy a Bert question-answering app to the web for free but don’t know how? Last Updated on April 1, 2023 by Editorial Team Author(s): Lan Chu Originally published on Towards AI. Free learning resources for Data Scientists & Developers. And real quick.
BERT (Bi-directional Encoder Representations from Transformers) is one of the earliest LLM foundation models developed. An open-source model, Google created BERT in 2018. A specific kind of foundation model known as a large language model (LLM) is trained on vast amounts of text data for NLP tasks.
Photo by Abiyyu Zahy on Unsplash If youre diving into AI and want to understand the secret sauce behind modern language models like ChatGPT or BERT, you need to get familiar with Transformers and their game-changing attention mechanism.
Photo by Abiyyu Zahy on Unsplash If youre diving into AI and want to understand the secret sauce behind modern language models like ChatGPT or BERT, you need to get familiar with Transformers and their game-changing attention mechanism.
LLMs, such as GPT-4 and BERT , operate on entirely different principles when processing and storing information. These models are trained on vast datasets comprising text from various sources, such as books, websites, articles, etc. This flexibility is one of the main ways human memory differs from the more rigid systems used in AI.
ArticleVideo Book This article was published as a part of the Data Science Blogathon “MuRIL is a starting point of what we believe can be. The post A Gentle Introduction To MuRIL : Multilingual Representations for Indian Languages appeared first on Analytics Vidhya.
Meaning you’ll have a better understanding of all the mechanisms to make you a more effective data scientist if you read even just a few of these books. Top books for data scientists 1. The key takeaway from the book is to be conscious of uncertainty because of the ever-changing environment, especially in the IT industry.
Building LLMs for Production is now available as an e-book at an exclusive price on Towards AI Academy! The e-book covers everything from foundational concepts to advanced techniques and real-world applications, offering a structured and hands-on learning experience. Also, Happy Halloween to all those celebrating. Enjoy the read!
Transformers have transformed the field of NLP over the last few years, with LLMs like OpenAI’s GPT series, BERT, and Claude Series, etc. This dataset typically comprises text from various sources, including books, articles, websites, and more, to cover multiple aspects of human language and knowledge.
By pre-training on text from diverse sources like books, websites, and articles, LLMs gain a deep understanding of grammar, syntax, semantics, and even general world knowledge. Some well-known examples include OpenAIs GPT (Generative Pre-trained Transformer) and Googles BERT (Bidirectional Encoder Representations from Transformers).
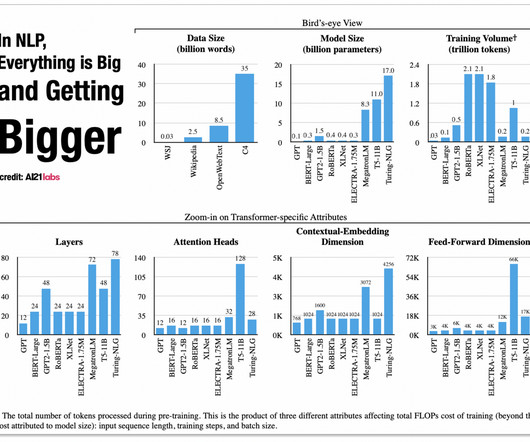
We’ll start with a seminal BERT model from 2018 and finish with this year’s latest breakthroughs like LLaMA by Meta AI and GPT-4 by OpenAI. BERT by Google Summary In 2018, the Google AI team introduced a new cutting-edge model for Natural Language Processing (NLP) – BERT , or B idirectional E ncoder R epresentations from T ransformers.
Imagine GPT writing the end of a book. For the model to understand everything it has written it needs to keep a very long context window, otherwise, the ending of the book would not wrap up all of the plot details. Plus, many models are not actually trained on very long inputs, so they suffer as inputs get longer.
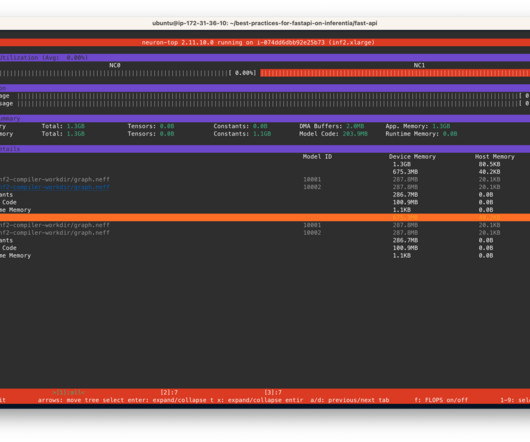
In this post, we use a Hugging Face BERT-Large model pre-training workload as a simple example to explain how to useTrn1 UltraClusters. Launch your training job We use the Hugging Face BERT-Large Pretraining Tutorial as an example to run on this cluster. Each compute node has Neuron tools installed, such as neuron-top. He has a Ph.D.
It offers a wealth of books, on-demand courses, live events, short-form posts, interactive labs, expert playlists, and more—formed from the proprietary content of thousands of independent authors, industry experts, and several of the largest education publishers in the world.
Then the agent carries out the steps sequentially, booking flights, reserving hotels, processing payments, and more. As demonstrated in the following table, the BERT and BLEU scores achieve the value of 1.0, The user requests the system for a trip information following which, the travel agent breaks down the task into executable steps.
Paper Title: "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding" Key Takeaway: Introduced BERT, showcasing the efficacy of pre-training deep bidirectional models, thereby achieving state-of-the-art results on various NLP tasks.
Currently, we are working hard on the second edition of Building LLMs for Production, and we would love to know how your reading journey with the book has been. Super excited to read your reviews for the book! Help us make the second edition better by leaving us a review on Amazon! shamelessly expecting a lot of them!)
The backbone is a BERT architecture made up of 12 encoding layers. Otherwise, the architecture of DNABERT is similar to that of BERT. He got interested in this project after reading the book The Code Breaker. DNABERT is a pre-trained transformer model with non-overlapping human DNA sequence data.
These embeddings are aligned with semantic embeddings derived from textual descriptions through pre-trained LLMs such as BERT. Using datasets like Amazon books, Yelp, and Google reviews, the researchers measured utility and diversity metrics, demonstrating HARec’s superiority over existing models.
LLMs are trained with the help of massive volumes of text data from a variety of sources, including books, journals, webpages, and other textual resources. BERT – Bidirectional Encoder Representations from Transformers (BERT) is one of the first Transformer-based self-supervised language models.
Their decoder-only model, inspired by NLP giants like BERT, uses a patch-based approach to handle data efficiently. Patching — Breaking Down the Data First, think about how you might break down a long book into manageable chapters. This is the groundbreaking work of Abhimanyu Das, Weihao Kong, Rajat Sen, and Yichen Zhou.
Also in this folder, we provide all the scripts necessary to trace a bert-base-uncased model on AWS Inferentia. The screenshot shows the compiler logs for the bert-base-uncased-squad2 model. He is the author of two books: Learn TensorFlow Enterprise and TensorFlow 2 Pocket Reference. code as the entry point. The fastapi-server.py
I used this foolproof method of consuming the right information and ended up publishing books , artworks , Podcasts and even an LLM powered consumer facing app ranked #40 on the app store. YouTube Transformer Models (cohere.com) Intro to BERT (early LLM example) BERT Neural Network — EXPLAINED! — YouTube
Models like GPT 4, BERT, DALL-E 3, CLIP, Sora, etc., Use Cases for Foundation Models Applications in Pre-trained Language Models like GPT, BERT, Claude, etc. Learn more about Viso Suite by booking a demo with us. Foundation models are recent developments in artificial intelligence (AI). are at the forefront of the AI revolution.
BERTBERT uses a transformer-based architecture, which allows it to effectively handle longer input sequences and capture context from both the left and right sides of a token or word (the B in BERT stands for bi-directional). This allows BERT to learn a deeper sense of the context in which words appear.
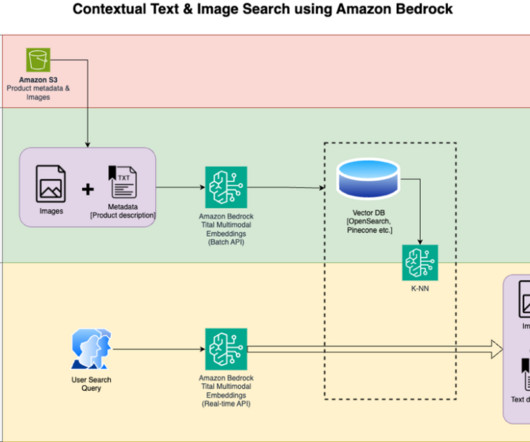
The following is a high-level overview of how it works conceptually: Separate encoders – These models have separate encoders for each modality—a text encoder for text (for example, BERT or RoBERTa), image encoder for images (for example, CNN for images), and audio encoders for audio (for example, models like Wav2Vec).
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content