This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
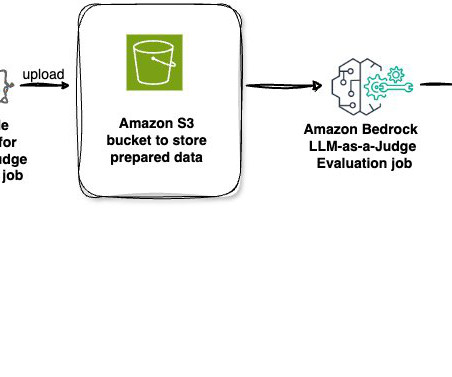
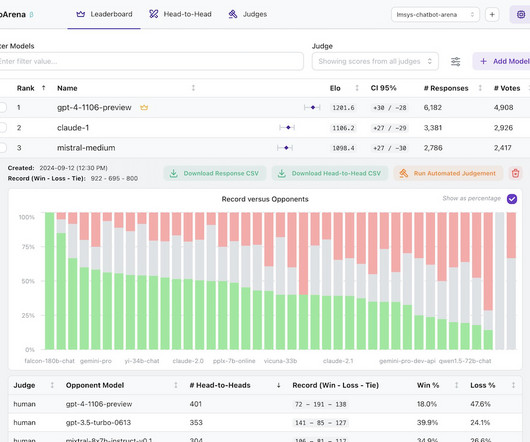
The LLM-as-a-Judge framework is a scalable, automated alternative to human evaluations, which are often costly, slow, and limited by the volume of responses they can feasibly assess. Here, the LLM-as-a-Judge approach stands out: it allows for nuanced evaluations on complex qualities like tone, helpfulness, and conversational coherence.
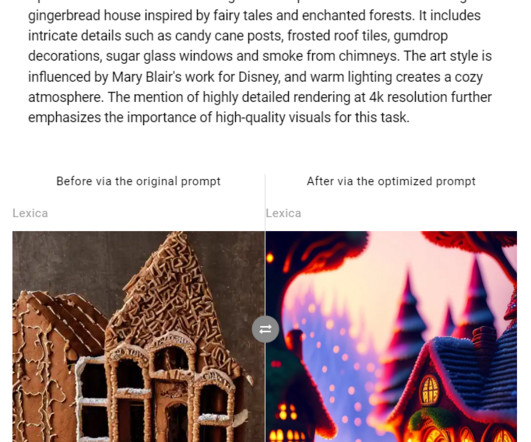
In the ever-evolving landscape of artificial intelligence, the art of promptengineering has emerged as a pivotal skill set for professionals and enthusiasts alike. Promptengineering, essentially, is the craft of designing inputs that guide these AI systems to produce the most accurate, relevant, and creative outputs.
The secret sauce to ChatGPT's impressive performance and versatility lies in an art subtly nestled within its programming – promptengineering. This makes us all promptengineers to a certain degree. Venture capitalists are pouring funds into startups focusing on promptengineering, like Vellum AI.
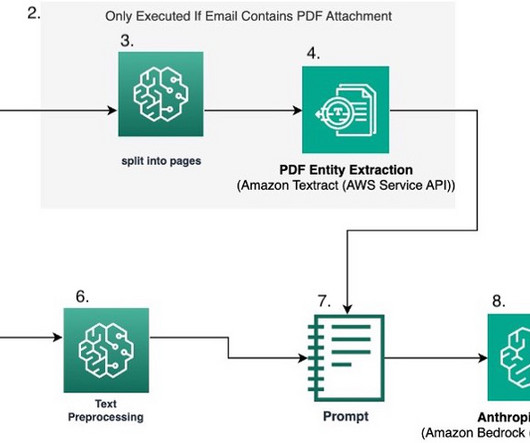
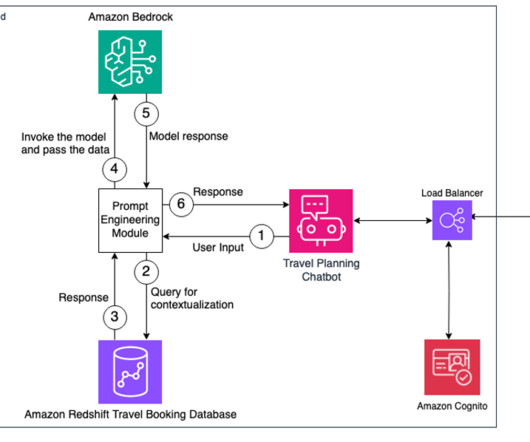
However, there are benefits to building an FM-based classifier using an API service such as Amazon Bedrock, such as the speed to develop the system, the ability to switch between models, rapid experimentation for promptengineering iterations, and the extensibility into other related classification tasks. Text from the email is parsed.
Today, were excited to announce the general availability of Amazon Bedrock Data Automation , a powerful, fully managed feature within Amazon Bedrock that automate the generation of useful insights from unstructured multimodal content such as documents, images, audio, and video for your AI-powered applications.
Promptengineering , the art and science of crafting prompts that elicit desired responses from LLMs, has become a crucial area of research and development. In this comprehensive technical blog, we'll delve into the latest cutting-edge techniques and strategies that are shaping the future of promptengineering.
Whether you're leveraging OpenAI’s powerful GPT-4 or with Claude’s ethical design, the choice of LLM API could reshape the future of your business. Why LLM APIs Matter for Enterprises LLM APIs enable enterprises to access state-of-the-art AI capabilities without building and maintaining complex infrastructure.
It simplifies the creation and management of AI automations using either AI flows, multi-agent systems, or a combination of both, enabling agents to work together seamlessly, tackling complex tasks through collaborative intelligence. At a high level, CrewAI creates two main ways to create agentic automations: flows and crews.
Hands-On PromptEngineering for LLMs Application Development Once such a system is built, how can you assess its performance? In this article, we will explore and share best practices for evaluating LLM outputs and provide insights into the experience of building these systems. Automating Evaluation Metrics1.3.
Validating Output from Instruction-Tuned LLMs Checking outputs before showing them to users can be important for ensuring the quality, relevance, and safety of the responses provided to them or used in automation flows.
Despite advancements, prompt sensitivity remains a hurdle, especially in proprietary models where version changes can alter behavior significantly. Balancing prompt optimization with practical constraints is essential for real-world LLM applications. Estimators support various tasks like human annotation and LLM estimation.
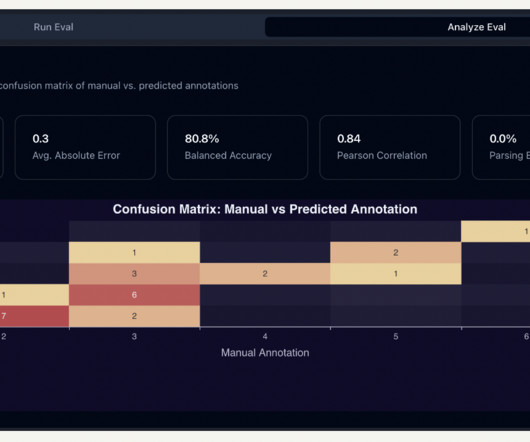
The evaluation of large language model (LLM) performance, particularly in response to a variety of prompts, is crucial for organizations aiming to harness the full potential of this rapidly evolving technology. Both features use the LLM-as-a-judge technique behind the scenes but evaluate different things.
It teaches the LLM to recognise the kinds of things that Wolfram|Alpha might know – our knowledge engine,” McLoone explains. Where I see it, [approaches to AI] all share something in common, which is all about using the machinery of computation to automate knowledge,” says McLoone. Our approach on that is completely different.
One of LLMs most fascinating strengths is their inherent ability to understand context. Localization relies on both automation and humans-in-the-loop in a process called Machine Translation Post Editing (MTPE). However, the industry is seeing enough potential to consider LLMs as a valuable option.
LLM-as-Judge has emerged as a powerful tool for evaluating and validating the outputs of generative models. LLMs (and, therefore, LLM judges) inherit biases from their training data. In this article, well explore how enterprises can leverage LLM-as-Judge effectively , overcome its limitations, and implement best practices.
It enables you to privately customize the FMs with your data using techniques such as fine-tuning, promptengineering, and Retrieval Augmented Generation (RAG), and build agents that run tasks using your enterprise systems and data sources while complying with security and privacy requirements.
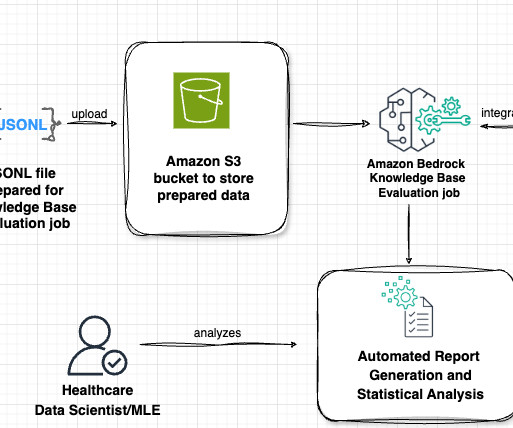
As the landscape of generative models evolves rapidly, organizations, researchers, and developers face significant challenges in systematically evaluating different models, including LLMs (Large Language Models), retrieval-augmented generation (RAG) setups, or even variations in promptengineering.
Promptengineers are responsible for developing and maintaining the code that powers large language models or LLMs for short. But to make this a reality, promptengineers are needed to help guide large language models to where they need to be. But what exactly is a promptengineer ?
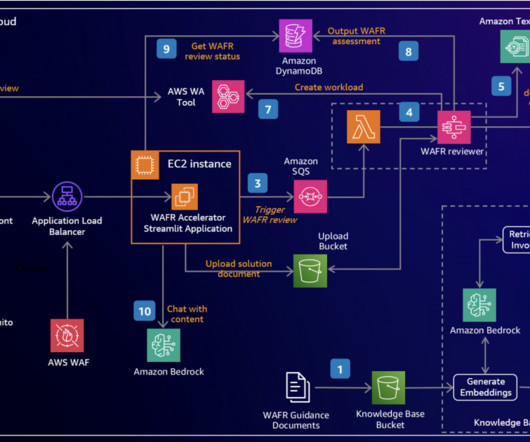
We demonstrate how to harness the power of LLMs to build an intelligent, scalable system that analyzes architecture documents and generates insightful recommendations based on AWS Well-Architected best practices. The quality of prompt (the system prompt, in this case) has significant impact on the model output.
Who hasn’t seen the news surrounding one of the latest jobs created by AI, that of promptengineering ? If you’re unfamiliar, a promptengineer is a specialist who can do everything from designing to fine-tuning prompts for AI models, thus making them more efficient and accurate in generating human-like text.
Having been there for over a year, I've recently observed a significant increase in LLM use cases across all divisions for task automation and the construction of robust, secure AI systems. Every financial service aims to craft its own fine-tuned LLMs using open-source models like LLAMA 2 or Falcon.
In our previous blog posts, we explored various techniques such as fine-tuning large language models (LLMs), promptengineering, and Retrieval Augmented Generation (RAG) using Amazon Bedrock to generate impressions from the findings section in radiology reports using generative AI. Part 1 focused on model fine-tuning.
With that said, companies are now realizing that to bring out the full potential of AI, promptengineering is a must. So we have to ask, what kind of job now and in the future will use promptengineering as part of its core skill set?
Leading this revolution is ChatGPT, a state-of-the-art large language model (LLM) developed by OpenAI. ChatGPT’s advanced language understanding, and generation capacities have not only increased user engagement but also opened new avenues for increased productivity and automation in personal life as well as business problems.
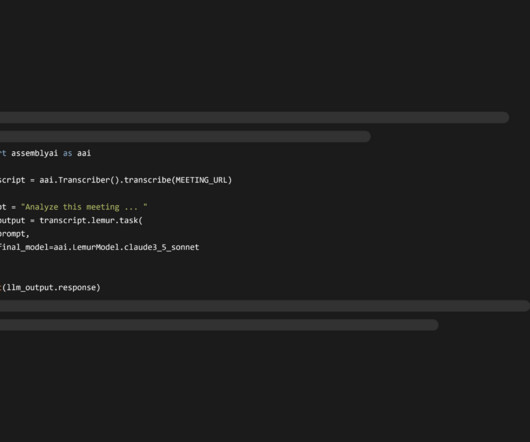
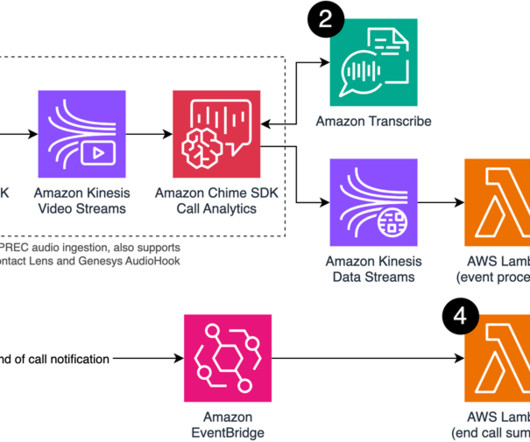
transcribe(MEETING_URL) Step 2: Generate a meeting summary Now that we have a transcript, we can prompt it with LLMs. To do this we first we need to create this prompt. Here's an example that generates a comprehensive meeting summary, guiding the LLM in analyzing your meeting transcript. Add these lines to your main.py
Because Large Language Models (LLM) are general-purpose models that dont have all or even the most recent data, you need to augment queries, otherwise known as prompts, to get a more accurate answer. But GenAI agents can fully automate responses without involving people. Copilots are usually built using RAG pipelines.
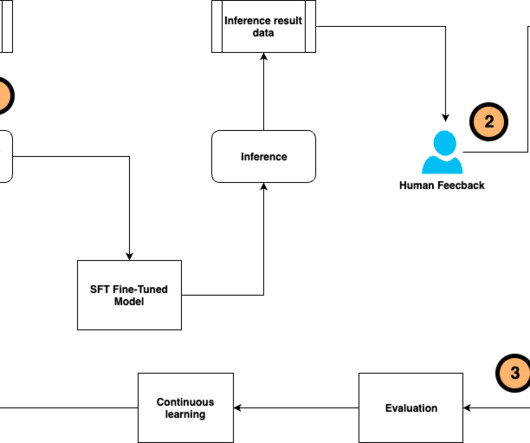
Fine-tuning a pre-trained large language model (LLM) allows users to customize the model to perform better on domain-specific tasks or align more closely with human preferences. You can use supervised fine-tuning (SFT) and instruction tuning to train the LLM to perform better on specific tasks using human-annotated datasets and instructions.
Promptengineering in under 10 minutes — theory, examples and prompting on autopilot Master the science and art of communicating with AI. Promptengineering is the process of coming up with the best possible sentence or piece of text to ask LLMs, such as ChatGPT, to get back the best possible response.
With the launch of the Automated Reasoning checks in Amazon Bedrock Guardrails (preview), AWS becomes the first and only major cloud provider to integrate automated reasoning in our generative AI offerings. Click on the image below to see a demo of Automated Reasoning checks in Amazon Bedrock Guardrails.
Ensuring reliable instruction-following in LLMs remains a critical challenge. Traditional promptengineering techniques fail to deliver consistent results. Traditional approaches to developing conversational LLM applications often fail in real-world use cases. You can find our research paper on ARQs vs. CoT on parlant.io
Traditional test case generation approaches rely on rule-based systems or manual engineering of prompts for Large Language Models (LLMs). Most researchers use manual methods to optimize promptengineering for test case generation, which requires significant time investment.
Misaligned LLMs can generate harmful, unhelpful, or downright nonsensical responsesposing risks to both users and organizations. This is where LLM alignment techniques come in. LLM alignment techniques come in three major varieties: Promptengineering that explicitly tells the model how to behave.
Operational efficiency Uses promptengineering, reducing the need for extensive fine-tuning when new categories are introduced. The raw data is processed by an LLM using a preconfigured user prompt. The LLM generates output based on the user prompt. The Step Functions workflow starts.
By harnessing the capabilities of generative AI, you can automate the generation of comprehensive metadata descriptions for your data assets based on their documentation, enhancing discoverability, understanding, and the overall data governance within your AWS Cloud environment.
Last time we delved into AutoGPT and GPT-Engineering , the early mainstream open-source LLM-based AI agents designed to automate complex tasks. Enter MetaGPT — a Multi-agent system that utilizes Large Language models by Sirui Hong fuses Standardized Operating Procedures (SOPs) with LLM-based multi-agent systems.
At my company Jotform, we have incorporated AI tools to automate tedious tasks, or as I call it, “busywork,” and free up employees to focus on the meaningful work that only humans can do. And it’s only as effective as the prompts you give it. I recently asked ChatGPT how to develop your promptengineering skills.
In 2025, artificial intelligence isnt just trendingits transforming how engineering teams build, ship, and scale software. Whether its automating code, enhancing decision-making, or building intelligent applications, AI is rewriting what it means to be a modern engineer. At the heart of this workflow is promptengineering.
After achieving the desired accuracy, you can use this ground truth data in an ML pipeline with automated machine learning (AutoML) tools such as AutoGluon to train a model and inference the support cases. If labeled data is unavailable, the next question is whether the testing process should be automated.
The relief from this manual work comes with promptengineering or the development of a unique optimization procedure, which is necessary for LLM evaluations to function as intended. To get the most out of an LLM evaluation, tailor it to the company’s unique use case and facts.
This process is known as inference — Source : Image by Author Getting the most out of LLMs requires carefully crafted prompts — the instructions given to the LLM to guide its output. While we will talk about a few of these, our focus will be on one novel approach called Chain of Thought (CoT) prompting.
The good news is that automating and solving the summarization challenge is now possible through generative AI. The best LLMs can process even complex, non-linear sentence structures with ease and determine various aspects, including topic, intent, next steps, outcomes, and more.
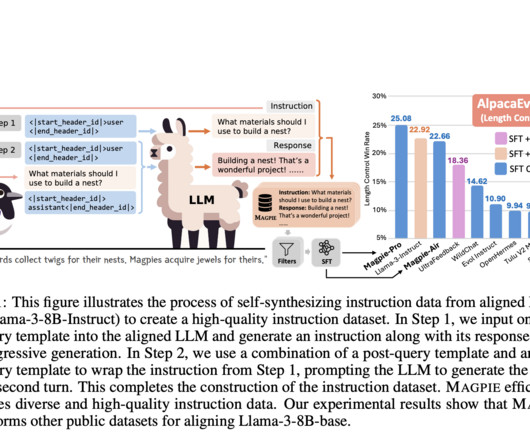
This limitation hinders the advancement of LLM capabilities and their application in diverse, real-world scenarios. Existing methods for generating instruction datasets fall into two categories: human-curated data and synthetic data produced by LLMs. The model then generates diverse user queries based on these templates.
Lets be real: building LLM applications today feels like purgatory. The truth is, we’re in the earliest days of understanding how to build robust LLM applications. What makes LLM applications so different? Theyre fundamentally non-deterministicwe call it the flip-floppy nature of LLMs: same input, different outputs.
The study of autonomous agents powered by large language models (LLMs) has shown great promise in enhancing human productivity. They allow users to focus on creative and strategic work by automating routine digital tasks. Traditional techniques relied on human-annotated data and promptengineering to enhance the performance of LLMs.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content