This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
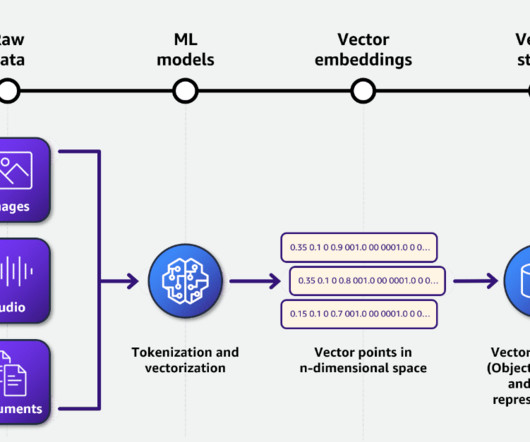
Metadata can play a very important role in using data assets to make data driven decisions. Generating metadata for your data assets is often a time-consuming and manual task. This post shows you how to enrich your AWS Glue Data Catalog with dynamic metadata using foundation models (FMs) on Amazon Bedrock and your data documentation.
The platform automatically analyzes metadata to locate and label structured data without moving or altering it, adding semantic meaning and aligning definitions to ensure clarity and transparency. When onboarding customers, we automatically retrain these ontologies on their metadata. Even defining it back then was a tough task.
Emerging technologies and trends, such as machine learning (ML), artificial intelligence (AI), automation and generative AI (gen AI), all rely on good data quality. Establishing standardized definitions and control measures builds a solid foundation that evolves as the framework matures.
Also, a lakehouse can introduce definitionalmetadata to ensure clarity and consistency, which enables more trustworthy, governed data. Watsonx.data enables users to access all data through a single point of entry, with a shared metadata layer deployed across clouds and on-premises environments.
The embeddings, along with metadata about the source documents, are indexed for quick retrieval. It provides constructs to help developers build generative AI applications using pattern-based definitions for your infrastructure. The embeddings are stored in the Amazon OpenSearch Service owner manuals index.
Therefore, we see national and international guidelines address these overlapping and intersecting definitions in a variety of ways. Relevant definitions of AI: Model owners may not realize that what they are procuring or deploying actually meets the definition of AI or intelligent automation as described by a regulation.
When the automated content processing steps are complete, you can use the output for downstream tasks, such as to invoke different components in a customer service backend application, or to insert the generated tags into metadata of each document for product recommendation.
In synchronous orchestration, just like in traditional process automation, a supervisor agent orchestrates the multi-agent collaboration, maintaining a high-level view of the entire process while actively directing the flow of information and tasks. The following diagram illustrates the supervisor agent methodology.
Our suite of managed integrations offers APIs to automate cluster setup and management: Domains : Link a custom domain to your cluster’s load balancer by using (CIS). Update the Kubernetes secret definition by adding or removing fields or updating the referenced Secrets Manager CRN for a TLS secret.
Whenever anyone talks about data lineage and how to achieve it, the spotlight tends to shine on automation. This is expected, as automating the process of calculating and establishing lineage is crucial to understanding and maintaining a trustworthy system of data pipelines.
SQL is one of the key languages widely used across businesses, and it requires an understanding of databases and table metadata. JSONs inherently structured format allows for clear and organized representation of complex data such as table schemas, column definitions, synonyms, and sample queries.
With a decade of enterprise AI experience, Veritone supports the public sector, working with US federal government agencies, state and local government, law enforcement agencies, and legal organizations to automate and simplify evidence management, redaction, person-of-interest tracking, and eDiscovery.
Specifically for the model building stage, Amazon SageMaker Pipelines automates the process by managing the infrastructure and resources needed to process data, train models, and run evaluation tests. This configuration takes the form of a Directed Acyclic Graph (DAG) represented as a JSON pipeline definition.
Implement metadata filtering , adding contextual layers to chunk retrieval. For code samples for metadata filtering using Amazon Bedrock Knowledge Bases, refer to the following GitHub repo. However, generating and maintaining large datasets using human annotators is a time-consuming and costly approach.
In this post, we will dive deeper into the first component of managing model risk, and look at opportunities at how automation provided by DataRobot brings about efficiencies in the development and implementation of models. . With this definition of model risk, how do we ensure the models we build are technically correct?
Even with the advances in automated subtitling facilitated by Machine Translation (MT) and Automatic Speech Recognition (ASR), automated dubbing is still a laborious and expensive procedure that frequently requires human involvement. It also offers strong metadata support for a range of difficult video operations.
GitHub Actions and Neptune are an ideal combination for automating machine-learning model training and experimentation. But, recording metadata is only half the secret to ML modeling success. Once we’ve committed the workflow definition to our repository and pushed it to GitHub, we’ll see our new workflow in the “Actions” tab.
It automatically keeps track of model artifacts, hyperparameters, and metadata, helping you to reproduce and audit model versions. In the notebook, we already added the @step decorator at the beginning of each function definition in the cell where the function was defined, as shown in the following code.
It is architected to automate the entire machine learning (ML) process, from data labeling to model training and deployment at the edge. Automating data labeling Data labeling is an inherently labor-intensive task that involves humans (labelers) to label the data. If you haven’t read it yet, we recommend checking out Part 1.
Kubernetes is an open-source container orchestration platform that automates the deployment, scaling, and management of containerized applications. Kubernetes provides mechanisms like StatefulSets and Custom Resource Definitions (CRDs) to manage and orchestrate distributed LLM deployments with model parallelism and sharding.
It’s much more than just automation. Continuous integration/delivery facilitates the automated building, testing, and packaging of the model training pipeline and deploying it into the target execution environment. The automated pipeline includes steps for out-of-the-box model storage and metric tracking.
For me, computer science is like solving a series of intricate puzzles with the added thrill of automation. For explainability, KGs allow us to link answers back to term definitions, data sources, and metrics, providing a verifiable trail that enhances trust and usability. I started with BASIC and quickly moved on to assembly language.
This feature streamlines the process of launching new instances with the most up-to-date Neuron SDK, enabling you to automate your deployment workflows and make sure you’re always using the latest optimizations. Amazon ECS configuration For Amazon ECS, create a task definition that references your custom Docker image.
Games24x7 employs an automated, data-driven, AI powered framework for the assessment of each player’s behavior through interactions on the platform and flags users with anomalous behavior. There was no mechanism to pass and store the metadata of the multiple experiments done on the model. amazonaws.com/tensorflow-training:2.11.0-cpu-py39-ubuntu20.04-sagemaker",
To keep myself sane, I use Airflow to automate tasks with simple, reusable pieces of code for frequently repeated elements of projects, for example: Web scraping ETL Database management Feature building and data validation And much more! link] We finally have the definition of the DAG. It’s a lot of stuff to stay on top of, right?
Unlike traditional data warehouses or relational databases, data lakes accept data from a variety of sources, without the need for prior data transformation or schema definition. Automated Testing and Validation: Automated testing and validation procedures help detect and rectify any anomalies or inconsistencies resulting from data changes.
In this post, The Very Group shows how they use Amazon Comprehend to add a further layer of automated defense on top of policies to design threat modelling into all systems, to prevent PII from being sent in log data to Elasticsearch for indexing. Overview of solution.
Machine Learning Operations (MLOps): Overview, Definition, and Architecture” By Dominik Kreuzberger, Niklas Kühl, Sebastian Hirschl Great stuff. If you haven’t read it yet, definitely do so. Founded neptune.ai , a modular MLOps component for ML metadata store , aka “experiment tracker + model registry”. Came to ML from software.
Our goal was to automate the process of extracting complex information from extensive legal PDFs, freeing up the bank’s subject matter experts (SMEs) to concentrate on the more enjoyable—and more valuable—parts of their jobs. This helped to better organize the chunks and enhance them with relevant metadata.
Our goal was to automate the process of extracting complex information from extensive legal PDFs, freeing up the bank’s subject matter experts (SMEs) to concentrate on the more enjoyable—and more valuable—parts of their jobs. This helped to better organize the chunks and enhance them with relevant metadata.
In this post, we show how to automate the accounts payable process using Amazon Textract for data extraction. We also provide a reference architecture to build an invoice automation pipeline that enables extraction, verification, archival, and intelligent search. You can visualize the indexed metadata using OpenSearch Dashboards.
Those tools and practices not only help to integrate consecutive steps (see Figure 1) together and make them work smoothly; they also make sure that the whole process is reproducible, automated and properly monitored at each stage – model training as well as model inference. Not the best combination, right?
Model cards are intended to be a single source of truth for business and technical metadata about the model that can reliably be used for auditing and documentation purposes. The model registry supports a hierarchical structure for organizing and storing ML models with model metadata information.
Exposing Anthropic’s Claude 3 Sonnet to multiple CloudFormation templates will allow it to analyze and learn from the structure, resource definitions, parameter configurations, and other essential elements consistently implemented across your organization’s templates. Second, we want to add metadata to the CloudFormation template.
An online store’s full customer service and stock-keeping processes can now be automated. You get to choose which processes are automated. AI creates high-definition images that seem like the originals, reviving photography. This article reviews the best artificial intelligence tools for an online store in 2023.
It also enables operational capabilities including automated testing, conversation analytics, monitoring and observability, and LLM hallucination prevention and detection. “We Leave the four entries for Index Details at their default values (index name, vector field name, metadata field name, and text field name). seconds or less.
Amazon SageMaker Ground Truth significantly reduces the cost and time required for labeling data by integrating human annotators with machine learning to automate the labeling process. You can call the SageMaker ListWorkteams or DescribeWorkteam APIs to view workteams’ metadata, including the WorkerAccessConfiguration.
RallyPoint has identified the transition period to a civilian career as a major opportunity to improve the quality of life for this population by creating automated and compelling job recommendations. For the definitions of all available offline metrics, refer to Metric definitions. This was stored in S3.
We envision a future where AI seamlessly integrates into our teams’ workflows, automating repetitive tasks, providing intelligent recommendations, and freeing up time for more strategic, high-value interactions. Role context – Start each prompt with a clear role definition.
After the completion of the research phase, the data scientists need to collaborate with ML engineers to create automations for building (ML pipelines) and deploying models into production using CI/CD pipelines. All the produced models and code automation are stored in a centralized tooling account using the capability of a model registry.
Yes, these things are part of any job in technology, and they can definitely be super fun, but you have to be strategic about how you spend your time and always be aware of your value proposition. It includes your data for training, your results from running your models, your artifacts, and important metadata.
This automated solution helps you get started quickly by providing all the code and configuration necessary to generate your unique images—all you need is images of your subject. However, this solution uses the equivalent GUI parameters as a pre-configured TOML file to automate the entire Stable Diffusion XL fine-tuning process.
Moreover, these tools are designed to automate tasks like generating SQL scripts, documenting metadata and others. This automation boosts productivity and also saves time. Data Dictionary A data dictionary is a repository of metadata. It allows users to document and manage metadata efficiently.
SageMaker AutoMLV2 is part of the SageMaker Autopilot suite, which automates the end-to-end machine learning workflow from data preparation to model deployment. All other columns in the dataset are optional and can be used to include additional time-series related information or metadata about each item.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content