This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While there isn’t an authoritative definition for the term, it shares its ethos with its predecessor, the DevOps movement in software engineering: by adopting well-defined processes, modern tooling, and automated workflows, we can streamline the process of moving from development to robust production deployments.
For a long time, there wasn’t a good standard definition of observability that encompassed organizational needs while keeping the spirit of IT monitoring intact. Eventually, the concept of “Observability = Metrics + Traces + Logs” became the de facto definition.
This allows for greater automation and optimization of production processes, leading to increased efficiency, productivity and flexibility in manufacturing. The difference is found in the definition of edge computing, which states that data is analyzed at the source where data is generated. Learn more about Industry 4.0
Unlike traditional systems, which rely on rule-based automation and structured data, agentic systems, powered by large language models (LLMs), can operate autonomously, learn from their environment, and make nuanced, context-aware decisions. Task definition (count_task) This is a task that we want this agent to execute.
It provides constructs to help developers build generative AI applications using pattern-based definitions for your infrastructure. To explore how AI agents can transform your own support operations, refer to Automate tasks in your application using conversational agents. He holds a Master’s in Information Systems.
In this paper, we showcase how to easily deploy a banking application on both IBM Cloud for Financial Services and Satellite , using automated CI/CD/CC pipelines in a common and consistent manner. The latest definitions of vulnerabilities from organizations such as Snyk and the CVE Program are used to track these new issues.
Emerging technologies and trends, such as machine learning (ML), artificial intelligence (AI), automation and generative AI (gen AI), all rely on good data quality. Establishing standardized definitions and control measures builds a solid foundation that evolves as the framework matures.
Integration helps connect, automate and digitally transform businesses. With IBM Cloud Pak® for Integration, organizations are able to unleash their business potential, deliver new experiences, improve customer outcomes and enable automations that can scale across the enterprise.
IBM watsonx.governance is an end-to-end automated AI lifecycle governance toolkit that is built to enable responsible, transparent and explainable AI workflows. This appliance can handle complex use cases out of the box, and it builds the hub-and-spoke framework for centralized management, automation and self-service.
DevOps engineers often use Kubernetes to manage and scale ML applications, but before an ML model is available, it must be trained and evaluated and, if the quality of the obtained model is satisfactory, uploaded to a model registry. This configuration takes the form of a Directed Acyclic Graph (DAG) represented as a JSON pipeline definition.
Definition and Significance in the IT Industry A Cloud Engineer is responsible for building and managing cloud systems that allow businesses to work efficiently without relying on physical storage. Collaborating with DevOps Teams and Software Developers Cloud Engineers work closely with developers to create, test, and improve applications.
One of the few pre-scripted questions I ask in most of the episodes is about the guest’s definition of “hybrid cloud.” It isn’t a surprise that so many of the guests on my podcast work on topics and technologies directly related to cloud. ” The answers have all been comparable.
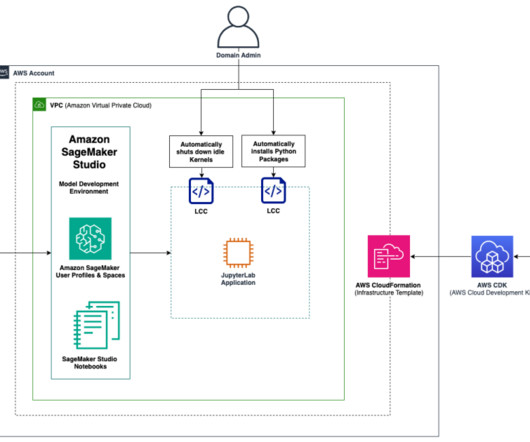
With lifecycle configurations, system administrators can apply automated controls to their SageMaker Studio domains and their users. These automations can greatly decrease overhead related to ML project setup, facilitate technical consistency, and save costs related to running idle instances.
Machine Learning Operations (MLOps): Overview, Definition, and Architecture” By Dominik Kreuzberger, Niklas Kühl, Sebastian Hirschl Great stuff. If you haven’t read it yet, definitely do so. Lived through the DevOps revolution. If you’d like a TLDR, here it is: MLOps is an extension of DevOps. Some are my 3–4 year bets.
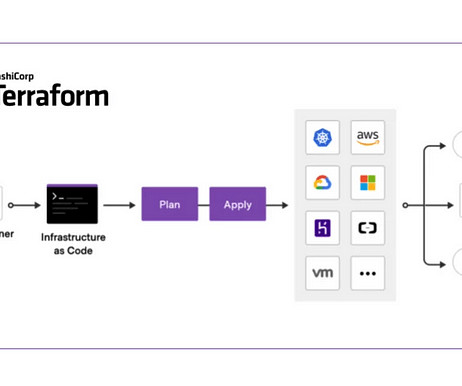
The growing complexity of cloud environments and the demand for faster, more reliable, and reproducible infrastructure management practices highlighted the need for a more efficient solution.Infrastructure-as-code (IaC) is a DevOps practice that uses code to define and deploy infrastructure.
Machine learning operations (MLOps) applies DevOps principles to ML systems. Just like DevOps combines development and operations for software engineering, MLOps combines ML engineering and IT operations. It’s much more than just automation. Only a small fraction of a real-world ML use case comprises the model itself.
It accelerates your generative AI journey from prototype to production because you don’t need to learn about specialized workflow frameworks to automate model development or notebook execution at scale. Download the pipeline definition as a JSON file to your local environment by choosing Export at the bottom of the visual editor.
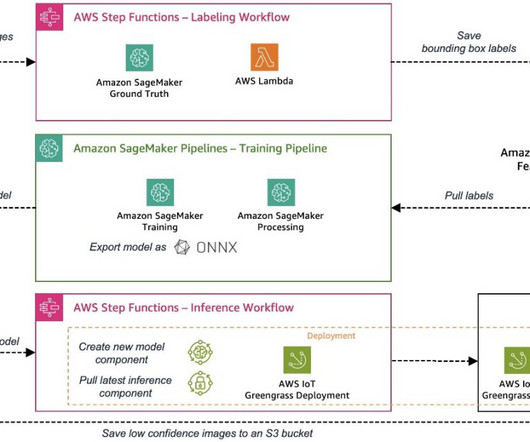
It is architected to automate the entire machine learning (ML) process, from data labeling to model training and deployment at the edge. Automating data labeling Data labeling is an inherently labor-intensive task that involves humans (labelers) to label the data. Let’s look at how to automate model building next!
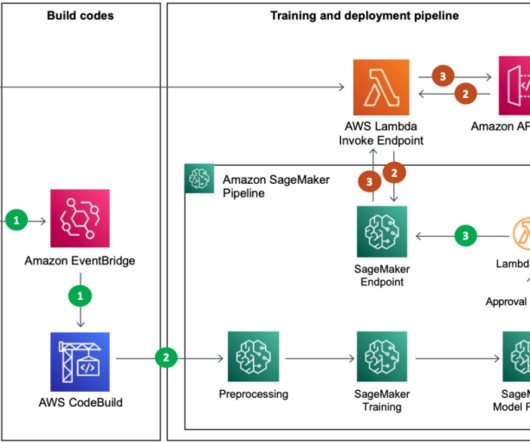
The SageMaker project template includes seed code corresponding to each step of the build and deploy pipelines (we discuss these steps in more detail later in this post) as well as the pipeline definition—the recipe for how the steps should be run. This is made possible by automating tedious, repetitive MLOps tasks as part of the template.
Fact: All teams need access to the observability data The truth is that all teams— DevOps , SRE, Platform, ITOps and Development—need and deserve access to the data they want with the context of logical and physical dependencies across mobile, web, applications and infrastructure.
In this post, we focus on how to automate the edge deployment part of the end-to-end MLOps pipeline. We show you how to use AWS IoT Greengrass to manage model inference at the edge and how to automate the process using AWS Step Functions and other AWS services. If you haven’t read it yet, we recommend checking out Part 1.
This feature streamlines the process of launching new instances with the most up-to-date Neuron SDK, enabling you to automate your deployment workflows and make sure you’re always using the latest optimizations. Amazon ECS configuration For Amazon ECS, create a task definition that references your custom Docker image.
There isn’t one definition of what “the edge” is, it’s actually a spectrum spanning out from the traditional data center or cloud at one end and extending all the way through to highly constrained devices. Many of our customers today run virtualized network functions, along with services like firewalls, SD-WAN, etc. at the edge.
To maintain consistency and expedited deployments, Kate’s code repository is configured to trigger Azure DevOps pipeline builds, which has automation capability to perform all deployment operations. As a result of these changes, the user interface was now modern and intuitive, and the processes were automated and efficient.
In this post, The Very Group shows how they use Amazon Comprehend to add a further layer of automated defense on top of policies to design threat modelling into all systems, to prevent PII from being sent in log data to Elasticsearch for indexing. Overview of solution.
You can move the slider forward and backward to see how this code runs step-by-step: AI Chat for Python Tutors Code Visualizer Way back in 2009 when I was a grad student, I envisioned creating Python Tutor to be an automated tutor that could help students with programming questions (which is why I chose that project name).
As you move from pilot and test phases to deploying generative AI models at scale, you will need to apply DevOps practices to ML workloads. In the notebook, we already added the @step decorator at the beginning of each function definition in the cell where the function was defined, as shown in the following code.
After the completion of the research phase, the data scientists need to collaborate with ML engineers to create automations for building (ML pipelines) and deploying models into production using CI/CD pipelines. All the produced models and code automation are stored in a centralized tooling account using the capability of a model registry.
They presented “Automating Data Quality Remediation With AI” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022. Transparency is a critical ingredient in improving the quality and changing data through automated approaches. Most, most definitely. But the risks are real, and governance is critical to this process.
They presented “Automating Data Quality Remediation With AI” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022. Transparency is a critical ingredient in improving the quality and changing data through automated approaches. Most, most definitely. But the risks are real, and governance is critical to this process.
They presented “Automating Data Quality Remediation With AI” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022. Transparency is a critical ingredient in improving the quality and changing data through automated approaches. Most, most definitely. But the risks are real, and governance is critical to this process.
They provide advanced technology that combines AI-powered automation with human feedback, deep insights, and expertise. Furthermore, DevOps were burdened with manually provisioning GPU instances in response to demand patterns.
In this post, we show how to automate the accounts payable process using Amazon Textract for data extraction. We also provide a reference architecture to build an invoice automation pipeline that enables extraction, verification, archival, and intelligent search. The following figure shows the Step Functions workflow.
Problem definition Traditionally, the recommendation service was mainly provided by identifying the relationship between products and providing products that were highly relevant to the product selected by the customer. For more information about the model, refer to the paper Neural Collaborative Filtering.
While microservices are often talked about in the context of their architectural definition, it can be easier to understand their business value by looking at them through the lens of their most popular enterprise benefits: Change or update code without affecting the rest of an application.
This automated solution helps you get started quickly by providing all the code and configuration necessary to generate your unique images—all you need is images of your subject. However, this solution uses the equivalent GUI parameters as a pre-configured TOML file to automate the entire Stable Diffusion XL fine-tuning process.
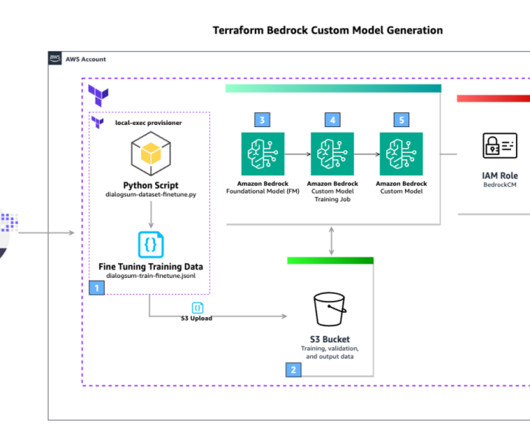
In this post, we provide guidance on how to create an Amazon Bedrock custom model using HashiCorp Terraform that allows you to automate the process, including preparing datasets used for customization. Terraform provides the benefits of automation, versioning, and repeatability. Kevon Mayers is a Solutions Architect at AWS.
Automated retraining mechanism – The training pipeline built with SageMaker Pipelines is triggered whenever a data drift is detected in the inference pipeline. Under Advanced Project Options , for Definition , select Pipeline script from SCM. This will enable us to test the pattern to trigger automated retraining of the model.
The data science team is now expected to be equipped with CI/CD skills to sustain ongoing inference with retraining cycles and automated redeployments of models. Definition of project team users, their roles, and access controls to other resources. Creation of Azure Machine Learning workspaces for the project.
The DevOps and Automation Ops departments are under the infrastructure team. This is the phase where they would expose the MVP with automation and structured engineering code put on top of the experiments they run. “We We are using the internal automation tools we already have to make it easy to show our model endpoints.
AI for DevOps to infuse AI/ML into the entire software development lifecycle to achieve high productivity. Use it to automate development workflows — including machine provisioning, model training and evaluation, comparing ML experiments across project history, and monitoring changing datasets. Do you have legacy notebooks?
Most of those insights have been used to make spaCy better: AI DevOps was hard, so we made sure models could be installed via pip. By definition, you can’t directly control what the process returns. Keeping the issue tracker tidy is something many open source projects struggle with – so automated tools could definitely be helpful.
Definition and Basic Concept of a Hypervisor At its core, a hypervisor acts as a Virtual Machine Monitor (VMM). Containers : Choose containers for lightweight, scalable applications, microservices, and DevOps workflows where rapid deployment is essential.
Mikiko Bazeley: You definitely got the details correct. For me, it was a little bit of a longer journey because I kind of had data engineering and cloud engineering and DevOps engineering in between. I definitely don’t think I’m an influencer. And so what we do is version the definitions. For example, Feast.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content