This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As emerging DevOps trends redefine software development, companies leverage advanced capabilities to speed up their AI adoption. That’s why, you need to embrace the dynamic duo of AI and DevOps to stay competitive and stay relevant. How does DevOps expedite AI? Poor data can distort AI responses.
This isnt automation as weve known itthis is intelligent delegation at enterprise scale. Development assistants (62%) Agents that write, test, and refine code in response to real-time changesstreamlining DevOps workflows. These aren't hypothetical scenarios.
Bisheng also addresses the issue of uneven dataquality within enterprises by providing comprehensive unstructured data governance capabilities, which have been honed over years of experience. The post Bisheng: An Open-Source LLM DevOps Platform Revolutionizing LLM Application Development appeared first on MarkTechPost.
AI quality assurance (QA) uses artificial intelligence to streamline and automate different parts of the software testing process. Machine learning models analyze historical data to detect high-risk areas, prioritize test cases, and optimize test coverage. Automated QA surpasses manual testing by offering up to 90% accuracy.
Access to high-qualitydata can help organizations start successful products, defend against digital attacks, understand failures and pivot toward success. Emerging technologies and trends, such as machine learning (ML), artificial intelligence (AI), automation and generative AI (gen AI), all rely on good dataquality.
Application modernization is the process of updating legacy applications leveraging modern technologies, enhancing performance and making it adaptable to evolving business speeds by infusing cloud native principles like DevOps, Infrastructure-as-code (IAC) and so on.
It serves as the hub for defining and enforcing data governance policies, data cataloging, data lineage tracking, and managing data access controls across the organization. Data lake account (producer) – There can be one or more data lake accounts within the organization.
Automation of building new projects based on the template is streamlined through AWS Service Catalog , where a portfolio is created, serving as an abstraction for multiple products. Monitoring – Continuous surveillance completes checks for drifts related to dataquality, model quality, and feature attribution.
Jacomo Corbo is a Partner and Chief Scientist, and Bryan Richardson is an Associate Partner and Senior Data Scientist, for QuantumBlack AI by McKinsey. They presented “AutomatingDataQuality Remediation With AI” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022.
Jacomo Corbo is a Partner and Chief Scientist, and Bryan Richardson is an Associate Partner and Senior Data Scientist, for QuantumBlack AI by McKinsey. They presented “AutomatingDataQuality Remediation With AI” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022.
Jacomo Corbo is a Partner and Chief Scientist, and Bryan Richardson is an Associate Partner and Senior Data Scientist, for QuantumBlack AI by McKinsey. They presented “AutomatingDataQuality Remediation With AI” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022.
Early and proactive detection of deviations in model quality enables you to take corrective actions, such as retraining models, auditing upstream systems, or fixing quality issues without having to monitor models manually or build additional tooling. Data Scientist with AWS Professional Services. Raju Patil is a Sr.
This includes features for hyperparameter tuning, automated model selection, and visualization of model metrics. Automated pipelining and workflow orchestration: Platforms should provide tools for automated pipelining and workflow orchestration, enabling you to define and manage complex ML pipelines.
After that, I worked for startups for a few years and then spent a decade at Palo Alto Networks, eventually becoming a VP responsible for development, QA, DevOps, and data science. That led me to pursue engineering at Sharif University of Technology in Iran and later get my Ph.D.
TWCo data scientists and ML engineers took advantage of automation, detailed experiment tracking, integrated training, and deployment pipelines to help scale MLOps effectively. Amazon CloudWatch – Collects and visualizes real-time logs that provide the basis for automation. Used to deploy training and inference code.
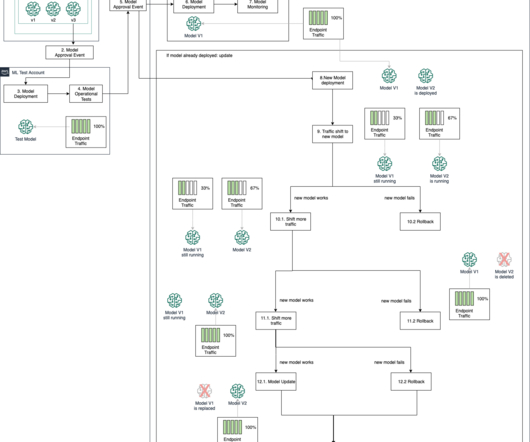
In this post, we describe how to create an MLOps workflow for batch inference that automates job scheduling, model monitoring, retraining, and registration, as well as error handling and notification by using Amazon SageMaker , Amazon EventBridge , AWS Lambda , Amazon Simple Notification Service (Amazon SNS), HashiCorp Terraform, and GitLab CI/CD.
See the following code: # Configure the DataQuality Baseline Job # Configure the transient compute environment check_job_config = CheckJobConfig( role=role_arn, instance_count=1, instance_type="ml.c5.xlarge", These are key files calculated from raw data used as a baseline.
Ensuring dataquality, governance, and security may slow down or stall ML projects. This includes AWS Identity and Access Management (IAM) or single sign-on (SSO) access, security guardrails, Amazon SageMaker Studio provisioning, automated stop/start to save costs, and Amazon Simple Storage Service (Amazon S3) set up.
In the first part of the “Ever-growing Importance of MLOps” blog, we covered influential trends in IT and infrastructure, and some key developments in ML Lifecycle Automation. These agents apply the concept familiar in the DevOps world—to run models in their preferred environments while monitoring all models centrally.
DataQuality and Standardization The adage “garbage in, garbage out” holds true. Inconsistent data formats, missing values, and data bias can significantly impact the success of large-scale Data Science projects. This builds trust in model results and enables debugging or bias mitigation strategies.
Amazon SageMaker for MLOps provides purpose-built tools to automate and standardize steps across the ML lifecycle, including capabilities to deploy and manage new models using advanced deployment patterns. Similar to traditional CI/CD systems, we want to automate software tests, integration testing, and production deployments.
It should be able to version the project assets of your data scientists, such as the data, the model parameters, and the metadata that comes out of your workflow. Automation You want the ML models to keep running in a healthy state without the data scientists incurring much overhead in moving them across the different lifecycle phases.
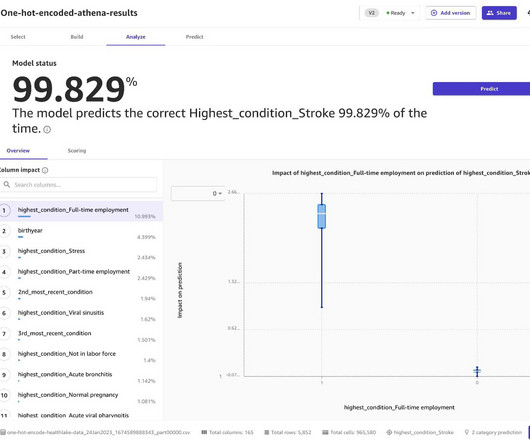
Solution overview This post shows that by anonymizing sensitive data from Amazon HealthLake and making it available to SageMaker Canvas, organizations can empower more stakeholders to use ML models that can generate predictions for multi-modal problems, such as stroke prediction, without writing ML code, while limiting access to sensitive data.
Data & Analytics leaders must count on these trends to plan future strategies and implement the same to make business operations more effective. How can automation transform the business, optimizing resources and driving innovative measures to make business more competitive? Wrapping it up !!!
The advantages of using synthetic data include easing restrictions when using private or controlled data, adjusting the data requirements to specific circumstances that cannot be met with accurate data, and producing datasets for DevOps teams to use for software testing and quality assurance.
Robustness You need an elastic data model to support: Varying team sizes and structures (a single data scientist only, or maybe a team of one data scientist, 4 machine learning engineers, 2 DevOps engineers, etc.). Using the right tools and automation makes it user-friendly and efficient.
The pipelines let you orchestrate the steps of your ML workflow that can be automated. The orchestration here implies that the dependencies and data flow between the workflow steps must be completed in the proper order. Reduce the time it takes for data and models to move from the experimentation phase to the production phase.
Archana Joshi brings over 24 years of experience in the IT services industry, with expertise in AI (including generative AI), Agile and DevOps methodologies, and green software initiatives. They support us by providing valuable insights, automating tasks and keeping us aligned with our strategic goals.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

































Let's personalize your content