This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This advancement has spurred the commercial use of generative AI in natural language processing (NLP) and computer vision, enabling automated and intelligent dataextraction. Businesses can now easily convert unstructured data into valuable insights, marking a significant leap forward in technology integration.
In a world whereaccording to Gartner over 80% of enterprise data is unstructured, enterprises need a better way to extract meaningful information to fuel innovation. With Amazon Bedrock DataAutomation, enterprises can accelerate AI adoption and develop solutions that are secure, scalable, and responsible.
Whether you're leveraging OpenAI’s powerful GPT-4 or with Claude’s ethical design, the choice of LLM API could reshape the future of your business. Why LLM APIs Matter for Enterprises LLM APIs enable enterprises to access state-of-the-art AI capabilities without building and maintaining complex infrastructure.
Traditional methods for handling such data are either too slow, require extensive manual work, or are not flexible enough to adapt to the wide variety of document types and layouts that businesses encounter. Sparrow supports local dataextraction pipelines through advanced machine learning models like Ollama and Apple MLX.
Crawl4AI, an open-source tool, is designed to address the challenge of collecting and curating high-quality, relevant data for training large language models. It not only collects data from websites but also processes and cleans it into LLM-friendly formats like JSON, cleaned HTML, and Markdown.
Despite the availability of technology that can digitize and automate document workflows through intelligent automation, businesses still mostly rely on labor-intensive manual document processing. Intelligent automation presents a chance to revolutionize document workflows across sectors through digitization and process optimization.
Of course, they do have enterprise solutions, but think about itdo you really want to trust third parties with your data? So, lets tackle the nitty gritty of combining the efficiency of automation with the security of local deployment. If not, on-premises AI is by far the best solution, and what were tackling today.
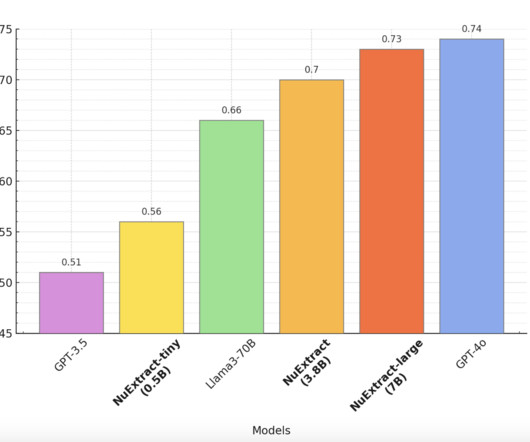
NuMind introduces NuExtract , a cutting-edge text-to-JSON language model that represents a significant advancement in structured dataextraction from text. This model aims to transform unstructured text into structured data highly efficiently.
DeepHermes 3 Preview (DeepHermes-3-Llama-3-8B-Preview) is the latest iteration in Nous Researchs series of LLMs. As one of the first models to integrate both reasoning-based long-chain thought processing and conventional LLM response mechanisms, DeepHermes 3 marks a significant step in AI model sophistication.
Businesses can benefit greatly from using Reducto to extract value from their unstructured data. Reducto helps companies save time money, and get useful insights by automating and streamlining the dataextraction process.
This groundbreaking API complements the previously launched Agent API, offering a comprehensive solution for autonomous web browsing and dataextraction. Developers expressed the need for a natural language-based web understanding and dataextraction tool to enhance the agent’s capabilities in autonomous web browsing.
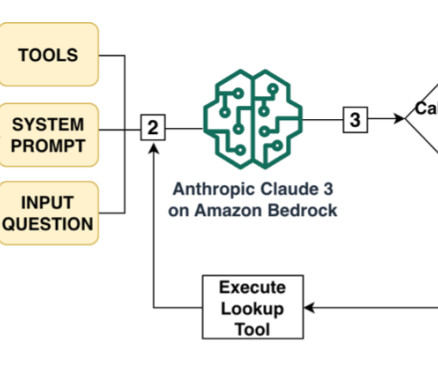
Handling large volumes of data, extracting unstructured data from multiple paper forms or images, and comparing it with the standard or reference forms can be a long and arduous process, prone to errors and inefficiencies. In this post, we explore using the Anthropic Claude 3 on Amazon Bedrock large language model (LLM).
SLK's AI-powered platforms and accelerators are designed to automate and streamline processes, helping businesses reach the market more quickly. These solutions, ranging from data governance to self-service APIs, aim to support the rapid launch of innovations.
Sonnet large language model (LLM) on Amazon Bedrock. For naturalization applications, LLMs offer key advantages. They enable rapid document classification and information extraction, which means easier application filing for the applicant and more efficient application reviewing for the immigration officer.
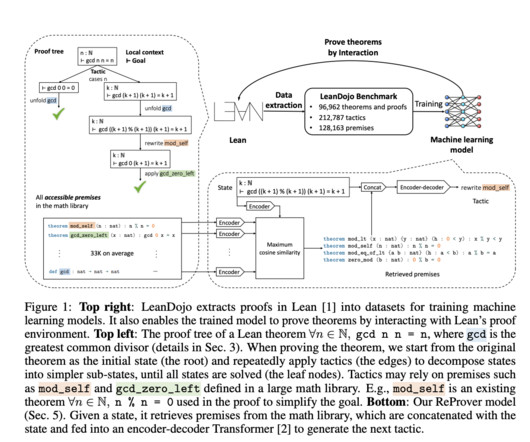
A number of theorems-proving approaches have been researched, such as Automated theorem proving (ATP), which is the process of automatically producing proofs for theorems stated in formal logic. It offers resources for working with Lean and extractingdata.
It offers the capability to quickly identify relevant studies, extract key data, and even apply customizable inclusion and exclusion criteria—all within a seamless, interactive interface. ’ For each data point, you can provide a custom prompt to help the LLM better understand the specific concept that needs to be extracted. .”
The second course, “ChatGPT Advanced Data Analysis,” focuses on automating tasks using ChatGPT's code interpreter. teaches students to automate document handling and dataextraction, among other skills. This 10-hour course, also highly rated at 4.8,
They guide the LLM to generate text in a specific tone, style, or adhering to a logical reasoning pattern, etc. For example, an LLM trained on predominantly European data might overrepresent those perspectives, unintentionally narrowing the scope of information or viewpoints it offers. After the meeting, went back to coding.”
In this blog, we explore how Bright Data’s tools can enhance your data collection process and what the future holds for web data in the context of AI. There are several reasons why this data is crucial for AI development: Diversity: The vast array of content available on the internet spans languages, domains, and perspectives.
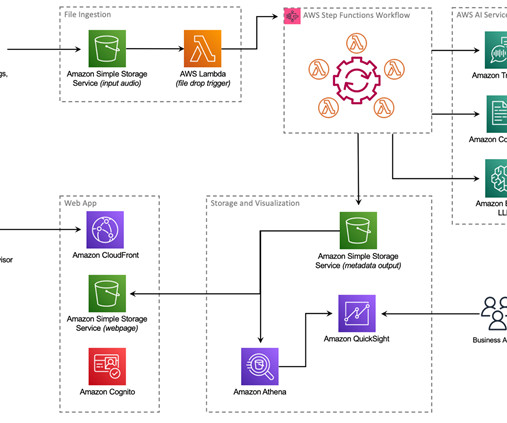
Through Rocket Logic – Synopsis, Rocket achieved remarkable results: automating post call interaction wrap-up resulting in a projected 40,000 team hours saved annually, and a 10% increase in first-call resolutions saved 20,000 hours annually. The following diagram illustrates the solution architecture.
This blog post explores how John Snow Labs Healthcare NLP & LLM library revolutionizes oncology case analysis by extracting actionable insights from clinical text. John Snow Labs , offers a powerful NLP & LLM library tailored for healthcare, empowering professionals to extract actionable insights from medical text.
Better performance and accurate answers for in-context document Q&A and entity extractions using an LLM. There are other possible document automation use cases where Layout can be useful. In the following sections, we discuss how to extract layout elements, and linearize the text to build an LLM-based application.
Traditionally, the extraction of data from documents is manual, making it slow, prone to errors, costly, and challenging to scale. While the industry has been able to achieve some amount of automation through traditional OCR tools, these methods have proven to be brittle, expensive to maintain, and add to technical debt.
Unlock the power of structured dataextraction with LangChain and Claude 3.7 This tutorial focuses on tracing LLM tool calling using LangSmith, enabling real-time debugging and performance monitoring of your extraction system. Sonnet, transforming raw text into actionable insights. Here is the Colab Notebook.
Through its proficient understanding of language and patterns, it can swiftly navigate and comprehend the data, extracting meaningful insights that might have remained hidden by the casual viewer. Imagine equipping generative AI with a dataset rich in information from various sources. All of this goes beyond mere computation.
Tuesday, October 29th Efficient AI Scaling: How VESSL AI Enables 100+ LLM Deployments for $10 and Saves $1M Annually Jaeman An | Electrical and Electronics Engineering | Vessl.ai Delphina Demo: AI-powered Data Scientist Jeremy Hermann | Co-founder at Delphina | Delphina.Ai Learn more about the AI Insight Talks below.
Step 3: Load and process the PDF data For this blog, we will use a PDF file to perform the QnA on it. After extracting the data from the PDF, we’ll use Langchain’s RecursiveCharacterTextSplitter tool to divide the data into smaller chunks suitable for our LLM models. pip install git+[link] !pip
Whether you want to automate research, extract insights from articles, or build AI-powered applications, this tutorial provides a robust and adaptable solution. In conclusion, by combining Firecrawl and Google Gemini, we have created an automated pipeline that scrapes web content and generates meaningful summaries with minimal effort.
This post walks through examples of building information extraction use cases by combining LLMs with prompt engineering and frameworks such as LangChain. We also examine the uplift from fine-tuning an LLM for a specific extractive task. In this example, you explicitly set the instance type to ml.g5.48xlarge.
In this blog post, we will explore ten valuable datasets that can assist you in fine-tuning or training your LLM. Fine-tuning a pre-trained LLM allows you to customize the model’s behavior and adapt it to your specific requirements. Each dataset offers unique features and can enhance your model’s performance. Why Fine-Tune a Model?
This architecture is prevalent in many state-of-the-art LLMs. The encoder processes the input data, extracting semantic representations, while the decoder generates the output based on the encoded information. While avoiding human subjectivity, model evaluation risks compounding biases when using LLMs to evaluate LLMs.
Instead of navigating complex menus or waiting on hold, they can engage in a conversation with a chatbot powered by an LLM. The LLM analyzes the customer’s query, processes the natural language input, and generates a contextual response in real-time. Pythia: Pythia is a vision and language LLM developed by EleutherAI.
By centering the benchmark around these entities, the task ensures that the performance evaluation is directly relevant to the challenges of real-world de-identification, which often involves identifying and obscuring such critical personal data. Its important to note that this pipeline does not rely on any LLM components.
By centering the benchmark around these entities, the task ensures that the performance evaluation is directly relevant to the challenges of real-world deidentification, which often involves identifying and obscuring such critical personal data. Its important to note that this pipeline does not rely on any LLM components.
Extraction with a multi-modal language model The architecture uses a multi-modal LLM to perform extraction of data from various multi-lingual documents. We specifically used the Rhubarb Python framework to extract JSON schema -based data from the documents.
SnapLogic , a leader in generative integration and automation, has introduced the industry’s first low-code generative AI development platform, Agent Creator , designed to democratize AI capabilities across all organizational levels. LLM Snap Pack – Facilitates interactions with Claude and other language models. Not anymore!
At its core, Open Contracts leverages generative AI (genAI) and Large Language Models (LLMs) to facilitate both dataextraction and query handling. Another highlight is the pluggable microservice analyzer architecture, enabling seamless integration of various analyzers to automate document annotation.
The potential of LLMs, in the field of pathology goes beyond automatingdata analysis. Furthermore the use of LLMs in pathology is not limited to enhancing precision. Here, we delve into specific case studies and applications that illustrate the profound impact of LLMs in real-world settings.
As CDOs prepare for more complexity and are tasked to do more with less, they must evaluate the data analytics stack to ensure productivity, speed, and flexibility – all at a reasonable cost. Today’s workforce won’t know the right questions to ask of its data feed, or the automation powering it.
Large language models (LLMs) have demonstrated impressive capabilities in natural language understanding and generation across diverse domains as showcased in numerous leaderboards (e.g., HELM , Hugging Face Open LLM leaderboard ) that evaluate them on a myriad of generic tasks. A three-shot prompting strategy is used for this task.
Use case In this example of an insurance assistance chatbot, the customers generative AI application is designed with Amazon Bedrock Agents to automate tasks related to the processing of insurance claims and Amazon Bedrock Knowledge Bases to provide relevant documents. PII Anonymization.
Including how to use LangChain and LLMs for web scraping! Photo by Nathan Dumlao on Unsplash Introduction Web scraping automates the extraction of data from websites using programming or specialized tools. Required for tasks such as market research, data analysis, content aggregation, and competitive intelligence.
The answer lay in using generative AI through Amazon Bedrock Flows, enabling them to build an automated, intelligent request handling system that would transform their client service operations. Path to the solution When evaluating solutions for email triage automation, several approaches appeared viable, each with its own pros and cons.
MSD collaborated with AWS Generative Innovation Center (GenAIIC) to implement a powerful text-to-SQL generative AI solution that streamlines dataextraction from complex healthcare databases. MSD employs numerous analysts and data scientists who analyze databases for valuable insights.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content