This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This advancement has spurred the commercial use of generative AI in natural language processing (NLP) and computer vision, enabling automated and intelligent dataextraction. Businesses can now easily convert unstructured data into valuable insights, marking a significant leap forward in technology integration.
In a world whereaccording to Gartner over 80% of enterprise data is unstructured, enterprises need a better way to extract meaningful information to fuel innovation. With Amazon Bedrock DataAutomation, enterprises can accelerate AI adoption and develop solutions that are secure, scalable, and responsible.
Web automation technologies are vital in streamlining complex tasks that traditionally require human intervention. These technologies automate actions within web-based platforms, enhancing efficiency and scalability across various digital operations. Check out the Paper.
Jay Mishra is the Chief Operating Officer (COO) at Astera Software , a rapidly-growing provider of enterprise-ready data solutions. Data warehousing has evolved quite a bit in the past 20-25 years. There are a lot of repetitive tasks and automation's goal is to help users in front of repetition.
Automating this step and enabling end-to-end decision-making without human intervention poses significant challenges in the current methodologies. The benchmark is built using dataextracted from strategy video games that mimic real-world business situations. how many resources to supply to a factory).
Microsoft’s release of RD-Agent marks a milestone in the automation of research and development (R&D) processes, particularly in data-driven industries. By automating these critical processes, RD-Agent allows companies to maximize their productivity while enhancing the quality and speed of innovations.
Collecting this data can be time-consuming and prone to errors, presenting a significant challenge in data-driven industries. Traditionally, web scraping tools have been utilized to automate the process of dataextraction. Unlike traditional tools, this innovative solution allows users to describe the needed data.
Despite the availability of technology that can digitize and automate document workflows through intelligent automation, businesses still mostly rely on labor-intensive manual document processing. Intelligent automation presents a chance to revolutionize document workflows across sectors through digitization and process optimization.
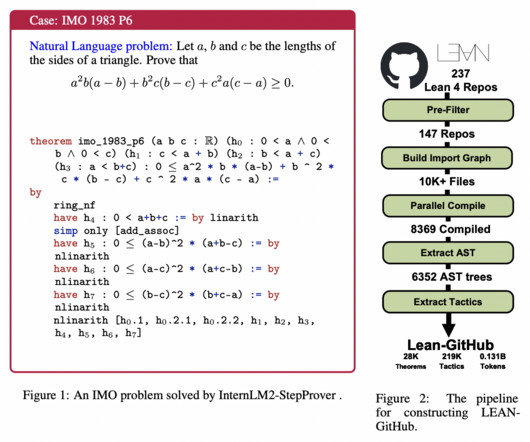
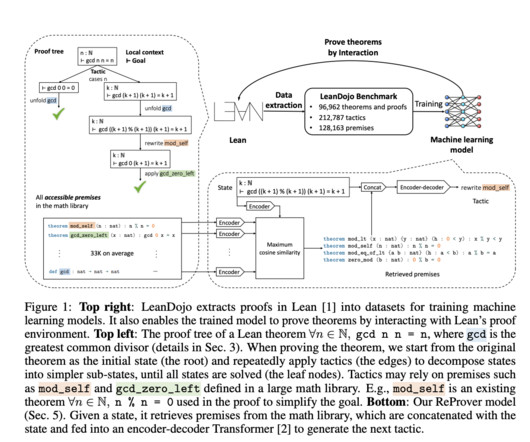
Largelanguagemodels (LLMs) show promise in solving high-school-level math problems using proof assistants, yet their performance still needs to improve due to data scarcity. Formal languages require significant expertise, resulting in limited corpora. Many learning-based systems (e.g.,
A number of theorems-proving approaches have been researched, such as Automated theorem proving (ATP), which is the process of automatically producing proofs for theorems stated in formal logic. It offers resources for working with Lean and extractingdata.
In this evolving market, companies now have more options than ever for integrating largelanguagemodels into their infrastructure. Cost-Efficiency : Avoid the cost of training and maintaining proprietary models by leveraging ready-to-use APIs. Key Features Massive Context Window : Claude 3.0
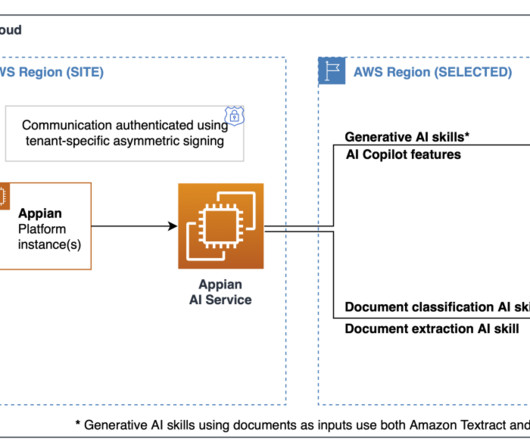
Recognizing the growing complexity of business processes and the increasing demand for automation, the integration of generative AI skills into environments has become essential. Appian has led the charge by offering generative AI skills powered by a collaboration with Amazon Bedrock and Anthropics Claude largelanguagemodels (LLMs).
Prompt engineering is the art and science of crafting inputs (or “prompts”) to effectively guide and interact with generative AI models, particularly largelanguagemodels (LLMs) like ChatGPT. teaches students to automate document handling and dataextraction, among other skills.
Streaming Speech-to-Text : Streaming Speech-to-Text models convert live audio streams, like virtual meetings, into text at high accuracy and low latency. uses AI to power its voice assistant and transcription tools that help automate their users’ workflows. What’s new in Speech AI apps and tools?
While these tools are capable of collecting web data, they often do not format the output in a way that LLMs can easily process. Crawl4AI, an open-source tool, is designed to address the challenge of collecting and curating high-quality, relevant data for training largelanguagemodels.
Enhancing the capabilities of IDP is the integration of generative AI, which harnesses largelanguagemodels (LLMs) and generative techniques to understand and generate human-like text. Solution overview The proposed solution uses Amazon Bedrock and the Amazon Titan Express model to enable IDP functionalities.
Further, the model has an improved function-calling feature that facilitates efficient processing of JSON-structured outputs. This feature makes it ideal for structured dataextraction applications, such as automated financial reporting, customer service automation, and real-time AI-based decision-making systems.
Largelanguagemodels have taken the world by storm, offering impressive capabilities in natural language processing. However, while these models are powerful, they can often benefit from fine-tuning or additional training to optimize performance for specific tasks or domains.
Prepare to be amazed as we delve into the world of LargeLanguageModels (LLMs) – the driving force behind NLP’s remarkable progress. In this comprehensive overview, we will explore the definition, significance, and real-world applications of these game-changing models. What are LargeLanguageModels (LLMs)?
Handling large volumes of data, extracting unstructured data from multiple paper forms or images, and comparing it with the standard or reference forms can be a long and arduous process, prone to errors and inefficiencies. In this post, we explore using the Anthropic Claude 3 on Amazon Bedrock largelanguagemodel (LLM).
Sales intelligence platforms make it easier for sales organizations to automatically compile data, extract insights from that data, and drive efficiency in their operation. This gives sales teams insights into how a potential customer feels about a product, service, or brand, enabling them to tailor their approach accordingly.
Artificial intelligence (AI) is a game-changer in the automation of these mundane tasks. By leveraging AI, organizations can automate the extraction and interpretation of information from documents to focus more on their core activities. Initially, businesses relied on basic automation tools that could only perform simple tasks.
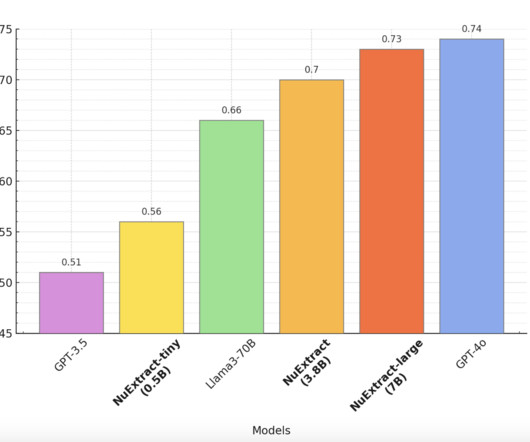
NuMind introduces NuExtract , a cutting-edge text-to-JSON languagemodel that represents a significant advancement in structured dataextraction from text. This model aims to transform unstructured text into structured data highly efficiently.
This growing prevalence underscores the need for advanced tools to analyze and interpret the vast amounts of clinical data generated in oncology. Relation extraction is used to connect biomarkers to their respective results, enabling a detailed understanding of the role biomarkers play in cancer diagnosis. setInputCol("text").setOutputCol("document")
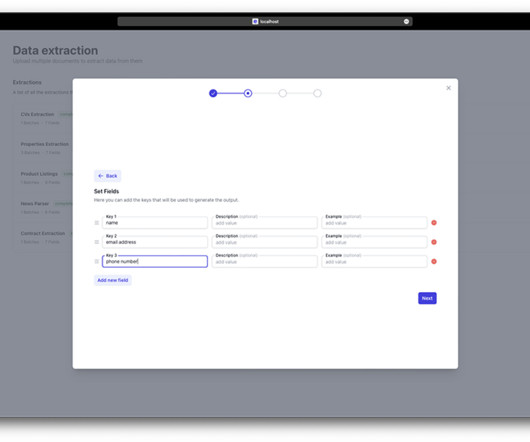
It offers the capability to quickly identify relevant studies, extract key data, and even apply customizable inclusion and exclusion criteria—all within a seamless, interactive interface. ’ For each data point, you can provide a custom prompt to help the LLM better understand the specific concept that needs to be extracted. .”
As businesses and researchers work to advance AI models and LLMs, the demand for high-quality, diverse, and ethically sourced web data is growing rapidly. If you’re working on AI applications or building with largelanguagemodels (LLMs), you already know that access to the right data is crucial.
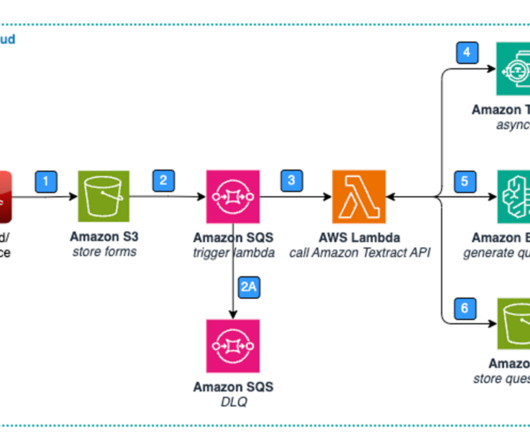
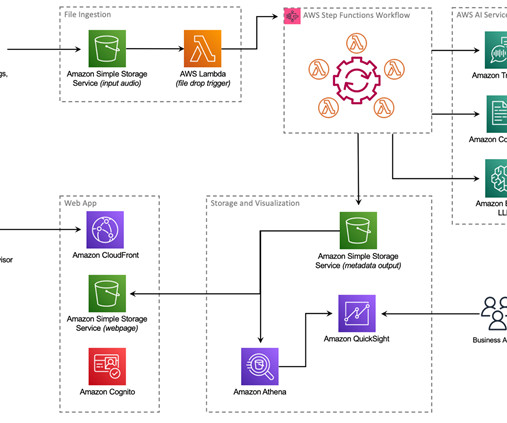
Through Rocket Logic – Synopsis, Rocket achieved remarkable results: automating post call interaction wrap-up resulting in a projected 40,000 team hours saved annually, and a 10% increase in first-call resolutions saved 20,000 hours annually. The following diagram illustrates the solution architecture.
Sonnet largelanguagemodel (LLM) on Amazon Bedrock. They enable rapid document classification and information extraction, which means easier application filing for the applicant and more efficient application reviewing for the immigration officer. For naturalization applications, LLMs offer key advantages.
The ascent of largelanguagemodels, particularly GPT, has marked one of the standout tech trends this year. Companies that have incorporated GPT models into their products have consistently reported heightened competitiveness and enhanced user satisfaction. Do they have a basic understanding of largelanguagemodels?
Through its proficient understanding of language and patterns, it can swiftly navigate and comprehend the data, extracting meaningful insights that might have remained hidden by the casual viewer. Imagine equipping generative AI with a dataset rich in information from various sources. All of this goes beyond mere computation.
The ascent of largelanguagemodels, particularly GPT, has marked one of the standout tech trends this year. Companies that have incorporated GPT models into their products have consistently reported heightened competitiveness and enhanced user satisfaction. Do they have a basic understanding of largelanguagemodels?
Traditionally, the extraction of data from documents is manual, making it slow, prone to errors, costly, and challenging to scale. While the industry has been able to achieve some amount of automation through traditional OCR tools, these methods have proven to be brittle, expensive to maintain, and add to technical debt.
Largelanguagemodels (LLMs) have unlocked new possibilities for extracting information from unstructured text data. Sensitive dataextraction and redaction LLMs show promise for extracting sensitive information for redaction.
From automatic document classification to query generation and automateddataextraction from databases. Alongside the successes, we address the challenges faced during implementation, such as data quality and model training.
These systems are designed to function in dynamic and unpredictable environments, addressing data analysis, process automation, and decision-making tasks. By incorporating advanced frameworks and leveraging largelanguagemodels (LLMs), MAS has increased efficiency and adaptability for various applications.
This AI Insight talk will showcase how VESSL AI enables enterprises to scale the deployment of over 100+ LargeLanguageModels (LLMs) starting at just $10, helping businesses save substantial cloud costs — up to $100K annually. Delphina Demo: AI-powered Data Scientist Jeremy Hermann | Co-founder at Delphina | Delphina.Ai
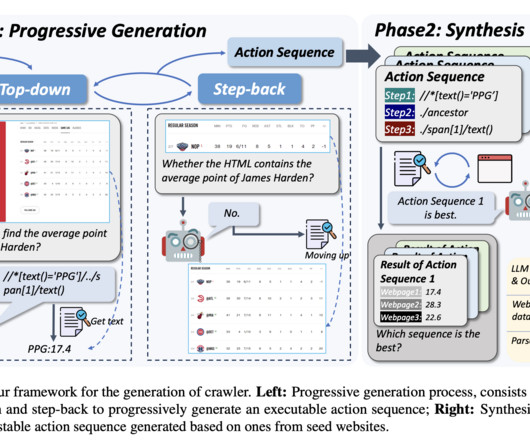
In todays digital landscape, automating interactions with web content remains a nuanced challenge. Developers often face the dual challenge of balancing computational efficiency with the need for a model that can generalize well across diverse websites. VL-3B-Instruct foundation. success rate with an average of 10.3
We also discuss a qualitative study demonstrating how Layout improves generative artificial intelligence (AI) task accuracy for both abstractive and extractive tasks for document processing workloads involving largelanguagemodels (LLMs). There are other possible document automation use cases where Layout can be useful.
Unlock the power of structured dataextraction with LangChain and Claude 3.7 This tutorial focuses on tracing LLM tool calling using LangSmith, enabling real-time debugging and performance monitoring of your extraction system. We’ll use langchain-core and langchain_anthropic to interface with the Claude model.
Just like the mortgage model, largelanguagemodels (LLMs) influence critical decisions, and training them on biased data can perpetuate harmful stereotypes, exclude marginalized voices, or even generate unsafe recommendations. Lets put it this way: some bias is necessary for models to work effectively.
Research And Discovery: Analyzing biomarker dataextracted from large volumes of clinical notes can uncover new correlations and insights, potentially leading to the identification of novel biomarkers or combinations with diagnostic or prognostic value.
Regularly updated and built with cutting-edge algorithms, the Healthcare library aims to streamline information processing and empower healthcare professionals with deeper insights from unstructured medical data sources, such as electronic health records, clinical notes, and biomedical literature.
Modeling Dimension Transformer-based Encoder-Decoder Architecture: At its core, Gemini 1.5 The encoder processes the input data, extracting semantic representations, while the decoder generates the output based on the encoded information. leverages a standard Transformer-based encoder-decoder architecture.
Regularly updated and built with cutting-edge algorithms, the Healthcare library aims to streamline information processing and empower healthcare professionals with deeper insights from unstructured medical data sources, such as electronic health records, clinical notes, and biomedical literature.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content