This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
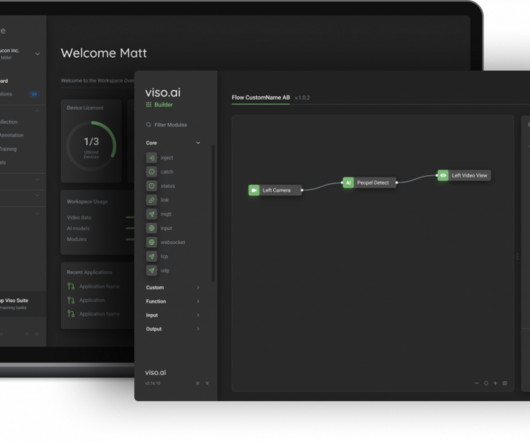
Two of the most important concepts underlying this area of study are concept drift vs datadrift. In most cases, this necessitates updating the model to account for this “model drift” to preserve accuracy. Find out how Viso Suite can automate your team’s projects by booking a demo.
The SageMaker project template includes seed code corresponding to each step of the build and deploy pipelines (we discuss these steps in more detail later in this post) as well as the pipeline definition—the recipe for how the steps should be run. This is made possible by automating tedious, repetitive MLOps tasks as part of the template.
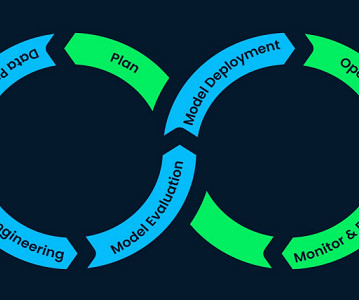
Building out a machine learning operations (MLOps) platform in the rapidly evolving landscape of artificial intelligence (AI) and machine learning (ML) for organizations is essential for seamlessly bridging the gap between data science experimentation and deployment while meeting the requirements around model performance, security, and compliance.
Inadequate Monitoring : Neglecting to monitor user interactions and datadrifts hampers insights into product adoption and long-term performance. Clear definitions of scope and expectations minimized iterative inefficiencies. Use it for early understanding and to refine automated pipelines.
A well-implemented MLOps process not only expedites the transition from testing to production but also offers ownership, lineage, and historical data about ML artifacts used within the team. For the customer, this helps them reduce the time it takes to bootstrap a new data science project and get it to production. The typical score.py
The objective of an ML Platform is to automate repetitive tasks and streamline the processes starting from data preparation to model deployment and monitoring. When you look at the end-to-end journey of an eCommerce platform, you will find there are plenty of components where data is generated.
Automation : Automating as many tasks to reduce human error and increase efficiency. Collaboration : Ensuring that all teams involved in the project, including data scientists, engineers, and operations teams, are working together effectively. But we chose not to go with the same in our deployment due to a couple of reasons.
The DevOps and Automation Ops departments are under the infrastructure team. This is the phase where they would expose the MVP with automation and structured engineering code put on top of the experiments they run. “We We are using the internal automation tools we already have to make it easy to show our model endpoints.
What we are seeing is access to quality datasets is always challenging, but are there best practices to achieve meaningful results with limited labeled data or low access to quality data? I’ve been a part of projects where we’ve spent an incredible amount of money just trying to collect a small amount of data.
What we are seeing is access to quality datasets is always challenging, but are there best practices to achieve meaningful results with limited labeled data or low access to quality data? I’ve been a part of projects where we’ve spent an incredible amount of money just trying to collect a small amount of data.
What we are seeing is access to quality datasets is always challenging, but are there best practices to achieve meaningful results with limited labeled data or low access to quality data? I’ve been a part of projects where we’ve spent an incredible amount of money just trying to collect a small amount of data.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















Let's personalize your content