This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Its not a choice between better data or better models. The future of AI demands both, but it starts with the data. Why DataQuality Matters More Than Ever According to one survey, 48% of businesses use big data , but a much lower number manage to use it successfully. Why is this the case?
Dataquality is of paramount importance at Uber, powering critical decisions and features. In this blog learn how we automated column-level drift detection in batch datasets at Uber scale, reducing the median time to detect issues in critical datasets by 5X.
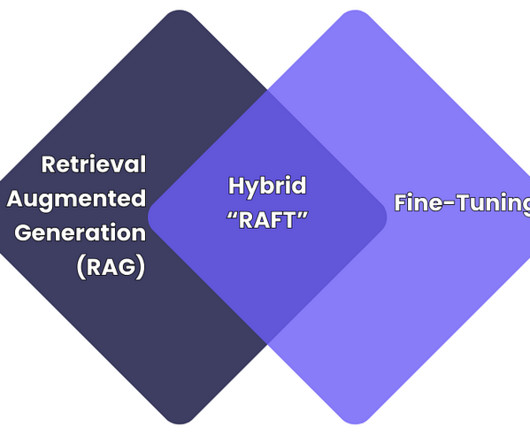
RAFT vs Fine-Tuning Image created by author As the use of large language models (LLMs) grows within businesses, to automate tasks, analyse data, and engage with customers; adapting these models to specific needs (e.g., DataQuality Problem: Biased or outdated training data affects the output. balance, outliers).
Not surprisingly, dataquality and drifting is incredibly important. Many datadrift error translates into poor performance of ML models which are not detected until the models have ran. A recent study of datadrift issues at Uber reveled a highly diverse perspective.
If the model performs acceptably according to the evaluation criteria, the pipeline continues with a step to baseline the data using a built-in SageMaker Pipelines step. For the datadrift Model Monitor type, the baselining step uses a SageMaker managed container image to generate statistics and constraints based on your training data.
Automation of building new projects based on the template is streamlined through AWS Service Catalog , where a portfolio is created, serving as an abstraction for multiple products. Monitoring – Continuous surveillance completes checks for drifts related to dataquality, model quality, and feature attribution.
This includes features for hyperparameter tuning, automated model selection, and visualization of model metrics. Automated pipelining and workflow orchestration: Platforms should provide tools for automated pipelining and workflow orchestration, enabling you to define and manage complex ML pipelines.
Many tools and techniques are available for ML model monitoring in production, such as automated monitoring systems, dashboarding and visualization, and alerts and notifications. Datadrift refers to a change in the input data distribution that the model receives.
Discuss with stakeholders how accuracy and datadrift will be monitored. Data aggregation such as from hourly to daily or from daily to weekly time steps may also be required. Perform dataquality checks and develop procedures for handling issues. Select, train, and automate multiple machine learning models.
For instance, a notebook that monitors for model datadrift should have a pre-step that allows extract, transform, and load (ETL) and processing of new data and a post-step of model refresh and training in case a significant drift is noticed. Run the notebooks The sample code for this solution is available on GitHub.
In this post, we describe how to create an MLOps workflow for batch inference that automates job scheduling, model monitoring, retraining, and registration, as well as error handling and notification by using Amazon SageMaker , Amazon EventBridge , AWS Lambda , Amazon Simple Notification Service (Amazon SNS), HashiCorp Terraform, and GitLab CI/CD.
As a result of these technological advancements, the manufacturing industry has set its sights on artificial intelligence and automation to enhance services through efficiency gains and lowering operational expenses. These initiatives utilize interconnected devices and automated machines that create a hyperbolic increase in data volumes.
Model Drift and DataDrift are two of the main reasons why the ML model's performance degrades over time. To solve these issues, you must continuously train your model on the new data distribution to keep it up-to-date and accurate. DataDriftDatadrift occurs when the distribution of input data changes over time.
Ensuring dataquality, governance, and security may slow down or stall ML projects. This includes AWS Identity and Access Management (IAM) or single sign-on (SSO) access, security guardrails, Amazon SageMaker Studio provisioning, automated stop/start to save costs, and Amazon Simple Storage Service (Amazon S3) set up.
” We will cover the most important model training errors, such as: Overfitting and Underfitting Data Imbalance Data Leakage Outliers and Minima Data and Labeling Problems DataDrift Lack of Model Experimentation About us: At viso.ai, we offer the Viso Suite, the first end-to-end computer vision platform.
In the first part of the “Ever-growing Importance of MLOps” blog, we covered influential trends in IT and infrastructure, and some key developments in ML Lifecycle Automation. DataRobot MLOps counters potential delays with a management system that automates key processes. DataRobot’s Robust ML Offering.
This is where the DataRobot AI platform can help automate and accelerate your process from data to value, even in a scalable environment. Let’s run through the process and see exactly how you can go from data to predictions. Prepare your data for Time Series Forecasting. DataRobot Blueprint—from data to predictions.
Valuable data, needed to train models, is often spread across the enterprise in documents, contracts, patient files, and email and chat threads and is expensive and arduous to curate and label. Inevitably concept and datadrift over time cause degradation in a model’s performance.
Valuable data, needed to train models, is often spread across the enterprise in documents, contracts, patient files, and email and chat threads and is expensive and arduous to curate and label. Inevitably concept and datadrift over time cause degradation in a model’s performance.
How Vodafone Uses Data Contracts Utilizing such a Data Contract, both in training and prediction pipelines, we can detect and diagnose issues such as outliers, inconsistencies, and errors in the data before they can cause problems with the models. Another great use of using Data Contracts is that it helps us detect datadrift.
Automation : Automating as many tasks to reduce human error and increase efficiency. Collaboration : Ensuring that all teams involved in the project, including data scientists, engineers, and operations teams, are working together effectively. This includes dataquality, privacy, and compliance.
Summary: AI in Time Series Forecasting revolutionizes predictive analytics by leveraging advanced algorithms to identify patterns and trends in temporal data. By automating complex forecasting processes, AI significantly improves accuracy and efficiency in various applications. databases, APIs, CSV files).
This provides data scientists with a unified view of the data and helps them decide how the model should be trained, values for hyperparameters, etc. DataQuality Check: As the data flows through the integration step, ETL pipelines can then help improve the quality of data by standardizing, cleaning, and validating it.
Organizations struggle in multiple aspects, especially in modern-day data engineering practices and getting ready for successful AI outcomes. One of them is that it is really hard to maintain high dataquality with rigorous validation. The second is that it can be really hard to classify and catalog data assets for discovery.
Organizations struggle in multiple aspects, especially in modern-day data engineering practices and getting ready for successful AI outcomes. One of them is that it is really hard to maintain high dataquality with rigorous validation. The second is that it can be really hard to classify and catalog data assets for discovery.
Organizations struggle in multiple aspects, especially in modern-day data engineering practices and getting ready for successful AI outcomes. One of them is that it is really hard to maintain high dataquality with rigorous validation. The second is that it can be really hard to classify and catalog data assets for discovery.
Kishore will then double click into some of the opportunities we find here at Capital One, and Bayan will finish us off with a lean into one of our open-source solutions that really is an important contribution to our data-centric AI community. How are you looking at model evaluation for cases where data adapts rapidly?
Kishore will then double click into some of the opportunities we find here at Capital One, and Bayan will finish us off with a lean into one of our open-source solutions that really is an important contribution to our data-centric AI community. How are you looking at model evaluation for cases where data adapts rapidly?
The pipelines let you orchestrate the steps of your ML workflow that can be automated. The orchestration here implies that the dependencies and data flow between the workflow steps must be completed in the proper order. Reduce the time it takes for data and models to move from the experimentation phase to the production phase.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content