This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Sweenor As artificial intelligence (AI) becomes ubiquitous, it’s reshaping decision-making in ways that go far beyond the scope of traditional business automation. What makes AI governance different from data governance? Photo by author David E.
Data quality is of paramount importance at Uber, powering critical decisions and features. In this blog learn how we automated column-level drift detection in batch datasets at Uber scale, reducing the median time to detect issues in critical datasets by 5X.
Data validation frameworks play a crucial role in maintaining dataset integrity over time. Automated tools such as TensorFlow Data Validation (TFDV) and Great Expectations help enforce schema consistency, detect anomalies, and monitor datadrift. AI-assisted dataset optimization represents another frontier.
Instead, businesses tend to rely on advanced tools and strategies—namely artificial intelligence for IT operations (AIOps) and machine learning operations (MLOps)—to turn vast quantities of data into actionable insights that can improve IT decision-making and ultimately, the bottom line.
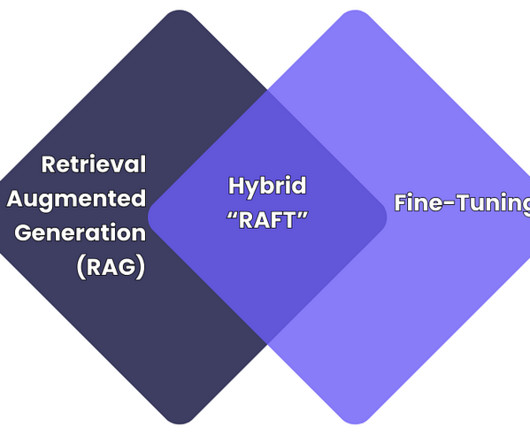
RAFT vs Fine-Tuning Image created by author As the use of large language models (LLMs) grows within businesses, to automate tasks, analyse data, and engage with customers; adapting these models to specific needs (e.g., Data Quality Problem: Biased or outdated training data affects the output. balance, outliers).
At least know the best practices of continuous integration and delivery (CI/CD) processes using GitHub for version control, YAML files for build automation etc. Tools like Google Cloud Monitoring, logging frameworks, and artifact management systems are essential for maintaining reliability and transparency.
Two of the most important concepts underlying this area of study are concept drift vs datadrift. In most cases, this necessitates updating the model to account for this “model drift” to preserve accuracy. Find out how Viso Suite can automate your team’s projects by booking a demo.
Not surprisingly, data quality and drifting is incredibly important. Many datadrift error translates into poor performance of ML models which are not detected until the models have ran. A recent study of datadrift issues at Uber reveled a highly diverse perspective.
Challenges In this section, we discuss challenges around various data sources, datadrift caused by internal or external events, and solution reusability. For example, Amazon Forecast supports related time series data like weather, prices, economic indicators, or promotions to reflect internal and external related events.
By establishing standardized workflows, automating repetitive tasks, and implementing robust monitoring and governance mechanisms, MLOps enables organizations to accelerate model development, improve deployment reliability, and maximize the value derived from ML initiatives.
Artificial intelligence (AI) and machine learning (ML) offerings from Amazon Web Services (AWS) , along with integrated monitoring and notification services, help organizations achieve the required level of automation, scalability, and model quality at optimal cost.
The Problems in Production Data & AI Model Output Building robust AI systems requires a thorough understanding of the potential issues in production data (real-world data) and model outcomes. Model Drift: The model’s predictive capabilities and efficiency decrease over time due to changing real-world environments.
A prerequisite in measuring a deployed model’s evolving performance is to collect both its input data and business outcomes in a deployed setting. With this data in hand, we are able to measure both the datadrift and model performance, both of which are essential metrics in measuring the health of the deployed model.
If the model performs acceptably according to the evaluation criteria, the pipeline continues with a step to baseline the data using a built-in SageMaker Pipelines step. For the datadrift Model Monitor type, the baselining step uses a SageMaker managed container image to generate statistics and constraints based on your training data.
You need full visibility and automation to rapidly correct your business course and to reflect on daily changes. Imagine yourself as a pilot operating aircraft through a thunderstorm; you have all the dashboards and automated systems that inform you about any risks. See DataRobot MLOps in Action. Request a Demo.
Introduction Deepchecks is a groundbreaking open-source Python package that aims to simplify and enhance the process of implementing automated testing for machine learning (ML) models. With Deepchecks, developers can start incorporating automated testing early in their workflow and gradually build up their test suites as they go.
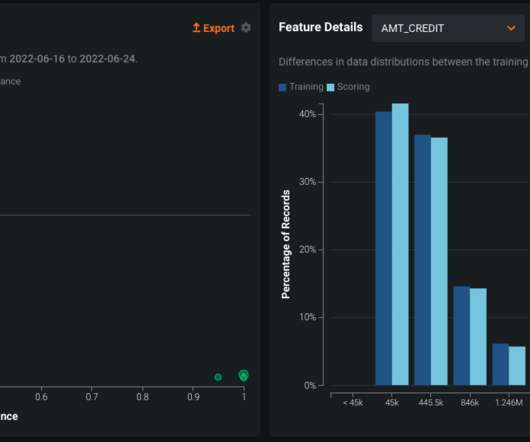
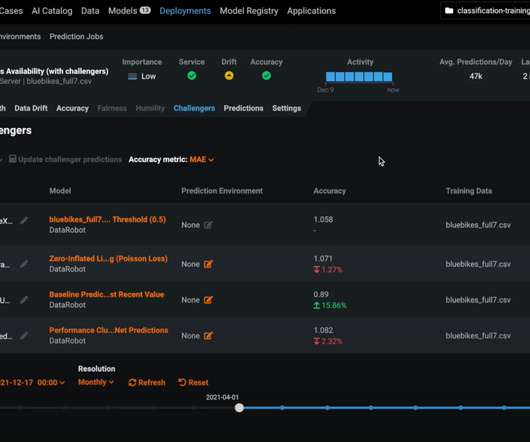
Knowing this, we walked through a demo of DataRobot AI Cloud MLOps solution , which can manage the open-source models developed by the retailer and regularly provide metrics such as service health, datadrift and changes in accuracy. Accelerating Value-Realization with Industry Specific Use Cases.
Automation levels The SAE International (formerly called as Society of Automotive Engineers) J3016 standard defines six levels of driving automation, and is the most cited source for driving automation. This ranges from Level 0 (no automation) to Level 5 (full driving automation), as shown in the following table.
That’s the datadrift problem, aka the performance drift problem. The other big challenge, especially as you move to more and more automated, tighter and tighter, and shorter and shorter feedback cycles for continual learning is to make sure that you have a systematic evaluation framework in place.
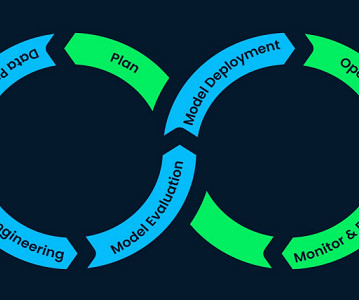
Building out a machine learning operations (MLOps) platform in the rapidly evolving landscape of artificial intelligence (AI) and machine learning (ML) for organizations is essential for seamlessly bridging the gap between data science experimentation and deployment while meeting the requirements around model performance, security, and compliance.
Many tools and techniques are available for ML model monitoring in production, such as automated monitoring systems, dashboarding and visualization, and alerts and notifications. Datadrift refers to a change in the input data distribution that the model receives.
As a result of these technological advancements, the manufacturing industry has set its sights on artificial intelligence and automation to enhance services through efficiency gains and lowering operational expenses. These initiatives utilize interconnected devices and automated machines that create a hyperbolic increase in data volumes.
This includes features for hyperparameter tuning, automated model selection, and visualization of model metrics. Automated pipelining and workflow orchestration: Platforms should provide tools for automated pipelining and workflow orchestration, enabling you to define and manage complex ML pipelines.
Discuss with stakeholders how accuracy and datadrift will be monitored. Select, train, and automate multiple machine learning models. Incorporate methodologies to address model drift and datadrift. Predictions can be made in batches or in real time. Plan for ongoing maintenance and enhancement.
Automation of building new projects based on the template is streamlined through AWS Service Catalog , where a portfolio is created, serving as an abstraction for multiple products. This is made possible by automating tedious, repetitive MLOps tasks as part of the template. Alerts are raised whenever anomalies are detected.
For instance, a notebook that monitors for model datadrift should have a pre-step that allows extract, transform, and load (ETL) and processing of new data and a post-step of model refresh and training in case a significant drift is noticed.
Model Drift and DataDrift are two of the main reasons why the ML model's performance degrades over time. To solve these issues, you must continuously train your model on the new data distribution to keep it up-to-date and accurate. DataDriftDatadrift occurs when the distribution of input data changes over time.
Leveraging DataRobot’s JDBC connectors, enterprise teams can work together to train ML models on their data residing in SAP HANA Cloud and SAP Data Warehouse Cloud, as well as have an option to enrich it with data from external data sources.
” We will cover the most important model training errors, such as: Overfitting and Underfitting Data Imbalance Data Leakage Outliers and Minima Data and Labeling Problems DataDrift Lack of Model Experimentation About us: At viso.ai, we offer the Viso Suite, the first end-to-end computer vision platform.
Build systems and processes to help automate assessment, such as unit tests, datasets, and product feedback hooks. By contrast: ML-powered software introduces uncertainty due to real-world entropy (datadrift, model drift), making testing probabilistic rather than deterministic. Evaluation : Same as above.
The automated deployment pushes trained models as Java UDFs, running scalable inference inside Snowflake, and leveraging Snowpark to score the data for speed and elasticity, while keeping data in place. Learn more about the new monitoring job and automated deployment. launch event on March 16th.
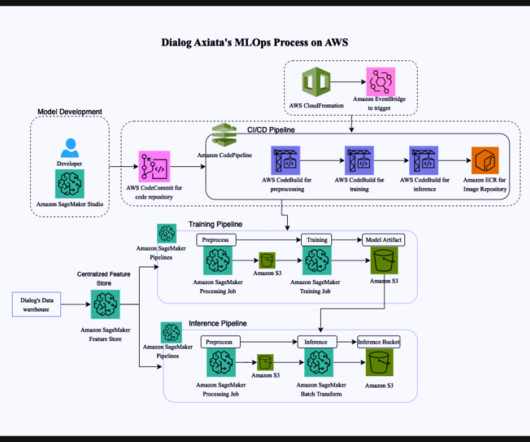
This includes AWS Identity and Access Management (IAM) or single sign-on (SSO) access, security guardrails, Amazon SageMaker Studio provisioning, automated stop/start to save costs, and Amazon Simple Storage Service (Amazon S3) set up. MLOps engineering – Focuses on automating the DevOps pipelines for operationalizing the ML use case.
By conducting experiments within these automated pipelines, significant cost savings could be achieved. The incorporation of an experiment tracking system facilitates the monitoring of performance metrics, enabling a data-driven approach to decision-making. Datadrift and model drift are also monitored.
The DataRobot AI platform allows users with different skill sets across data analytics, data science, lines of business, and IT to experiment at scale and automate the mundane, management tasks of updating, while allowing teams to focus on their core expertise.
These features make automated computer vision trained via supervised learning against expertly annotated datasets an attractive choice for satellite object detection. Data-flow depiction of a real-time streaming computer vision service for vessel detection in satellite imagery. mechanical turk is not an option).
In the first part of the “Ever-growing Importance of MLOps” blog, we covered influential trends in IT and infrastructure, and some key developments in ML Lifecycle Automation. DataRobot MLOps counters potential delays with a management system that automates key processes. DataRobot’s Robust ML Offering.
And sensory gating causes our brains to filter out information that isn’t novel, resulting in a failure to notice gradual datadrift or slow deterioration in system accuracy. With DataRobot MLOps , you already have automated monitoring with a notification system.
Traceability requirements require the creation of records that show who called out what data, when, and why. Solution: MLOps provides version control, automated documentation, and lineage tracking for all production models. Continuous learning requires: Adopting automated strategies that keep production models at peak performance.
A well-implemented MLOps process not only expedites the transition from testing to production but also offers ownership, lineage, and historical data about ML artifacts used within the team. For the customer, this helps them reduce the time it takes to bootstrap a new data science project and get it to production. The typical score.py
In this example, we take a deep dive into how real estate companies can effectively use AI to automate their investment strategies. Let’s take a look at an example use case, which showcases the effective use of AI to automate strategic decisions and explores the collaboration capabilities enabled by the DataRobot AI platform.
I’m also excited to spread the word about some of the latest enhancements and integrations between Datarobot’s AI Cloud and Snowflake’s Data Cloud. These include scoring code, prediction explanations, telemetry feedback, and automated feature discovery. For example, your data may have valid value ranges. Scoring code.
Inadequate Monitoring : Neglecting to monitor user interactions and datadrifts hampers insights into product adoption and long-term performance. Use it for early understanding and to refine automated pipelines. Real-World Application: Text-to-SQL in Healthcare In his talk, Noe provided a real-world case study on the issue.
With an intuitive interface and out-of-the-box components, you can reach your goals and be efficient without deep data science expertise or coding skills. At the same time, advanced data scientists interested in experimenting or bringing their own models and leveraging automation can easily do this, too.
This is where the DataRobot AI platform can help automate and accelerate your process from data to value, even in a scalable environment. Let’s run through the process and see exactly how you can go from data to predictions. DataRobot Blueprint—from data to predictions.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content