

Tennr Secures $37M Series B to Revolutionize Healthcare Document Processing with AI
Unite.AI
OCTOBER 22, 2024
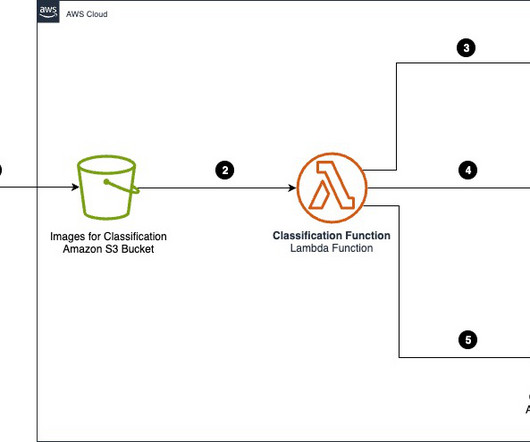
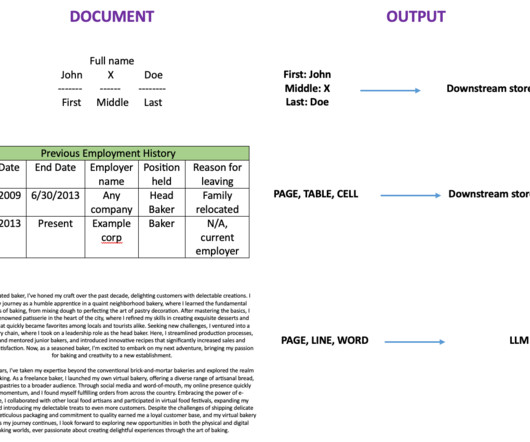
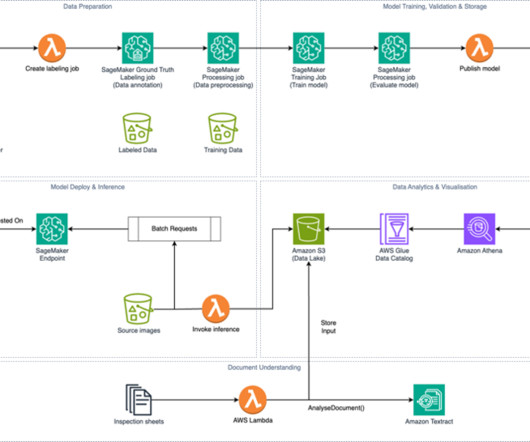
Tennr is using artificial intelligence (AI) to revolutionize how healthcare organizations manage and process the mountains of documents that flow through their practices daily. By automating these critical workflows, Tennr helps practices reduce patient wait times, increase throughput, and improve commercial outcomes.







































Let's personalize your content