This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Discuss with stakeholders how accuracy and datadrift will be monitored. Typical data quality checks and corrections include: Missing data or incomplete records Inconsistent data formatting (e.g., mixture of dollars and euros in a currency field) Inconsistent coding of categoricaldata (e.g.,
If there are features related to network issues, those users are categorized as network issue-based users. The resultant categorization, along with the predicted churn status for each user, is then transmitted for campaign purposes. By conducting experiments within these automated pipelines, significant cost savings could be achieved.
For instance, a notebook that monitors for model datadrift should have a pre-step that allows extract, transform, and load (ETL) and processing of new data and a post-step of model refresh and training in case a significant drift is noticed.
The following can be included as part of your Data Contract: Feature names Data types Expected distribution of values in each column. It can also include constraints on the data, such as: Minimum and maximum values for numerical columns Allowed values for categorical columns.
Ingest your data and DataRobot will use all these data points to train a model—and once it is deployed, your marketing team will be able to get a prediction to know if a customer is likely to redeem a coupon or not and why. All of this can be integrated with your marketing automation application of choice. A look at datadrift.
Data Quality Check: As the data flows through the integration step, ETL pipelines can then help improve the quality of data by standardizing, cleaning, and validating it. This ensures that the data which will be used for ML is accurate, reliable, and consistent. 4 How to create scalable and efficient ETL data pipelines.
But there needs to be some priority order by which we consider how to build a feature library, how to group features and categorize them, and then how to join features at different scales—maybe at a customer scale or at a process level. How are you looking at model evaluation for cases where data adapts rapidly? I can briefly start.
But there needs to be some priority order by which we consider how to build a feature library, how to group features and categorize them, and then how to join features at different scales—maybe at a customer scale or at a process level. How are you looking at model evaluation for cases where data adapts rapidly? I can briefly start.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


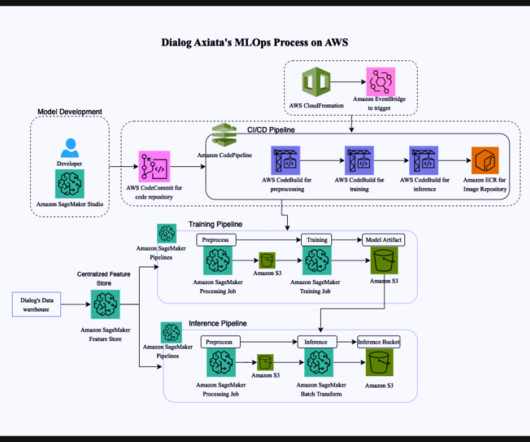


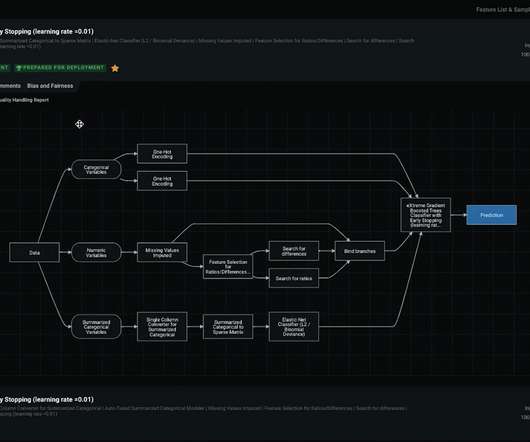









Let's personalize your content