This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In the ever-evolving landscape of artificial intelligence, the art of promptengineering has emerged as a pivotal skill set for professionals and enthusiasts alike. Promptengineering, essentially, is the craft of designing inputs that guide these AI systems to produce the most accurate, relevant, and creative outputs.
Localization relies on both automation and humans-in-the-loop in a process called Machine Translation Post Editing (MTPE). The solution proposed in this post relies on LLMs context learning capabilities and promptengineering. One of LLMs most fascinating strengths is their inherent ability to understand context.
Advantages of adopting generative approaches for NLP tasks For customer feedback analysis, you might wonder if traditional NLP classifiers such as BERT or fastText would suffice. Operational efficiency Uses promptengineering, reducing the need for extensive fine-tuning when new categories are introduced.
Automate tedious, repetitive tasks. The quality of outputs depends heavily on training data, adjusting the model’s parameters and promptengineering, so responsible data sourcing and bias mitigation are crucial. The result will be unusable if a user prompts the model to write a factual news article.
It provides codes for working with various models, such as GPT-4, BERT, T5, etc., The author teaches how we can save time and money and automate repititive tasks using today’s technology. The Art of PromptEngineering with ChatGPT This book teaches the art of working with ChatGPT with the help of promptengineering.
Data scientists and SMEs use this ground truth to guide iterations on the LLM-as-judge prompt template. The team may embed some of the SMEs labels and explanations directly in the template as a form of promptengineering known as few shot learning. Ensure more consistent, automated, and reproducible AI output assessments.
Facebook's RoBERTa, built on the BERT architecture, utilizes deep learning algorithms to generate text based on given prompts. LeewayHertz's ZBrain AI platform revolutionizes manufacturing workflows by optimizing supply chains, improving quality control, streamlining production, and automating supplier evaluations.
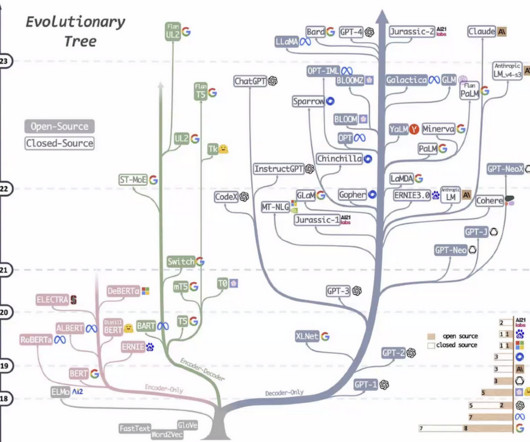
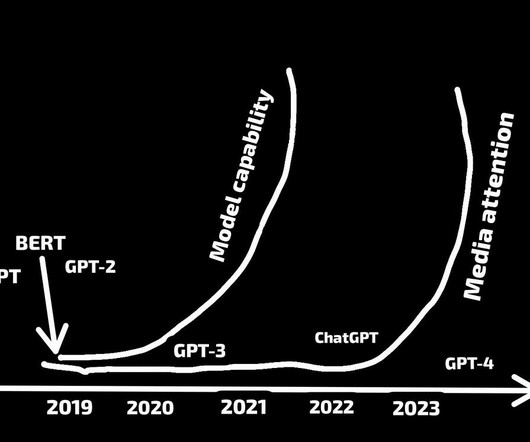
Starting with BERT and accelerating with the launch of GPT-3 , conference sessions on LLMs and transformers skyrocketed. The release of GPT-4 and other advanced LLMs sparked a surge in research on fine-tuning, promptengineering, and the use of LLMs in real-world applications. Whats Next for DataScience?
Promptengineering is crucial to steering LLMs effectively. Techniques like Word2Vec and BERT create embedding models which can be reused. BERT produces deep contextual embeddings by masking words and predicting them based on bidirectional context. LLMs utilize embeddings to understand word context.
The study also identified four essential skills for effectively interacting with and leveraging ChatGPT: promptengineering, critical evaluation of AI outputs, collaborative interaction with AI, and continuous learning about AI capabilities and limitations.
Deep learning techniques can be used to automate processes that ordinarily require human intellect, such as text-to-sound transcription or the description of photographs. Prompts design is a process of creating prompts which are the instructions and context that are given to Large Language Models to achieve the desired task.
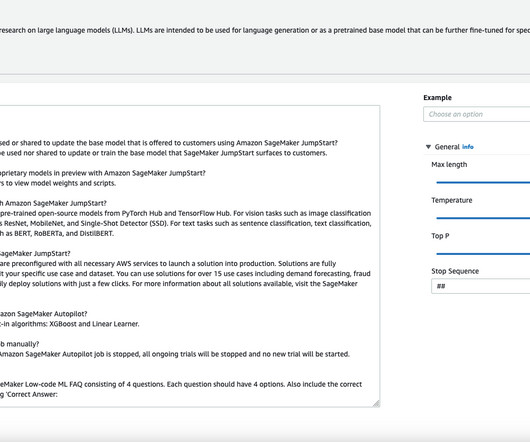
In 2018, BERT-large made its debut with its 340 million parameters and innovative transformer architecture, setting the benchmark for performance on NLP tasks. For text tasks such as sentence classification, text classification, and question answering, you can use models such as BERT, RoBERTa, and DistilBERT.
The entire process can be further automated incorporating automatic image tagging using modules like RAM or Tag2Text. Promptengineering : the provided prompt plays a crucial role, especially when dealing with compound nouns. By using “car lamp” as a prompt, we are very likely to detect cars instead of car lamps.
Industry leaders like Microsoft and Google recognize the importance of LLMs in driving innovation, automation, and enhancing user experiences. This trend started with models like the original GPT and ELMo, which had millions of parameters, and progressed to models like BERT and GPT-2, with hundreds of millions of parameters.
Learn how to refine prompts to boost AI accuracy and effectiveness across various applications. Introduction Artificial Intelligence (AI) is revolutionising various industries by enhancing decision-making and automating complex tasks. Prompt tuning is pivotal.
Promptengineering Let’s start simple. With this in mind, we strongly recommend starting with promptengineering. Tell me what you don’t know When prompting LLMs to solve a chosen problem, we can add an instruction to return an “I don’t know” answer when the model is in doubt.
Users can easily constrain an LLM’s output with clever promptengineering. Developers working on the Snorkel Flow platform only need to consider the prompt template. Other developers may use an automation utility such as LangChain. BERT for misinformation. In-context learning. A GPT-3 model—82.5%
Users can easily constrain an LLM’s output with clever promptengineering. Developers working on the Snorkel Flow platform only need to consider the prompt template. Other developers may use an automation utility such as LangChain. BERT for misinformation. In-context learning. A GPT-3 model—82.5%
Users can easily constrain an LLM’s output with clever promptengineering. Developers working on the Snorkel Flow platform only need to consider the prompt template. Other developers may use an automation utility such as LangChain. BERT for misinformation. In-context learning. A GPT-3 model—82.5%
Large language models, such as GPT-3 (Generative Pre-trained Transformer 3), BERT, XLNet, and Transformer-XL, etc., It has become the backbone of many successful language models, like GPT-3, BERT, and their variants. These automated models produce instantaneous responses with minimal overhead of training time and data requirements.
Reward Model The reward model automates the process of ranking model outputs, reducing the need for human annotators. Promptengineering: Carefully designing prompts to guide the model's behavior. Bidirectional language understanding with BERT. Train a reward model to predict human preferences/rankings.
In this post, we address this challenge by augmenting this workflow with a framework for extensible, automated evaluations. These functions can be implemented in several ways, including BERT-style models, appropriately prompted LLMs, and more. TruLens evaluations use an abstraction of feedback functions.
BERT, the first breakout large language model In 2019, a team of researchers at Goole introduced BERT (which stands for bidirectional encoder representations from transformers). By making BERT bidirectional, it allowed the inputs and outputs to take each others’ context into account. BERT), or consist of both (e.g.,
BERT, the first breakout large language model In 2019, a team of researchers at Goole introduced BERT (which stands for bidirectional encoder representations from transformers). By making BERT bidirectional, it allowed the inputs and outputs to take each others’ context into account. BERT), or consist of both (e.g.,
The emergence of Large Language Models (LLMs) like OpenAI's GPT , Meta's Llama , and Google's BERT has ushered in a new era in this field. Automation is critical, with techniques like pre-trained models, active learning, or weak supervision methods. The focus shifts towards promptengineering and fine-tuning.
It came to its own with the creation of the transformer architecture: Google’s BERT, OpenAI, GPT2 and then 3, LaMDA for conversation, Mina and Sparrow from Google DeepMind. In terms of technology: generating code snippets, code translation, and automated documentation. Then comes promptengineering.
It came to its own with the creation of the transformer architecture: Google’s BERT, OpenAI, GPT2 and then 3, LaMDA for conversation, Mina and Sparrow from Google DeepMind. In terms of technology: generating code snippets, code translation, and automated documentation. Then comes promptengineering.
The entire process can be further automated incorporating automatic image tagging using modules like RAM or Tag2Text. Promptengineering : the provided prompt plays a crucial role, especially when dealing with compound nouns. By using car lamp as a prompt, we are very likely to detect cars instead of car lamps.
BERT and GPT are examples. You can adapt foundation models to downstream tasks in the following ways: PromptEngineering: Promptengineering is a powerful technique that enables LLMs to be more controllable and interpretable in their outputs, making them more suitable for real-world applications with specific requirements and constraints.
This year is intense: we have, among others, a new generative model that beats GANs , an AI-powered chatbot that discusses with more than 1 million people in a week and promptengineering , a job that did not exist a year ago. To cover as many breakthroughs as possible we have broken down our review in four parts: ? What happened?
In short, EDS is the problem of the widespread lack of a rational approach to and methodology for the objective, automated and quantitative evaluation of performance in terms of generative model finetuning and promptengineering for specific downstream GenAI tasks related to practical business applications. Garrido-Merchán E.C.,
Fortunately, we can make the task more accessible through automated model selection methods like neural architecture search (NAS) and hyperparameter optimization. While pre-training a model like BERT from scratch is possible, using an existing model like bert-large-cased · Hugging Face is often more practical, except for specialized cases.
While you will absolutely need to go for this approach if you want to use Text2SQL on many different databases, keep in mind that it requires considerable promptengineering effort. 4] In the open-source camp, initial attempts at solving the Text2SQL puzzle were focussed on auto-encoding models such as BERT, which excel at NLU tasks.[5,
This post is meant to walk through some of the steps of how to take your LLMs to the next level, focusing on critical aspects like LLMOps, advanced promptengineering, and cloud-based deployments. BERT being distilled into DistilBERT) and task-specific distillation which fine-tunes a smaller model using specific task data (e.g.
In this post, we illustrate the importance of generative AI in the collaboration between Tealium and the AWS Generative AI Innovation Center (GenAIIC) team by automating the following: Evaluating the retriever and the generated answer of a RAG system based on the Ragas Repository powered by Amazon Bedrock. or Claude Instant.
To address these challenges and enhance operational efficiency and scalability, many SOCs are increasingly turning to automation technologies to streamline repetitive tasks, prioritize alerts, and accelerate incident response. We used promptengineering guidelines to tailor our prompts to generate better responses from the LLM.
Suddenly, engineers could interact with them simply by prompting, without any initial training. Our platform initially focused on fine-tuning models like BERT in 2021-2022, which were considered large at the time. You can’t justify spending billions on infrastructure to solve relatively simple automation tasks.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content