This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Several research environments have been developed to automate the research process partially. to close the gap between BERT-base and BERT-large performance. This iterative improvement underscores the robustness of DOLPHIN’s design in automating and optimizing the research process. improvement over baseline models.
MLOps are practices that automate and simplify ML workflows and deployments. LLMs are deep neural networks that can generate natural language texts for various purposes, such as answering questions, summarizing documents, or writing code. LLMs can understand the complexities of human language better than other models.
SLIMs join existing small, specialized model families from LLMWare – DRAGON , BLING , and Industry – BERT — along with the LLMWare development framework, to create a comprehensive set of open-source models and data pipelines to address a wide range of complex enterprise RAG use cases.
Speculative decoding applies the principle of speculative execution to LLM inference. The process involves two main components: A smaller, faster "draft" model The larger target LLM The draft model generates multiple tokens in parallel, which are then verified by the target model.
LLM-as-Judge has emerged as a powerful tool for evaluating and validating the outputs of generative models. LLMs (and, therefore, LLM judges) inherit biases from their training data. In this article, well explore how enterprises can leverage LLM-as-Judge effectively , overcome its limitations, and implement best practices.
In the age of data-driven artificial intelligence, LLMs like GPT-3 and BERT require vast amounts of well-structured data from diverse sources to improve performance across various applications. It not only collects data from websites but also processes and cleans it into LLM-friendly formats like JSON, cleaned HTML, and Markdown.
LLM watermarking, which integrates imperceptible yet detectable signals within model outputs to identify text generated by LLMs, is vital for preventing the misuse of large language models. Conversely, the Christ Family alters the sampling process during LLM text generation, embedding a watermark by changing how tokens are selected.
This advancement has spurred the commercial use of generative AI in natural language processing (NLP) and computer vision, enabling automated and intelligent data extraction. Additionally, it poses a security risk when handling sensitive data, making it a less desirable option in the age of automation and digital security.
One of LLMs most fascinating strengths is their inherent ability to understand context. Localization relies on both automation and humans-in-the-loop in a process called Machine Translation Post Editing (MTPE). However, the industry is seeing enough potential to consider LLMs as a valuable option.
Impact of the LLM Black Box Problem 1. Flawed Decision Making The opaqueness in the decision-making process of LLMs like GPT-3 or BERT can lead to undetected biases and errors. For example, a medical diagnosis LLM relying on outdated or biased data can make harmful recommendations.
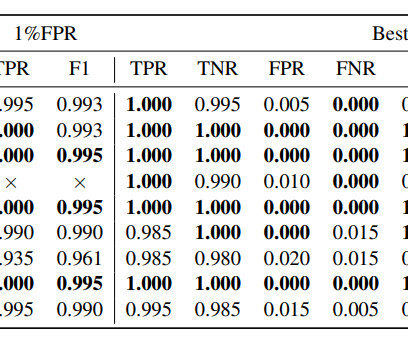
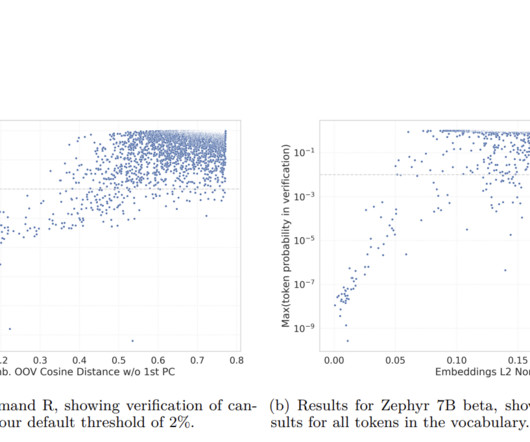
However, these methods are not scalable for the increasingly large and complex LLMs being developed today. Researchers from Cohere introduce a novel approach that utilizes the model’s embedding weights to automate and scale the detection of under-trained tokens. If you like our work, you will love our newsletter.
Whether you’re a developer seeking to incorporate LLMs into your existing systems or a business owner looking to take advantage of the power of NLP, this post can serve as a quick jumpstart. The raw data is processed by an LLM using a preconfigured user prompt. The LLM generates output based on the user prompt.
In this world of complex terminologies, someone who wants to explain Large Language Models (LLMs) to some non-tech guy is a difficult task. So that’s why I tried in this article to explain LLM in simple or to say general language. No training examples are needed in LLM Development but it’s needed in Traditional Development.
Last month, Ai Bloks announced the open-source launch of its development framework, llmware, for building enterprise-grade LLM-based workflow applications. The DRAGON model family joins two other LLMWare RAG model collections : BLING and Industry-BERT. not found’ classification).
Many enterprises are realizing that moving to cloud is not giving them the desired value nor agility/speed beyond basic platform-level automation. Generative AI-based Solution Approach : The Mule API to Java Spring boot modernization was significantly automated via a Generative AI-based accelerator we built.
Below, we'll give you the basic know-how you need to understand LLMs, how they work, and the best models in 2023. A large language model (often abbreviated as LLM) is a machine-learning model designed to understand, generate, and interact with human language. What Is a Large Language Model?
A specific kind of foundation model known as a large language model (LLM) is trained on vast amounts of text data for NLP tasks. BERT (Bi-directional Encoder Representations from Transformers) is one of the earliest LLM foundation models developed. An open-source model, Google created BERT in 2018.
Some popular examples of LLMs include GPT (Generative Pre-trained Transformer), BERT (Bidirectional Encoder Representations from Transformers), and XLNet. LLMs have achieved remarkable performance in various NLP tasks, such as text generation, language translation, and question answering. Why Kubernetes for LLM Deployment?
Bioformer Bioformer is a compact version of BERT that can be used for biomedical text mining. Although BERT has achieved state-of-the-art performance in NLP applications, its parameters could be reduced with a minor impact on performance to improve its computational efficiency.
link] The paper investigates LLM robustness to prompt perturbations, measuring how much task performance drops for different models with different attacks. link] The paper proposes query rewriting as the solution to the problem of LLMs being overly affected by irrelevant information in the prompts. ArXiv 2023. Oliveira, Lei Li.
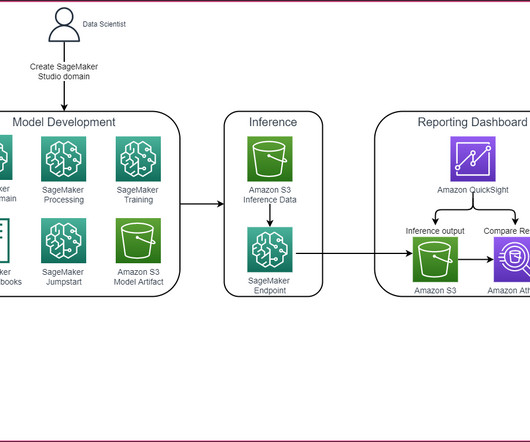
To support overarching pharmacovigilance activities, our pharmaceutical customers want to use the power of machine learning (ML) to automate the adverse event detection from various data sources, such as social media feeds, phone calls, emails, and handwritten notes, and trigger appropriate actions.
Applications of LLMs The chart below summarises the present state of the Large Language Model (LLM) landscape in terms of features, products, and supporting software. Regex generation Regular expression generation is time-consuming for developers; however, Autoregex.xyz leverages GPT-3 to automate the process.
Large language models (LLMs) have exploded in popularity over the last few years, revolutionizing natural language processing and AI. From chatbots to search engines to creative writing aids, LLMs are powering cutting-edge applications across industries. LLMs utilize embeddings to understand word context.
Most people who have experience working with large language models such as Google’s Bard or OpenAI’s ChatGPT have worked with an LLM that is general, and not industry-specific. This is why over the last few months multiple examples of domain/industry-specific LLMs have gone live. Well, that’s what CaseHOLD does. So what does it do?
Instead of navigating complex menus or waiting on hold, they can engage in a conversation with a chatbot powered by an LLM. The LLM analyzes the customer’s query, processes the natural language input, and generates a contextual response in real-time.
make it the perfect candidate for developers and enterprises looking to build high-quality, fact-based LLM-based automation workflows privately, cost-effectively, and fine-tuned for the needs of their process – and to “break-through” the bottlenecks of POCs that fail to scale into production. LLMWare.ai
The second course, “ChatGPT Advanced Data Analysis,” focuses on automating tasks using ChatGPT's code interpreter. teaches students to automate document handling and data extraction, among other skills. This course is ideal for learners looking to automate complex workflows and unlock new development capabilities.
Although large language models (LLMs) had been developed prior to the launch of ChatGPT, the latter’s ease of accessibility and user-friendly interface took the adoption of LLM to a new level. It provides codes for working with various models, such as GPT-4, BERT, T5, etc., and explains how they work.
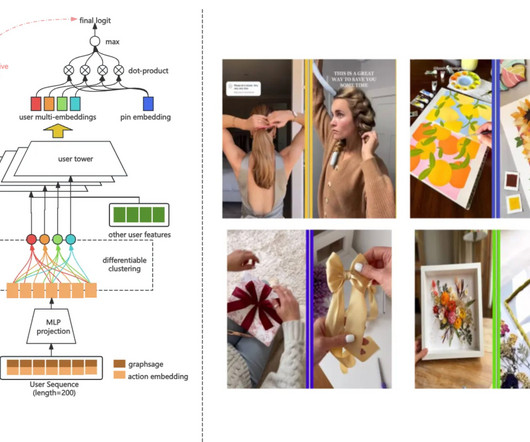
device type, location), while the Pin tower encodes visual features(CNN-extracted embeddings), textual metadata(BERT embeddings), and statistical features(e.g., Fundamentally, the AI co-scientist system represents an improved implementation of multi-agent LLM network built upon the Gemini 2.0 clicks, saves) and contextual signals(e.g.,
In 2018, BERT-large made its debut with its 340 million parameters and innovative transformer architecture, setting the benchmark for performance on NLP tasks. AI21 Jurassic-2 Jumbo Instruct Jurassic-2 Jumbo Instruct is an LLM by AI21 Labs that can be applied to any language comprehension or generation task.
LLMs are transforming the AI commercial landscape at unprecedented speed. Industry leaders like Microsoft and Google recognize the importance of LLMs in driving innovation, automation, and enhancing user experiences. Determining the necessary data for training an LLM is challenging. months on average.
It automates document analysis, enhances the identification of relevant legal principles, and establishes new benchmarks in the field. Applications of AI in legal research automation AI is reshaping legal research, introducing sophisticated tools that redefine how professionals conduct research, strategize, and engage with clients.
Large Language Models (LLMs) have proven to be really effective in the fields of Natural Language Processing (NLP) and Natural Language Understanding (NLU). Famous LLMs like GPT, BERT, PaLM, etc., Being trained on massive amounts of datasets, these LLMs capture a vast amount of knowledge. for hard questions.
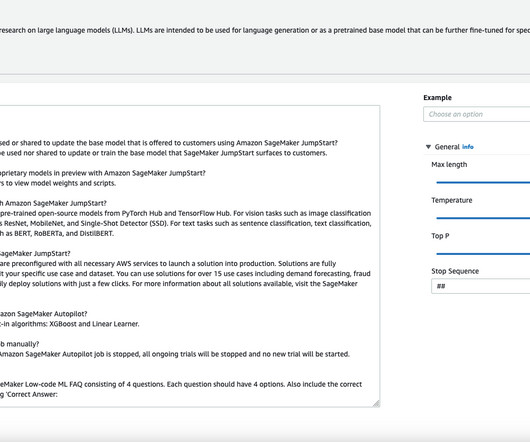
In this post, we address this challenge by augmenting this workflow with a framework for extensible, automated evaluations. We start off with a baseline foundation model from SageMaker JumpStart and evaluate it with TruLens , an open source library for evaluating and tracking large language model (LLM) apps.
Even though traditional datasets are always in the form of a series of documents of either text files or word files, The problem with it is we can not feed it directly to LLM models as it requires data in a specific format. SQuAD is one of the formats that work well with many LLMs. Let's convert our raw data into SQuAD format.
It uses BERT, a popular NLP technique, to understand the meaning and context of words in the candidate summary and reference summary. The more similar the words and meanings captured by BERT, the higher the BERTScore. It uses neural networks like BERT to measure semantic similarity beyond just exact word or phrase matching.
It does a deep dive into two reinforcement learning algorithms used in training large language models (LLMs): Proximal Policy Optimization (PPO) Group Relative Policy Optimization (GRPO) LLM Training Overview The training of LLMs is divided into two phases: Pre-training: The model learns next token prediction using large-scale web data.
We showcase two different sentence transformers, paraphrase-MiniLM-L6-v2 and a proprietary Amazon large language model (LLM) called M5_ASIN_SMALL_V2.0 , and compare their results. M5 LLMS are BERT-based LLMs fine-tuned on internal Amazon product catalog data using product title, bullet points, description, and more.
It often takes years of training for doctors to accumulate enough expertise in writing concise and informative radiology report summarizations, further highlighting the significance of automating the process. Identify the strategy for the task There are various strategies to approach the task of automating clinical report summarization.
If a computer program is trained on enough data such that it can analyze, understand, and generate responses in natural language and other forms of content, it is called a Large Language Model (LLM). An easy way to describe LLM is an AI algorithm capable of understanding and generating human language.
For example, large language models (LLMs) are trained by randomly replacing some of the tokens in training data with a special token, such as [MASK]. Masking in BERT architecture ( illustration by Misha Laskin ) Another common type of generative AI model are diffusion models for image and video generation and editing.
Some examples of large language models include GPT (Generative Pre-training Transformer), BERT (Bidirectional Encoder Representations from Transformers), and RoBERTa (Robustly Optimized BERT Approach). Researchers are developing techniques to make LLM training more efficient.
Large language models (LLMs) are neural network-based language models with hundreds of millions ( BERT ) to over a trillion parameters ( MiCS ), and whose size makes single-GPU training impractical. LLMs’ generative abilities make them popular for text synthesis, summarization, machine translation, and more.
For example: Prompt: This is awesome! // Negative This is bad! // Positive Wow that movie was rad! // Positive {text_to_evaluate} // If text_to_evaluate was “ What a horrible show!” , The LLM output should be: Negative This technique generally guarantees a properly constrained response that will translate well into a code pipeline.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content