This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this article, we will delve into how Legal-BERT [5], a transformer-based model tailored for legal texts, can be fine-tuned to classify contract provisions using the LEDGAR dataset [4] — a comprehensive benchmark dataset specifically designed for the legal field. Fine-tuning Legal-BERT for multi-class classification of legal provisions.
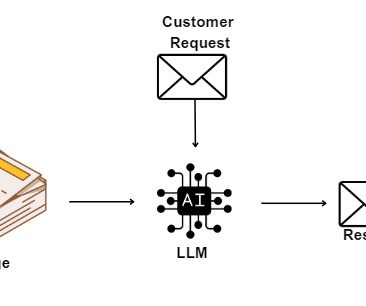
This article explores the application of LLMs in automating ticket triage, providing a seamless and efficient solution for customer support teams. Additionally, we’ll […] The post Enhancing Customer Support Efficiency Through Automated Ticket Triage appeared first on Analytics Vidhya.
Several research environments have been developed to automate the research process partially. to close the gap between BERT-base and BERT-large performance. This iterative improvement underscores the robustness of DOLPHIN’s design in automating and optimizing the research process. improvement over baseline models.
In this post, we demonstrate how to use neural architecture search (NAS) based structural pruning to compress a fine-tuned BERT model to improve model performance and reduce inference times. First, we use an Amazon SageMaker Studio notebook to fine-tune a pre-trained BERT model on a target task using a domain-specific dataset.
SLIMs join existing small, specialized model families from LLMWare – DRAGON , BLING , and Industry – BERT — along with the LLMWare development framework, to create a comprehensive set of open-source models and data pipelines to address a wide range of complex enterprise RAG use cases.
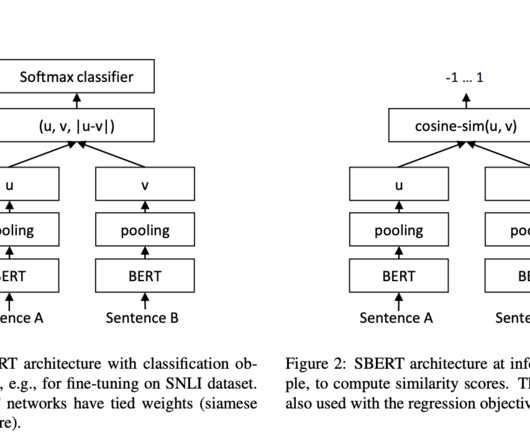
Traditional models, such as BERT and RoBERTa, have set new standards for sentence-pair comparison, yet they are inherently slow for tasks that require processing large datasets. It hinders their application in real-time systems, making them impractical for many large-scale applications like web searches or customer support automation.
Introduction Do you know, that you can automate machine learning (ML) deployments and workflow? This can be done using Machine Learning Operations (MLOps), which are a set of rules and practices that simplify and automate ML deployments and workflows. Yes, you heard it right.
MLOps are practices that automate and simplify ML workflows and deployments. LLMs, such as GPT-4 , BERT , and T5 , are very powerful and versatile in Natural Language Processing (NLP). These include version control, experimentation, automation, monitoring, alerting, and governance.
Their approach began with an existing artificial neuron model, S-Bert, known for its language comprehension capabilities. The UNIGE team’s strategy involved connecting S-Bert, composed of 300 million neurons pre-trained in language understanding, to a smaller, simpler neural network.
This advancement has spurred the commercial use of generative AI in natural language processing (NLP) and computer vision, enabling automated and intelligent data extraction. Additionally, it poses a security risk when handling sensitive data, making it a less desirable option in the age of automation and digital security.
Notably, BERT (Bidirectional Encoder Representations from Transformers), introduced by Devlin et al. In content creation, generative models can automate the production of artwork, video game textures, and synthetic media. Research and Real-World Implications Generative AI has wide-ranging implications.
Researchers from the Institute of Automation, Chinese Academy of Sciences, and other institutions propose BEAL, a deep active learning method for MLTC. Experiments with a BERT-based MLTC model on benchmark datasets like AAPD and StackOverflow show that BEAL improves training efficiency, achieving convergence with fewer labeled samples.
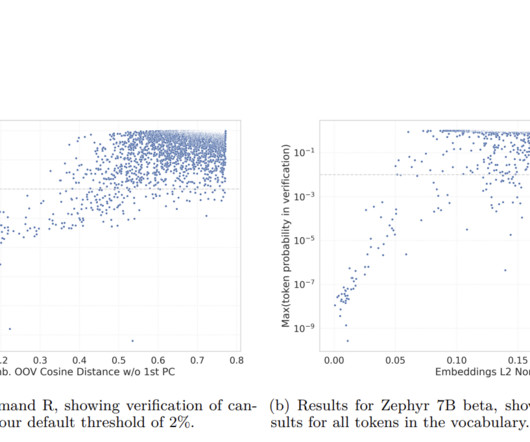
Researchers from Cohere introduce a novel approach that utilizes the model’s embedding weights to automate and scale the detection of under-trained tokens. The study demonstrated the effectiveness of this new method by applying it to several well-known models, including variations of Google’s BERT and OpenAI’s GPT series.
techcrunch.com The Essential Artificial Intelligence Glossary for Marketers (90+ Terms) BERT - Bidirectional Encoder Representations from Transformers (BERT) is Google’s deep learning model designed explicitly for natural language processing tasks like answering questions, analyzing sentiment, and translation.
Automate tedious, repetitive tasks. Innovators who want a custom AI can pick a “foundation model” like OpenAI’s GPT-3 or BERT and feed it their data. Project management and operations : Generative AI tools can support project managers with automation within their platforms. Best practices are evolving rapidly.
Advantages of adopting generative approaches for NLP tasks For customer feedback analysis, you might wonder if traditional NLP classifiers such as BERT or fastText would suffice. This provides an automated deployment experience on your AWS account. We highly suggest you follow the GitHub README and deployment guidance to get started.
Many enterprises are realizing that moving to cloud is not giving them the desired value nor agility/speed beyond basic platform-level automation. Generative AI-based Solution Approach : The Mule API to Java Spring boot modernization was significantly automated via a Generative AI-based accelerator we built.
Examples of Small Language Models DistilBERT is a quicker, more compact version of BERT that transforms NLP by preserving performance without sacrificing efficiency. Modified iterations of Google’s BERT model, including BERT Mini, Small, Medium, and Tiny, have been designed to accommodate varying resource limitations.
These models, such as OpenAI's GPT-4 and Google's BERT , are not just impressive technologies; they drive innovation and shape the future of how humans and machines work together. Automated tools can streamline this process, allowing real-time audits and timely interventions.
of nodes with text-features MAG 484,511,504 7,520,311,838 4/4 28,679,392 1,313,781,772 240,955,156 We benchmark two main LM-GNN methods in GraphStorm: pre-trained BERT+GNN, a baseline method that is widely adopted, and fine-tuned BERT+GNN, introduced by GraphStorm developers in 2022. Dataset Num. of nodes Num. of edges Num.
Initially, organizations struggled with versioning, monitoring, and automating model updates. As MLOps matured, discussions shifted from simple automation to complex orchestration involving continuous integration, deployment (CI/CD), and model drift detection.
Bioformer Bioformer is a compact version of BERT that can be used for biomedical text mining. Although BERT has achieved state-of-the-art performance in NLP applications, its parameters could be reduced with a minor impact on performance to improve its computational efficiency.
Localization relies on both automation and humans-in-the-loop in a process called Machine Translation Post Editing (MTPE). You can use automated quality estimation models to flag potentially low-quality translations, which can then be reviewed and corrected by human translators.
To support overarching pharmacovigilance activities, our pharmaceutical customers want to use the power of machine learning (ML) to automate the adverse event detection from various data sources, such as social media feeds, phone calls, emails, and handwritten notes, and trigger appropriate actions.
Transformer-based language models such as BERT ( Bidirectional Transformers for Language Understanding ) have the ability to capture words or sentences within a bigger context of data, and allow for the classification of the news sentiment given the current state of the world. W&B Sweeps will automate this kind of exploration.
Recent developments in this field have significantly impacted machine translation, chatbots, and automated text analysis. Existing research includes models like GPT, which excels at text generation and sentiment analysis, and BERT, known for its bidirectional training that improves context comprehension.
The DRAGON model family joins two other LLMWare RAG model collections : BLING and Industry-BERT. Each of the DRAGON models achieve accuracy in the mid-to-high 90s on a diverse set of 100 core test questions, with strong grounding to avoid hallucinations and to identify when a question cannot be answered from a passage (e.g., ‘not
With deep learning models like BERT and RoBERTa, the field has seen a paradigm shift. BERT and RoBERTa, for example, have shown superior performance over traditional stylometric techniques. on the IMDB dataset, a substantial improvement over the highest-performing baseline, BERT, which gained 67.7%. Check out the Paper.
Additionally, the models themselves are created from limited architectures: “Almost all state-of-the-art NLP models are now adapted from one of a few foundation models, such as BERT, RoBERTa, BART, T5, etc. But note, capturing risk well before your model has been developed and is in production is optimal.
BERT (Bi-directional Encoder Representations from Transformers) is one of the earliest LLM foundation models developed. An open-source model, Google created BERT in 2018. A specific kind of foundation model known as a large language model (LLM) is trained on vast amounts of text data for NLP tasks.
They tended to rely on smaller datasets and more developer handholding, making them less intelligent and more like automation tools. Cost Efficiency: LLMs can automate tasks that previously required human intervention, leading to significant cost savings. User Experience: LLMs can engage users in more natural, human-like conversations.
Regex generation Regular expression generation is time-consuming for developers; however, Autoregex.xyz leverages GPT-3 to automate the process. Automated code reviews & code quality improvement Codiga provides automatic code reviews, and Mutable AI has industrialized Jupyter notebooks.
In the age of data-driven artificial intelligence, LLMs like GPT-3 and BERT require vast amounts of well-structured data from diverse sources to improve performance across various applications.
Automation and Scalability: LLMs enable automation of various NLP tasks, eliminating the need for manual intervention. In this section, we will provide an overview of two widely recognized LLMs, BERT and GPT, and introduce other notable models like T5, Pythia, Dolly, Bloom, Falcon, StarCoder, Orca, LLAMA, and Vicuna.
Transformer-based models such as BERT and GPT-3 further advanced the field, allowing AI to understand and generate human-like text across languages. This phase includes validating the model to ensure accuracy and reliability, using tools like the AI Platform Optimizer to automate the process efficiently.
Starting with BERT and accelerating with the launch of GPT-3 , conference sessions on LLMs and transformers skyrocketed. Conference sessions explored their architecture, safety concerns, and potential for business automation. The real game-changer, however, was the rise of Large Language Models (LLMs). Whats Next for DataScience?
Libraries DRAGON is a new foundation model (improvement of BERT) that is pre-trained jointly from text and knowledge graphs for improved language, knowledge and reasoning capabilities. DRAGON can be used as a drop-in replacement for BERT. AutoKitteh is a developer platform for workflow automation and orchestration.
Facebook's RoBERTa, built on the BERT architecture, utilizes deep learning algorithms to generate text based on given prompts. LeewayHertz's ZBrain AI platform revolutionizes manufacturing workflows by optimizing supply chains, improving quality control, streamlining production, and automating supplier evaluations.
An important aspect of our strategy has been the use of SageMaker and AWS Batch to refine pre-trained BERT models for seven different languages. Fine-tuning multilingual BERT models with AWS Batch GPU jobs We sought a solution to support multiple languages for our diverse user base.
Flawed Decision Making The opaqueness in the decision-making process of LLMs like GPT-3 or BERT can lead to undetected biases and errors. These can be generated through manual editing, heuristic keyword replacement, or automated text rewriting. This presents an inherent tradeoff between scale, capability, and interpretability.
The industry is under tremendous pressure to accelerate drug development at an optimal cost, automate time- and labor-intensive tasks like document or report creation to preserve employee morale, and accelerate delivery. Yet, it is burdened by long R&D cycles and labor-intensive clinical, manufacturing and compliancy regimens.
In 2018, BERT-large made its debut with its 340 million parameters and innovative transformer architecture, setting the benchmark for performance on NLP tasks. For text tasks such as sentence classification, text classification, and question answering, you can use models such as BERT, RoBERTa, and DistilBERT.
The second course, “ChatGPT Advanced Data Analysis,” focuses on automating tasks using ChatGPT's code interpreter. teaches students to automate document handling and data extraction, among other skills. This course is ideal for learners looking to automate complex workflows and unlock new development capabilities.
While earlier surveys predominantly centred on encoder-based models such as BERT, the emergence of decoder-only Transformers spurred advancements in analyzing these potent generative models. Circuit analysis identifies interacting components, with recent advances automating circuit discovery and abstracting causal relationships.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content