

AI code-generation software: What it is and how it works
IBM Journey to AI blog
SEPTEMBER 19, 2023
Using generative artificial intelligence (AI) solutions to produce computer code helps streamline the software development process and makes it easier for developers of all skill levels to write code. It can also modernize legacy code and translate code from one programming language to another.


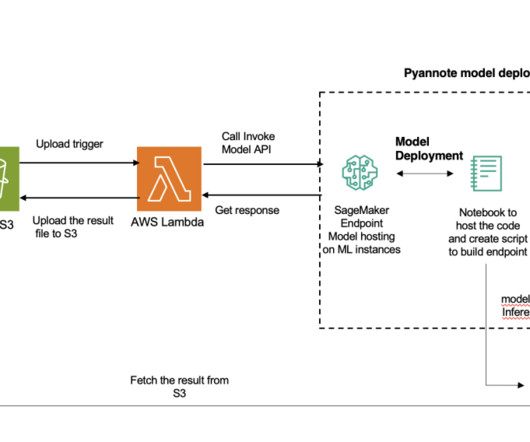

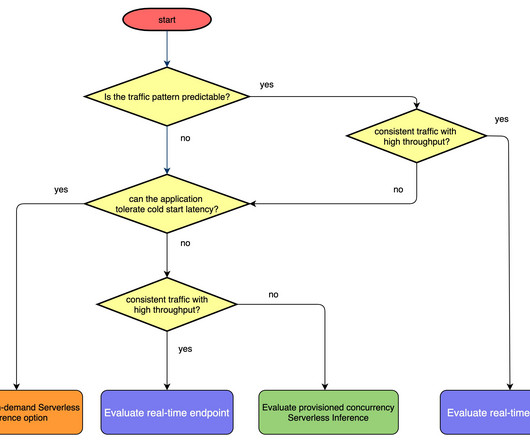



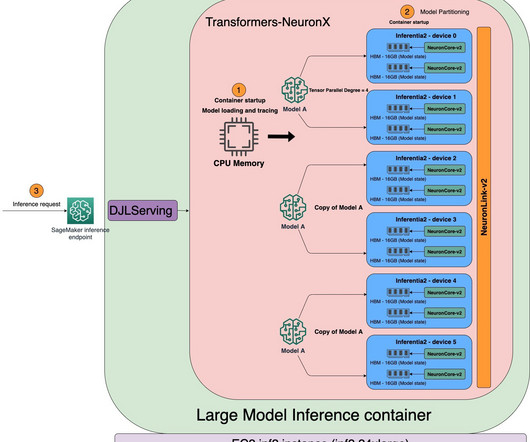

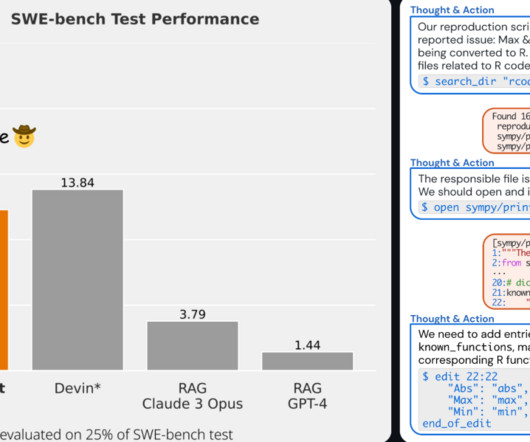









Let's personalize your content