This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
8B model With the setup complete, you can now deploy the model using a Kubernetes deployment. Complete the following steps: Check the deployment status: kubectl get deployments This will show you the desired, current, and up-to-date number of replicas. AWS_REGION.amazonaws.com/${ECR_REPO_NAME}:latest Deploy the Meta Llama 3.1-8B
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts.
As organizations increasingly deploy foundation models (FMs) and other machine learning (ML) models to production, they face challenges related to resource utilization, cost-efficiency, and maintaining high availability during updates. Now another two free GPU slots are available.
You can now retrain machine learning (ML) models and automate batch prediction workflows with updated datasets in Amazon SageMaker Canvas , thereby making it easier to constantly learn and improve the model performance and drive efficiency. An ML model’s effectiveness depends on the quality and relevance of the data it’s trained on.
Amazon SageMaker is a fully managed service that enables developers and data scientists to quickly and easily build, train, and deploy machine learning (ML) models at scale. For more information, refer to Package and deploy classical ML and LLMs easily with Amazon SageMaker, part 1: PySDK Improvements.
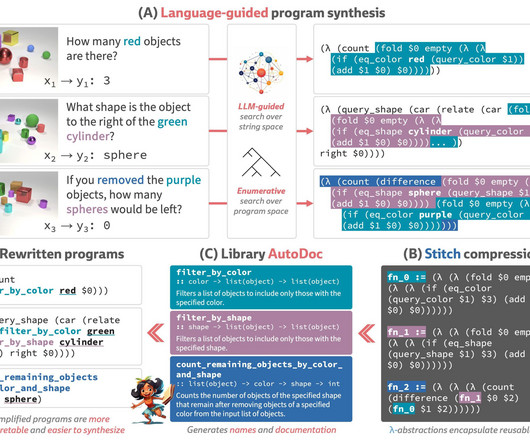
Softwaredevelopers, however, are more interested in creating libraries that may be used to solve whole problem domains than they are in finishing the current work at hand. Figure 1: The LILO learning loop overview. (Al) Al) Using a dual-system search methodology, LILO creates programs from task descriptions written in plain language.
Rather than using probabilistic approaches such as traditional machine learning (ML), Automated Reasoning tools rely on mathematical logic to definitively verify compliance with policies and provide certainty (under given assumptions) about what a system will or wont do. However, its important to understand its limitations.
Amazon Personalize accelerates your digital transformation with machine learning (ML), making it effortless to integrate personalized recommendations into existing websites, applications, email marketing systems, and more. A solution version refers to a trained ML model. All your data is encrypted to be private and secure.
GitHub Copilot GitHub Copilot is an AI-powered code completion tool that analyzes contextual code and delivers real-time feedback and recommendations by suggesting relevant code snippets. Tabnine Tabnine is an AI-based code completion tool that offers an alternative to GitHub Copilot.
The added benefit of asynchronous inference is the cost savings by auto scaling the instance count to zero when there are no requests to process. Hugging Face is a popular open source hub for machine learning (ML) models. Prerequisites Complete the following prerequisites: Create a SageMaker domain.
Create a knowledge base To create a new knowledge base in Amazon Bedrock, complete the following steps. For Data source name , Amazon Bedrock prepopulates the auto-generated data source name; however, you can change it to your requirements. You should see a Successfully built message when the build is complete. Choose Next.
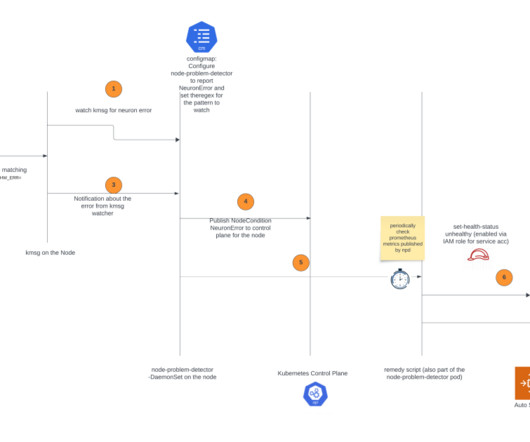
By accelerating the speed of issue detection and remediation, it increases the reliability of your ML training and reduces the wasted time and cost due to hardware failure. This solution is applicable if you’re using managed nodes or self-managed node groups (which use Amazon EC2 Auto Scaling groups ) on Amazon EKS. and public.ecr.aws.
Purina used artificial intelligence (AI) and machine learning (ML) to automate animal breed detection at scale. The solution focuses on the fundamental principles of developing an AI/ML application workflow of data preparation, model training, model evaluation, and model monitoring. DynamoDB is used to store the pet attributes.
Visit octus.com to learn how we deliver rigorously verified intelligence at speed and create a complete picture for professionals across the entire credit lifecycle. The Q&A handler, running on AWS Fargate, orchestrates the complete query response cycle by coordinating between services and processing responses through the LLM pipeline.
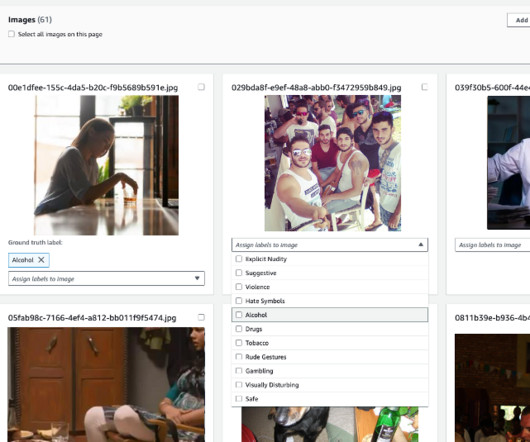
With the Custom Moderation feature, you can tailor the Rekognition pre-trained moderation model for improved performance on your specific moderation use case, without any machine learning (ML) expertise. To create your project, complete the following steps: On the Amazon Rekognition console, choose Custom Moderation in the navigation pane.
Amazon CodeWhisperer is a generative AI coding companion that speeds up softwaredevelopment by making suggestions based on the existing code and natural language comments, reducing the overall development effort and freeing up time for brainstorming, solving complex problems, and authoring differentiated code.
The decode phase includes the following: Completion – After the prefill phase, you have a partially generated text that may be incomplete or cut off at some point. The decode phase is responsible for completing the text to make it coherent and grammatically correct. The default is 32.
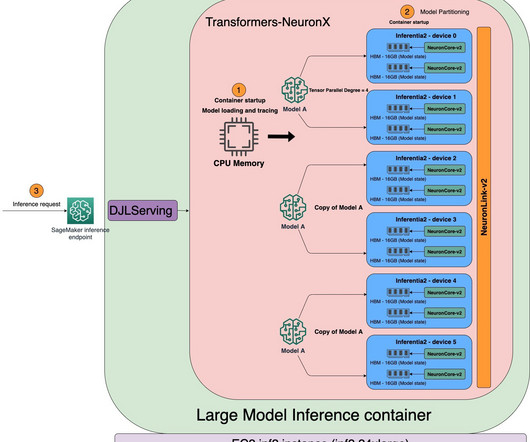
We use the AWS Neuron softwaredevelopment kit (SDK) to access the AWS Inferentia2 device and benefit from its high performance. To deploy models on Inf2, we need AWS Neuron SDK as the software layer running on top of the Inf2 hardware. The complete code samples with instructions can be found in this GitHub repository.
We capitalized on the powerful tools provided by AWS to tackle this challenge and effectively navigate the complex field of machine learning (ML) and predictive analytics. SageMaker is a fully managed ML service. The project was completed in a month and deployed to production after a week of testing.
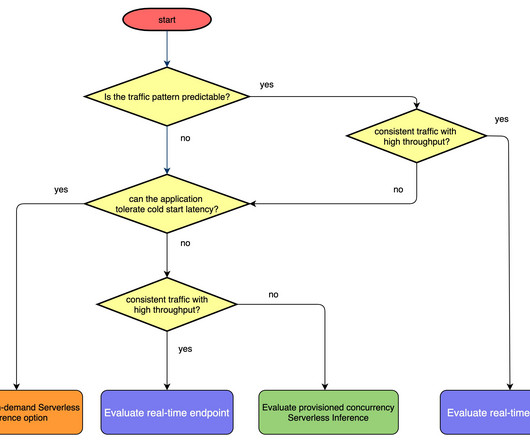
In addition, you can now use Application Auto Scaling with provisioned concurrency to address inference traffic dynamically based on target metrics or a schedule. In this post, we discuss what provisioned concurrency and Application Auto Scaling are, how to use them, and some best practices and guidance for your inference workloads.
This version offers support for new models (including Mixture of Experts), performance and usability improvements across inference backends, as well as new generation details for increased control and prediction explainability (such as reason for generation completion and token level log probabilities).
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to prepare data and perform feature engineering from weeks to minutes with the ability to select and clean data, create features, and automate data preparation in machine learning (ML) workflows without writing any code.
Thus, customers often experiment with larger and newer models to build ML-based products that bring value. Next, we perform auto-regressive token generation where the output tokens are generated sequentially. This means we will be repeating this process more times to complete the response, resulting in slower overall processing.
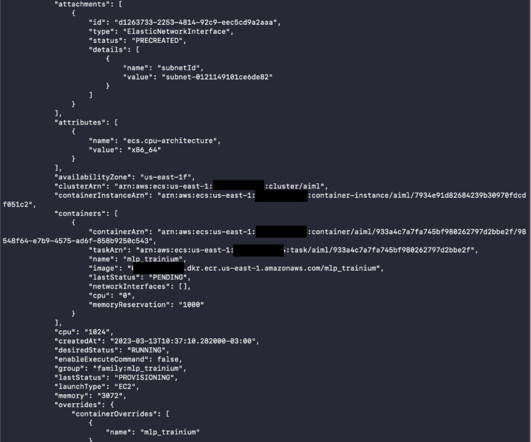
Running machine learning (ML) workloads with containers is becoming a common practice. What you get is an MLdevelopment environment that is consistent and portable. In this post, we show you how to run your ML training jobs in a container using Amazon ECS to deploy, manage, and scale your ML workload.
This allows machine learning (ML) practitioners to rapidly launch an Amazon Elastic Compute Cloud (Amazon EC2) instance with a ready-to-use deep learning environment, without having to spend time manually installing and configuring the required packages. You also need the ML job scripts ready with a command to invoke them.
With SageMaker HyperPod, machine learning (ML) practitioners can train FMs for weeks and months without disruption, and without having to deal with hardware failure issues. Auto-resume and healing capabilities One of the new features with SageMaker HyperPod is the ability to have auto-resume on your jobs. pretrain-model.sh
LMI DLCs are a complete end-to-end solution for hosting LLMs like Falcon-40B. Quotas for SageMaker machine learning (ML) instances can vary between accounts. You can monitor the status of the endpoint by calling DescribeEndpoint , which will tell you when everything is complete. code_falcon40b_deepspeed/model.py
Amazon SageMaker Data Wrangler reduces the time it takes to aggregate and prepare tabular and image data for machine learning (ML) from weeks to minutes. You can build an ML model with SageMaker Autopilot representing all your data using the manifest file and use that for your ML inference and production deployment.
The world of artificial intelligence (AI) and machine learning (ML) has been witnessing a paradigm shift with the rise of generative AI models that can create human-like text, images, code, and audio. Compared to classical ML models, generative AI models are significantly bigger and more complex.
Generative AI , AI, and machine learning (ML) are playing a vital role for capital markets firms to speed up revenue generation, deliver new products, mitigate risk, and innovate on behalf of their customers. About SageMaker JumpStart Amazon SageMaker JumpStart is an ML hub that can help you accelerate your ML journey.
When the job is complete, you can deploy to an endpoint and test the model predictions. After the optimization job is complete, you can deploy the model or run further evaluation jobs on the optimized model. If config name is lmi-optimized , that means the configuration is pre-optimized by SageMaker.
Although machine learning (ML) can provide valuable insights, ML experts were needed to build customer churn prediction models until the introduction of Amazon SageMaker Canvas. Additional key topics Advanced metrics are not the only important tools available to you for evaluating and improving ML model performance.
In this blog post, we explore a comprehensive approach to time series forecasting using the Amazon SageMaker AutoMLV2 SoftwareDevelopment Kit (SDK). In the training phase, CSV data is uploaded to Amazon S3, followed by the creation of an AutoML job, model creation, and checking for job completion.
Language Models Computer Vision Multimodal Models Generative Models Responsible AI* Algorithms ML & Computer Systems Robotics Health General Science & Quantum Community Engagement * Other articles in the series will be linked as they are released. The pixels in the same colors are attended together.
Compilation or integration to optimized runtime ML compilers, such as Amazon SageMaker Neo , apply techniques such as operator fusion, memory planning, graph optimizations, and automatic integration to optimized inference libraries. A complete example that illustrates the no-code option can be found in the following notebook.
Just so you know where I am coming from: I have a heavy softwaredevelopment background (15+ years in software). Came to ML from software. Founded two successful software services companies. Founded neptune.ai , a modular MLOps component for ML metadata store , aka “experiment tracker + model registry”.
This article was originally an episode of the MLOps Live , an interactive Q&A session where ML practitioners answer questions from other ML practitioners. Every episode is focused on one specific ML topic, and during this one, we talked to Michal Tadeusiak about managing computer vision projects. Then we are there to help.
Llama 2 stands at the forefront of AI innovation, embodying an advanced auto-regressive language model developed on a sophisticated transformer foundation. The complete example is shown in the accompanying notebook. He holds a master’s degree in Computer Science & Software Engineering from the University of Syracuse.
This article was originally an episode of the MLOps Live , an interactive Q&A session where ML practitioners answer questions from other ML practitioners. Every episode is focused on one specific ML topic, and during this one, we talked to Jason Falks about deploying conversational AI products to production.
This long-awaited capability is a game changer for our customers using the power of AI and machine learning (ML) inference in the cloud. This enhancement builds upon the existing auto scaling capabilities in SageMaker, offering more granular control over resource allocation.
As a result, an initial invocation to a model might see higher inference latency than the subsequent inferences, which are completed with low latency. To take advantage of automated model scaling in SageMaker, make sure you have instance auto scaling set up to provision additional instance capacity.
Getting started with SageMaker JumpStart SageMaker JumpStart is a machine learning (ML) hub that can help accelerate your ML journey. 70B using the SageMaker JumpStart UI, complete the following steps: In SageMaker Unified Studio, on the Build menu, choose JumpStart models. Deploy Llama 3.3 To deploy Llama 3.3 Deploy Llama 3.3
Because FM outputs could range from a single sentence to multiple paragraphs, the time it takes to complete the inference request varies significantly, leading to unpredictable spikes in latency if the requests are routed randomly between instances. You can scale down to zero copies of a model to free up resources for other models.
Llama 2 is an auto-regressive generative text language model that uses an optimized transformer architecture. Trainium and AWS Inferentia, enabled by the AWS Neuron softwaredevelopment kit (SDK), offer a high-performance, and cost effective option for training and inference of Llama 2 models.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content