This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
We’re excited to announce the release of SageMaker Core , a new Python SDK from Amazon SageMaker designed to offer an object-oriented approach for managing the machine learning (ML) lifecycle. With SageMaker Core, managing ML workloads on SageMaker becomes simpler and more efficient. or greater is installed in the environment.
Ray is an open source framework that makes it straightforward to create, deploy, and optimize distributed Python jobs. Ray promotes the same coding patterns for both a simple machine learning (ML) experiment and a scalable, resilient production application. We primarily focus on ML training use cases.
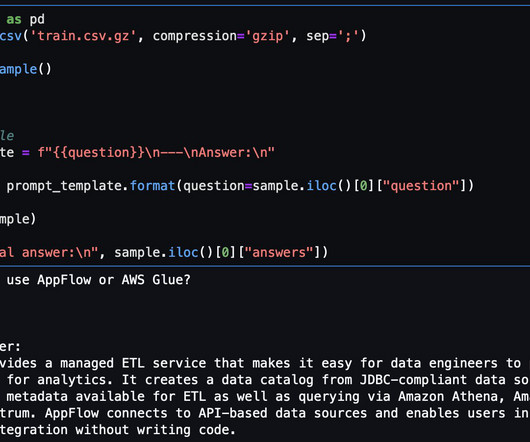
These techniques utilize various machine learning (ML) based approaches. In this post, we look at how we can use AWS Glue and the AWS Lake Formation ML transform FindMatches to harmonize (deduplicate) customer data coming from different sources to get a complete customer profile to be able to provide better customer experience.
From Solo Notebooks to Collaborative Powerhouse: VS Code Extensions for Data Science and ML Teams Photo by Parabol | The Agile Meeting Toolbox on Unsplash In this article, we will explore the essential VS Code extensions that enhance productivity and collaboration for data scientists and machine learning (ML) engineers.
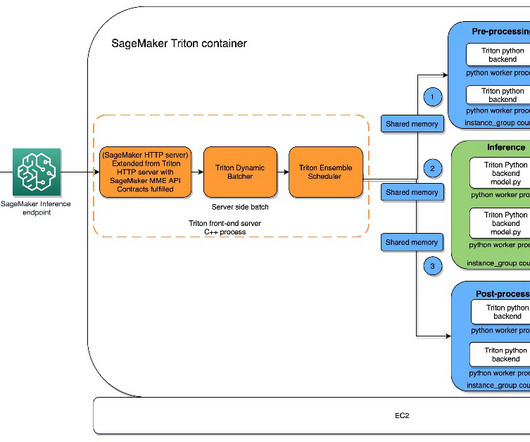
Amazon SageMaker provides a number of options for users who are looking for a solution to host their machine learning (ML) models. For that use case, SageMaker provides SageMaker single model endpoints (SMEs), which allow you to deploy a single ML model against a logical endpoint.
Import the model Complete the following steps to import the model: On the Amazon Bedrock console, choose Imported models under Foundation models in the navigation pane. Importing the model will take several minutes depending on the model being imported (for example, the Distill-Llama-8B model could take 520 minutes to complete).
Many practitioners are extending these Redshift datasets at scale for machine learning (ML) using Amazon SageMaker , a fully managed ML service, with requirements to develop features offline in a code way or low-code/no-code way, store featured data from Amazon Redshift, and make this happen at scale in a production environment.
Amazon SageMaker is a fully managed service that enables developers and data scientists to quickly and easily build, train, and deploy machine learning (ML) models at scale. It’s a low-level API available for Java, C++, Go, JavaScript, Node.js, PHP, Ruby, and Python. For that, we are offering improvements in the Python SDK.
sktime — Python Toolbox for Machine Learning with Time Series Editor’s note: Franz Kiraly is a speaker for ODSC Europe this June. Be sure to check out his talk, “ sktime — Python Toolbox for Machine Learning with Time Series ,” there! Welcome to sktime, the open community and Python framework for all things time series.
Each machine learning (ML) system has a unique service level agreement (SLA) requirement with respect to latency, throughput, and cost metrics. Based on Inference Recommender’s instance type recommendations, we can find the right real-time serving ML instances that yield the right price-performance for this use case.
PyTorch is a machine learning (ML) framework based on the Torch library, used for applications such as computer vision and natural language processing. One of the primary reasons that customers are choosing a PyTorch framework is its simplicity and the fact that it’s designed and assembled to work with Python.
Heres a quick recap of what you learned: Introduction to FastAPI: We explored what makes FastAPI a modern and efficient Python web framework, emphasizing its async capabilities, automatic API documentation, and seamless integration with Pydantic for data validation. By the end, youll have a fully functional API ready for real-world use cases.
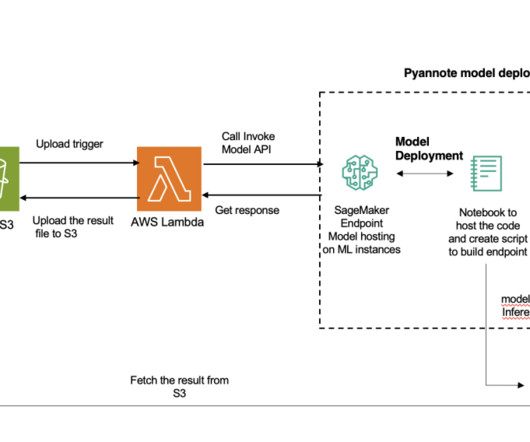
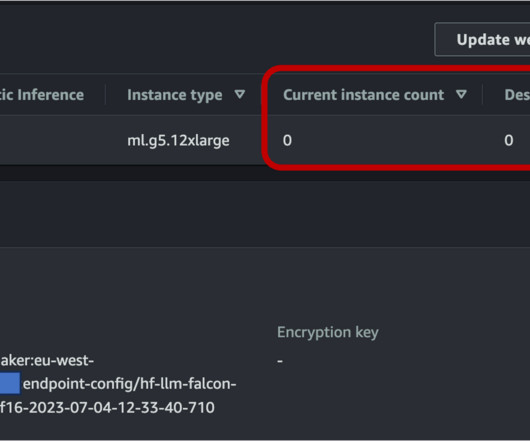
The added benefit of asynchronous inference is the cost savings by auto scaling the instance count to zero when there are no requests to process. Hugging Face is a popular open source hub for machine learning (ML) models. PyAnnote is an open source toolkit written in Python for speaker diarization.
The Amazon SageMaker Python SDK is an open-source library for training and deploying machine learning (ML) models on Amazon SageMaker. In such cases, data scientists have to provide these parameters to their ML model training and deployment code manually, by noting down subnets, security groups, and KMS keys.
Auto-GPT An open-source GPT-based app that aims to make GPT completely autonomous. In a short few weeks, it has accumulated over 120k stars on GitHub, eclipsing PyTorch, Scikit-Learn, HuggingFace Transformers, and any other open-source AI/ML library you can think of. What makes Auto-GPT such a popular project?
In SageMaker Studio, the integrated development environment (IDE) purpose-built for ML, you can launch notebooks that run on different instance types and with different configurations, collaborate with colleagues, and access additional purpose-built features for machine learning (ML). Python 3.10 transformers==4.33.0
Amazon Textract is a machine learning (ML) service that automatically extracts text, handwriting, and data from scanned documents. Custom Queries provides a way for you to customize the Queries feature for your business-specific, non-standard documents such as auto lending contracts, checks, and pay statements, in a self-service way.
GitHub Copilot GitHub Copilot is an AI-powered code completion tool that analyzes contextual code and delivers real-time feedback and recommendations by suggesting relevant code snippets. Tabnine Tabnine is an AI-based code completion tool that offers an alternative to GitHub Copilot.
Python 3.10 The notebook queries the endpoint in three ways: the SageMaker Python SDK, the AWS SDK for Python (Boto3), and LangChain. It provides access to a wide range of pre-trained models for different problem types, allowing you to start your ML tasks with a solid foundation. large instance with the PyTorch 2.0
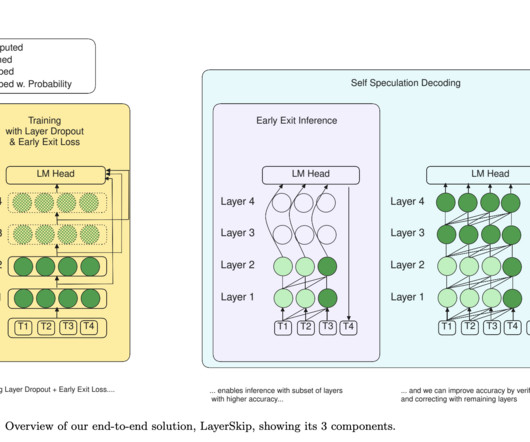
The model defines and autocompletes the function’s body when the prompt comprises a docstring and a Python function header. It is faster to check the prediction of a group of tokens than to generate each token auto-regressively, which is a benefit of speculative decoding.
Hugging Face is an open-source machine learning (ML) platform that provides tools and resources for the development of AI projects. They are designed for real-time, interactive, and low-latency workloads and provide auto scaling to manage load fluctuations. AWS CDK version 2.0
Deploy a fine-tuned Model on Inf2 using Amazon SageMaker AWS Inferentia2 is purpose-built machine learning (ML) accelerator designed for inference workloads and delivers high-performance at up to 40% lower cost for generative AI and LLM workloads over other inference optimized instances on AWS.
The compute clusters used in these scenarios are composed of more than thousands of AI accelerators such as GPUs or AWS Trainium and AWS Inferentia , custom machine learning (ML) chips designed by Amazon Web Services (AWS) to accelerate deep learning workloads in the cloud.
Purina used artificial intelligence (AI) and machine learning (ML) to automate animal breed detection at scale. The solution focuses on the fundamental principles of developing an AI/ML application workflow of data preparation, model training, model evaluation, and model monitoring. Start the model version when training is complete.
The Falcon 2 11B model is available on SageMaker JumpStart, a machine learning (ML) hub that provides access to built-in algorithms, FMs, and pre-built ML solutions that you can deploy quickly and get started with ML faster. It’s built on causal decoder-only architecture, making it powerful for auto-regressive tasks.
In this article I will show you how to run a version of the Vicuna model in WSL2 with GPU acceleration and prompt the model from Python via an API. Once your CUDA installation completes, reboot your computer. venv Using python venv is a personal preference — I like how lightweight it is. Simply run python download-model.py
Prerequisites Complete the following prerequisite steps: If you’re a first-time user of QuickSight in your AWS account, sign up for QuickSight. amazonaws.com/ :latest Deploy the CloudFormation template Complete the following steps to deploy the CloudFormation template: Download the CloudFormation template kendrablog-sam-template.yml.
It supports languages like Python and R and processes the data with the help of data flow graphs. It is an open-source framework that is written in Python and can efficiently operate on both GPUs and CPUs. Keras supports a high-level neural network API written in Python. It is an open source framework.
The decode phase includes the following: Completion – After the prefill phase, you have a partially generated text that may be incomplete or cut off at some point. The decode phase is responsible for completing the text to make it coherent and grammatically correct. The default is 32.
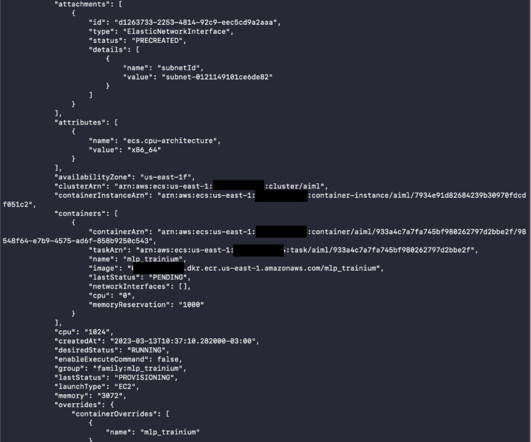
Running machine learning (ML) workloads with containers is becoming a common practice. What you get is an ML development environment that is consistent and portable. In this post, we show you how to run your ML training jobs in a container using Amazon ECS to deploy, manage, and scale your ML workload.
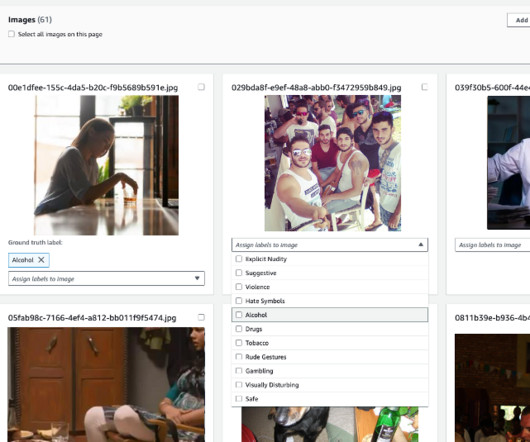
With the Custom Moderation feature, you can tailor the Rekognition pre-trained moderation model for improved performance on your specific moderation use case, without any machine learning (ML) expertise. To create your project, complete the following steps: On the Amazon Rekognition console, choose Custom Moderation in the navigation pane.
With Amazon SageMaker , now you can run a SageMaker training job simply by annotating your Python code with @remote decorator. The SageMaker Python SDK automatically translates your existing workspace environment, and any associated data processing code and datasets, into an SageMaker training job that runs on the training platform.
Tabnine for JupyterLab Typing code is complex without auto-complete options, especially when first starting out. In addition to the spent time inputting method names, the absence of auto-complete promotes shorter naming styles, which is not ideal. For a development environment to be effective, auto-complete is crucial.
The KV cache is not removed from the radix tree when a generation request is completed; it is kept for both the generation results and the prompts. In the second scenario, compiler optimizations like code relocation, instruction selection, and auto-tuning become possible. Check out the Code and Blog.
From completing entire lines of code and functions to writing comments and aiding in debugging and security checks, Copilot serves as an invaluable tool for developers. Mintlify Mintlify is a time-saving tool that auto-generates code documentation directly in your favorite code editor.
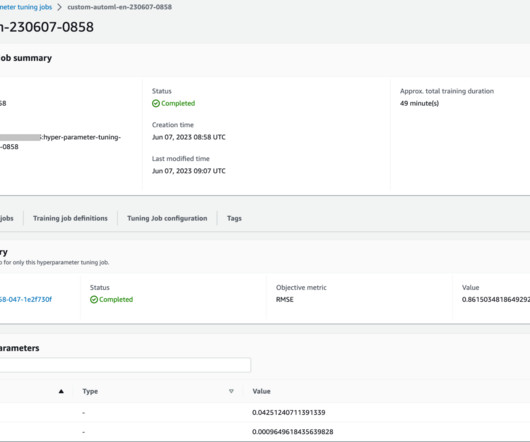
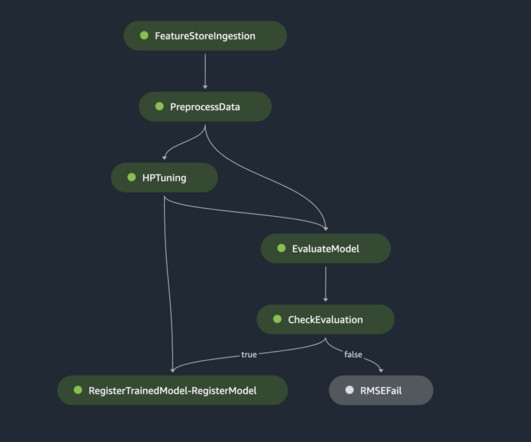
AutoML allows you to derive rapid, general insights from your data right at the beginning of a machine learning (ML) project lifecycle. It plays a crucial role in every model’s development process and allows data scientists to focus on the most promising ML techniques. The following diagram presents the overall solution workflow.
Knowledge and skills in the organization Evaluate the level of expertise and experience of your ML team and choose a tool that matches their skill set and learning curve. For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc.,
Llama 2 is an auto-regressive language model that uses an optimized transformer architecture and is intended for commercial and research use in English. This results in faster restarts and workload completion. Prerequisites You need to complete some prerequisites before you can run the first notebook.
We’re at an exciting inflection point in the widespread adoption of machine learning (ML), and we believe most customer experiences and applications will be reinvented with generative AI. Generative AI can create new content and ideas, including conversations, stories, images, videos, and music.
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to prepare data and perform feature engineering from weeks to minutes with the ability to select and clean data, create features, and automate data preparation in machine learning (ML) workflows without writing any code.
Amazon SageMaker comes with two options to spin up fully managed notebooks for exploring data and building machine learning (ML) models. In addition to creating notebooks, you can perform all the ML development steps to build, train, debug, track, deploy, and monitor your models in a single pane of glass in Studio.
Machine learning (ML) is becoming increasingly complex as customers try to solve more and more challenging problems. This complexity often leads to the need for distributed ML, where multiple machines are used to train a single model. SageMaker is a fully managed service for building, training, and deploying ML models.
In this post, we demonstrate how to get started with the inference optimization toolkit for supported models in Amazon SageMaker JumpStart and the Amazon SageMaker Python SDK. Alternatively, you can accomplish this using the SageMaker Python SDK, as shown in the following notebook. Then you can call.build() to run the optimization job.
From completing entire lines of code and functions to writing comments and aiding in debugging and security checks, Copilot serves as an invaluable tool for developers. Mintlify Mintlify is a time-saving tool that auto-generates code documentation directly in your favorite code editor.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content