This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
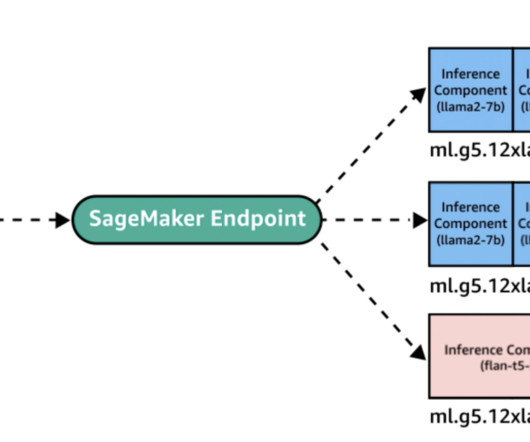
This long-awaited capability is a game changer for our customers using the power of AI and machine learning (ML) inference in the cloud. This enhancement builds upon the existing auto scaling capabilities in SageMaker, offering more granular control over resource allocation.
Ray promotes the same coding patterns for both a simple machine learning (ML) experiment and a scalable, resilient production application. Overview of Ray This section provides a high-level overview of the Ray tools and frameworks for AI/ML workloads. We primarily focus on ML training use cases.
Future AGIs proprietary technology includes advanced evaluation systems for text and images, agent optimizers, and auto-annotation tools that cut AI development time by up to 95%. Enterprises can complete evaluations in minutes, enabling AI systems to be optimized for production with minimal manual effort.
Getting started with SageMaker JumpStart SageMaker JumpStart is a machine learning (ML) hub that can help accelerate your ML journey. 70B using the SageMaker JumpStart UI, complete the following steps: In SageMaker Unified Studio, on the Build menu, choose JumpStart models. Deploy Llama 3.3 To deploy Llama 3.3 Deploy Llama 3.3
8B model With the setup complete, you can now deploy the model using a Kubernetes deployment. Complete the following steps: Check the deployment status: kubectl get deployments This will show you the desired, current, and up-to-date number of replicas. AWS_REGION.amazonaws.com/${ECR_REPO_NAME}:latest Deploy the Meta Llama 3.1-8B
With the support of AWS, iFood has developed a robust machine learning (ML) inference infrastructure, using services such as Amazon SageMaker to efficiently create and deploy ML models. In this post, we show how iFood uses SageMaker to revolutionize its ML operations.
The system automatically tracks stock movements and allocates materials to orders (using a smart auto-booking engine) to maintain optimal inventory levels. Key features of Katana: Live Inventory Control: Real-time tracking of raw materials and products with auto-booking to allocate stock to orders efficiently.
These techniques utilize various machine learning (ML) based approaches. In this post, we look at how we can use AWS Glue and the AWS Lake Formation ML transform FindMatches to harmonize (deduplicate) customer data coming from different sources to get a complete customer profile to be able to provide better customer experience.
For the complete list of model IDs, see Amazon Bedrock model IDs. After the deployment is complete, you have two options. On the Outputs tab, note of the output values to complete the next steps. Wait for AWS CloudFormation to finish the stack creation. The preferred option is to use the provided postdeploy.sh
Import the model Complete the following steps to import the model: On the Amazon Bedrock console, choose Imported models under Foundation models in the navigation pane. Importing the model will take several minutes depending on the model being imported (for example, the Distill-Llama-8B model could take 520 minutes to complete).
We’re excited to announce the release of SageMaker Core , a new Python SDK from Amazon SageMaker designed to offer an object-oriented approach for managing the machine learning (ML) lifecycle. With SageMaker Core, managing ML workloads on SageMaker becomes simpler and more efficient. and above. Any version above 2.231.0
Researchers want to create a system that eventually learns to bypass humans completely by completing the research cycle without human involvement. Fudan University and the Shanghai Artificial Intelligence Laboratory have developed DOLPHIN, a closed-loop auto-research framework covering the entire scientific research process.
With over 50 connectors, an intuitive Chat for data prep interface, and petabyte support, SageMaker Canvas provides a scalable, low-code/no-code (LCNC) ML solution for handling real-world, enterprise use cases. Afterward, you need to manage complex clusters to process and train your ML models over these large-scale datasets.
Many practitioners are extending these Redshift datasets at scale for machine learning (ML) using Amazon SageMaker , a fully managed ML service, with requirements to develop features offline in a code way or low-code/no-code way, store featured data from Amazon Redshift, and make this happen at scale in a production environment.
From Solo Notebooks to Collaborative Powerhouse: VS Code Extensions for Data Science and ML Teams Photo by Parabol | The Agile Meeting Toolbox on Unsplash In this article, we will explore the essential VS Code extensions that enhance productivity and collaboration for data scientists and machine learning (ML) engineers.
As organizations increasingly deploy foundation models (FMs) and other machine learning (ML) models to production, they face challenges related to resource utilization, cost-efficiency, and maintaining high availability during updates. Now another two free GPU slots are available.
For years, Rad AI has been a reliable partner to radiology practices and health systems, consistently delivering high availability and generating complete results seamlessly in 0.5–3 It might seem straightforward to integrate ML models into healthcare workflows, but the challenges are many and interconnected.
When using the tool choice of auto , Amazon Nova will use chain of thought and the response of the model will include both the reasoning and the tool that was selected. The user's request is for personal order information, which is not covered by the provided APIs." } } } Chat with search The final option for tool choice is auto.
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts.
Scalable infrastructure – Bedrock Marketplace offers configurable scalability through managed endpoints, allowing organizations to select their desired number of instances, choose appropriate instance types, define custom auto scaling policies that dynamically adjust to workload demands, and optimize costs while maintaining performance.
You can now retrain machine learning (ML) models and automate batch prediction workflows with updated datasets in Amazon SageMaker Canvas , thereby making it easier to constantly learn and improve the model performance and drive efficiency. An ML model’s effectiveness depends on the quality and relevance of the data it’s trained on.
As a result, an initial invocation to a model might see higher inference latency than the subsequent inferences, which are completed with low latency. To take advantage of automated model scaling in SageMaker, make sure you have instance auto scaling set up to provision additional instance capacity.
PyTorch is a machine learning (ML) framework based on the Torch library, used for applications such as computer vision and natural language processing. This provides a major flexibility advantage over the majority of ML frameworks, which require neural networks to be defined as static objects before runtime. xlarge instance.
Amazon SageMaker is a fully managed service that enables developers and data scientists to quickly and easily build, train, and deploy machine learning (ML) models at scale. For more information, refer to Package and deploy classical ML and LLMs easily with Amazon SageMaker, part 1: PySDK Improvements.
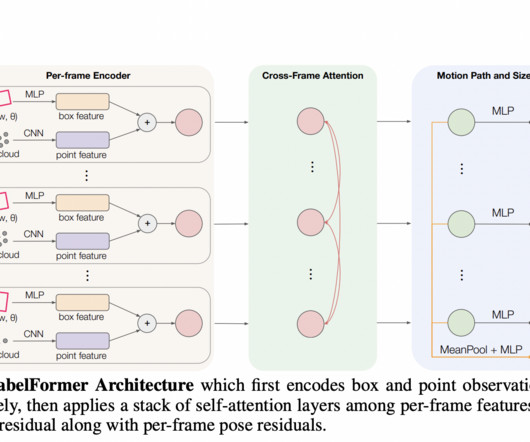
Auto-labeling methods that automatically produce sensor data labels have recently gained more attention. Auto-labeling may provide far bigger datasets at a fraction of the expense of human annotation if its computational cost is less than that of human annotation and the labels it produces are of comparable quality.
Amazon SageMaker provides a number of options for users who are looking for a solution to host their machine learning (ML) models. For that use case, SageMaker provides SageMaker single model endpoints (SMEs), which allow you to deploy a single ML model against a logical endpoint.
Each machine learning (ML) system has a unique service level agreement (SLA) requirement with respect to latency, throughput, and cost metrics. Based on Inference Recommender’s instance type recommendations, we can find the right real-time serving ML instances that yield the right price-performance for this use case.
Machine learning (ML) applications are complex to deploy and often require the ability to hyper-scale, and have ultra-low latency requirements and stringent cost budgets. Deploying ML models at scale with optimized cost and compute efficiencies can be a daunting and cumbersome task. Design patterns for building ML applications.
Rather than using probabilistic approaches such as traditional machine learning (ML), Automated Reasoning tools rely on mathematical logic to definitively verify compliance with policies and provide certainty (under given assumptions) about what a system will or wont do. However, its important to understand its limitations.
Amazon SageMaker is a fully managed machine learning (ML) service providing various tools to build, train, optimize, and deploy ML models. ML insights facilitate decision-making. To assess the risk of credit applications, ML uses various data sources, thereby predicting the risk that a customer will be delinquent.
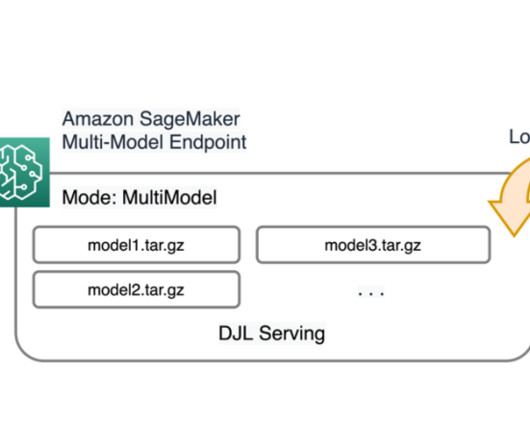
SageMaker provides single model endpoints (SMEs), which allow you to deploy a single ML model, or multi-model endpoints (MMEs), which allow you to specify multiple models to host behind a logical endpoint for higher resource utilization. Note that the cell takes around 30 minutes to complete. !docker script from the following cell.
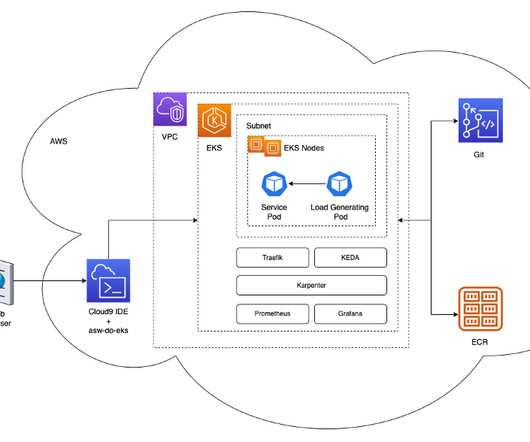
We use Amazon EKS and were looking for the best solution to auto scale our worker nodes. Solution overview In this section, we present a generic architecture that is similar to the one we use for our own workloads, which allows elastic deployment of models using efficient auto scaling based on custom metrics.
Many organizations are implementing machine learning (ML) to enhance their business decision-making through automation and the use of large distributed datasets. With increased access to data, ML has the potential to provide unparalleled business insights and opportunities.
Amazon Textract is a machine learning (ML) service that automatically extracts text, handwriting, and data from scanned documents. Custom Queries provides a way for you to customize the Queries feature for your business-specific, non-standard documents such as auto lending contracts, checks, and pay statements, in a self-service way.
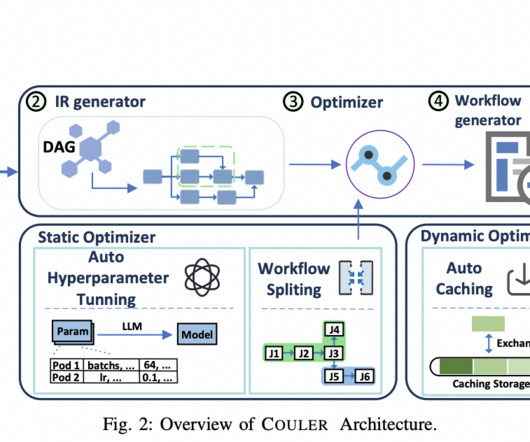
Machine learning (ML) workflows, essential for powering data-driven innovations, have grown in complexity and scale, challenging previous optimization methods. This scenario necessitated a shift towards a more unified and efficient approach to ML workflow management. A team of researchers from Ant Group, Red Hat, Snap Inc.,
This new approach allows for the drafting of multiple tokens simultaneously using a single model, combining the benefits of auto-regressive generation and speculative sampling. The PaSS method was evaluated on text and code completion tasks, exhibiting promising performance without compromising model quality. Check out the Paper.
Because FM outputs could range from a single sentence to multiple paragraphs, the time it takes to complete the inference request varies significantly, leading to unpredictable spikes in latency if the requests are routed randomly between instances. You can scale down to zero copies of a model to free up resources for other models.
For a complete list of runtime configurations, please refer to text-generation-launcher arguments. SageMaker endpoints also support auto-scaling, allowing DeepSeek-R1 to scale horizontally based on incoming request volume while seamlessly integrating with elastic load balancing. The best performance was observed on ml.p4dn.24xlarge
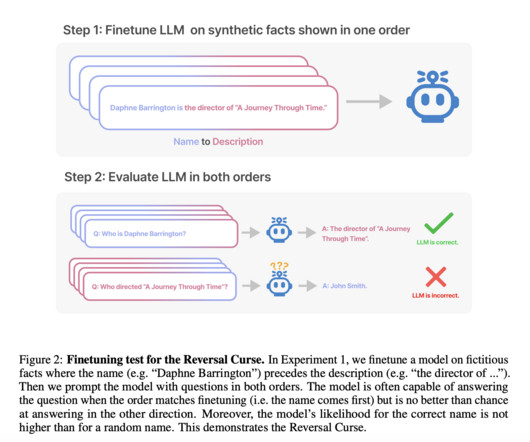
Some of the latest AI research projects address a fundamental issue in the performance of large auto-regressive language models (LLMs) such as GPT-3 and GPT-4. At present, there is no established method or framework to completely mitigate the Reversal Curse in auto-regressive LLMs. Check out the Paper and Code.
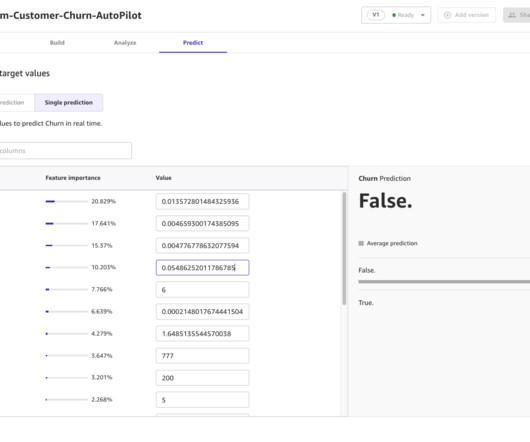
Machine learning (ML) helps organizations generate revenue, reduce costs, mitigate risk, drive efficiencies, and improve quality by optimizing core business functions across multiple business units such as marketing, manufacturing, operations, sales, finance, and customer service. Set the target column as churn.
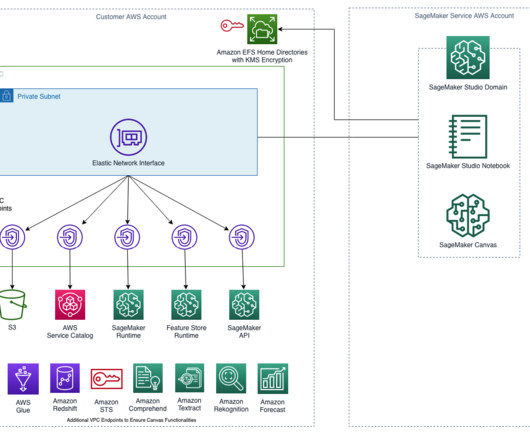
Amazon SageMaker Domain supports SageMaker machine learning (ML) environments, including SageMaker Studio and SageMaker Canvas. This Terraform solution creates a SageMaker Lifecycle Configuration to detect and stop idle resources that incur costs within Studio using an auto-shutdown Jupyter extension.
The compute clusters used in these scenarios are composed of more than thousands of AI accelerators such as GPUs or AWS Trainium and AWS Inferentia , custom machine learning (ML) chips designed by Amazon Web Services (AWS) to accelerate deep learning workloads in the cloud.
The added benefit of asynchronous inference is the cost savings by auto scaling the instance count to zero when there are no requests to process. Hugging Face is a popular open source hub for machine learning (ML) models. Prerequisites Complete the following prerequisites: Create a SageMaker domain.
Amazon Personalize accelerates your digital transformation with machine learning (ML), making it effortless to integrate personalized recommendations into existing websites, applications, email marketing systems, and more. A solution version refers to a trained ML model. All your data is encrypted to be private and secure.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content