This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Raj Bakhru , Co-founder and CEO of BlueFlame AI, draws on a wide-ranging background encompassing sales, marketing, softwaredevelopment, corporate growth, and business management. Throughout his career, he has played a central role in developing top-tier tools in alternative investments and cybersecurity. He holds a B.S.
Last time we delved into AutoGPT and GPT-Engineering , the early mainstream open-source LLM-based AI agents designed to automate complex tasks. Enter MetaGPT — a Multi-agent system that utilizes Large Language models by Sirui Hong fuses Standardized Operating Procedures (SOPs) with LLM-based multi-agent systems.
Using generative artificial intelligence (AI) solutions to produce computer code helps streamline the softwaredevelopment process and makes it easier for developers of all skill levels to write code. It can also modernize legacy code and translate code from one programming language to another.
However, the industry is seeing enough potential to consider LLMs as a valuable option. The following are a few potential benefits: Improved accuracy and consistency LLMs can benefit from the high-quality translations stored in TMs, which can help improve the overall accuracy and consistency of the translations produced by the LLM.
As the demand for large language models (LLMs) continues to rise, ensuring fast, efficient, and scalable inference has become more crucial than ever. NVIDIA's TensorRT-LLM steps in to address this challenge by providing a set of powerful tools and optimizations specifically designed for LLM inference.
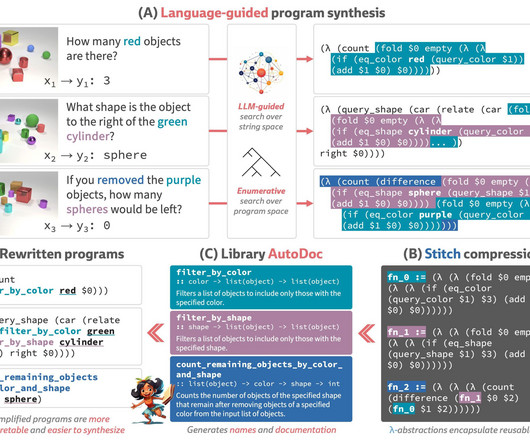
Big language models (LLMs) are becoming increasingly skilled in programming in various contexts, such as finishing partly written code, interacting with human programmers, and even figuring out challenging programming riddles at the competition level. Figure 1: The LILO learning loop overview. (Al)
Diamond Bishop , CEO and co-founder at Augmend , a Seattle collaboration software startup Diamond Bishop, CEO of Augmend. Augmend Photo) “AI is making it so small startups like ours can accelerate all aspects of the softwaredevelopment lifecycle. It’s helpful with generating much of the boilerplate for unit tests.
Visit octus.com to learn how we deliver rigorously verified intelligence at speed and create a complete picture for professionals across the entire credit lifecycle. With this LLM, CreditAI was now able to respond better to broader, industry-wide queries than before. Follow Octus on LinkedIn and X.
A recent MIT study points to this , showing how when white-collar workers had access to an assistive chatbot, it took them 40% less time to complete a task, while the quality of their work increased by 18%. The company just axed 28% of its workforce owing to a nosedive in traffic since the advent of LLM-based chatbots.
GPT-4: Prompt Engineering ChatGPT has transformed the chatbot landscape, offering human-like responses to user inputs and expanding its applications across domains – from softwaredevelopment and testing to business communication, and even the creation of poetry. This demonstrates a classic case of ‘knowledge conflict'.
The user prompt is augmented along with the results returned from the knowledge base as an additional context and sent to the LLM to generate a response. Create a knowledge base To create a new knowledge base in Amazon Bedrock, complete the following steps. You should see a Successfully built message when the build is complete.
This version offers support for new models (including Mixture of Experts), performance and usability improvements across inference backends, as well as new generation details for increased control and prediction explainability (such as reason for generation completion and token level log probabilities).
The LMI container has a powerful serving stack called DJL serving that is agnostic to the underlying LLM. It provides system-level configuration parameters that can be tuned for extracting the best performance of the hosting infrastructure for a given LLM. These cached key and value tensors are often referred to as the KV cache.
The following figure shows the Discovery Navigator generative AI auto-summary pipeline. The generative AI large language model (LLM) can be prompted with questions or asked to summarize a given text. In that role, she completed and obtained CMS approval of hundreds of Medicare Set Asides.
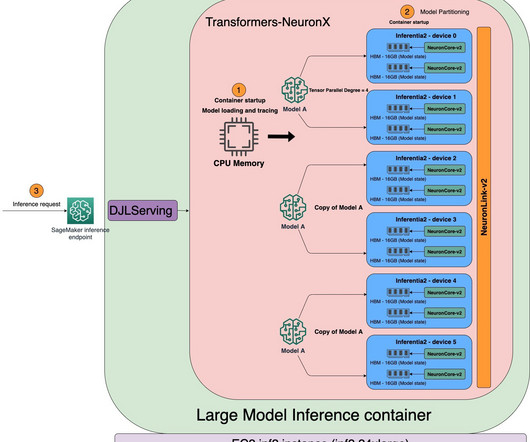
Last week, Technology Innovation Institute (TII) launched TII Falcon LLM , an open-source foundational large language model (LLM). The result of this effort is TII Falcon LLM. SageMaker large model inference DLCs simplify LLM hosting Hosting LLMs such as Falcon-40B and Falcon-7B can be challenging.
We use the AWS Neuron softwaredevelopment kit (SDK) to access the AWS Inferentia2 device and benefit from its high performance. This compiles and serve an LLM on an Inf2 instance. The complete code samples with instructions can be found in this GitHub repository.
Llama 2 stands at the forefront of AI innovation, embodying an advanced auto-regressive language model developed on a sophisticated transformer foundation. In this post, we explore best practices for prompting the Llama 2 Chat LLM. The complete example is shown in the accompanying notebook.
Deploy a SageMaker model In the most basic scenario, all you need to do is select a deployable model from the Models page or an LLM from the SageMaker JumpStart page, select an instance type, set the initial instance count, and deploy the model. You can also edit the auto scaling policy on the Auto-scaling tab on this page.
This technique improves LLM inference throughput and output token latency (TPOT). Next, we perform auto-regressive token generation where the output tokens are generated sequentially. This means we will be repeating this process more times to complete the response, resulting in slower overall processing.
Complete the following steps: Launch the provided CloudFormation template. When the stack is complete, you can move to the next step. Complete the following steps: On the Amazon ECR console, create a new repository. To do a complete cleanup, delete the CloudFormation stack to remove all resources created by this template.
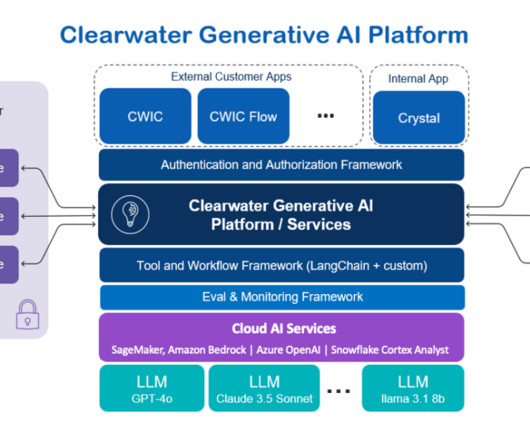
Clearwaters LLM operations (LLMOps) pipeline plays a crucial role in this process, automating the evaluation and seamless integration of new models. This commitment to using the most effective LLMs for each unique task with cutting-edge technology and optimal performance is the cornerstone of Clearwaters approach.
For ultra-large models that don’t fit into a single accelerator, data flows directly between accelerators with NeuronLink, bypassing the CPU completely. These endpoints are fully managed and support auto scaling. xlarge" ) Refer to Developer Flows for more details on typical development flows of Inf2 on SageMaker with sample scripts.
From self-driving cars to language models that can engage in human-like conversations, AI is rapidly transforming various industries, and softwaredevelopment is no exception. This remarkable tool leverages state-of-the-art language models like GPT-4, streamlining the development cycle and enhancing developer productivity.
70B marks an exciting advancement in large language model (LLM) development, offering comparable performance to larger Llama versions with fewer computational resources. 70B using the SageMaker JumpStart UI, complete the following steps: In SageMaker Unified Studio, on the Build menu, choose JumpStart models. What sets Llama 3.3
Before MonsterAPI, he ran two startups, including one that developed a wearable safety device for women in India, in collaboration with the Government of India and IIT Delhi. Our Mission has always been “to help softwaredevelopers fine-tune and deploy AI models faster and in the easiest manner possible.”
Today, as part of Amazon Web Services’ partnership with Hugging Face, we are excited to announce the release of a new Hugging Face Deep Learning Container (DLC) for inference with Large Language Models (LLMs). Hosting LLMs at scale presents a unique set of complex engineering challenges. You can find our complete example notebook here.
For instance, a financial firm that needs to auto-generate a daily activity report for internal circulation using all the relevant transactions can customize the model with proprietary data, which will include past reports, so that the FM learns how these reports should read and what data was used to generate them.
collection of multilingual large language models (LLMs), which includes pre-trained and instruction tuned generative AI models in 8B, 70B, and 405B sizes, is available through Amazon SageMaker JumpStart to deploy for inference. is an auto-regressive language model that uses an optimized transformer architecture. The Llama 3.1
SageMaker AI makes sure that sensitive data stays completely within each customer’s SageMaker environment and will never be shared with a third party. Deepchecks Deepchecks specializes in LLM evaluation. Zuoyuan Huang is a SoftwareDevelopment Manager at AWS. You can find him on LinkedIn. You can find him on LinkedIn.
Next, you need to index this data to make it available for a Retrieval Augmented Generation (RAG) approach, where relevant passages are delivered with high accuracy to a large language model (LLM). Complete the following steps to create your application: On the Amazon Q Business console, choose Applications in the navigation pane.
The integration of these multimodal capabilities has unlocked new possibilities for businesses and individuals, revolutionizing fields such as content creation, visual analytics, and softwaredevelopment. In the metadata.jsonl file, each example is a dictionary that contains three keys named file_name , prompt , and completion.
This process is like assembling a jigsaw puzzle to form a complete picture of the malwares capabilities and intentions, with pieces constantly changing shape. Deep Instinct, recognizing this need, has developed DIANNA (Deep Instincts Artificial Neural Network Assistant), the DSX Companion.
For LLMs that often require high throughput and low-latency inference requests, this loading process can add significant overhead to the total deployment and scaling time, potentially impacting application performance during traffic spikes. This post is Part 1 of a series exploring Fast Model Loader.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content