This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
GPT-4: PromptEngineering ChatGPT has transformed the chatbot landscape, offering human-like responses to user inputs and expanding its applications across domains – from software development and testing to business communication, and even the creation of poetry. Imagine you're trying to translate English to French.
Promptengineering , the art and science of crafting prompts that elicit desired responses from LLMs, has become a crucial area of research and development. In this comprehensive technical blog, we'll delve into the latest cutting-edge techniques and strategies that are shaping the future of promptengineering.
However, the industry is seeing enough potential to consider LLMs as a valuable option. The following are a few potential benefits: Improved accuracy and consistency LLMs can benefit from the high-quality translations stored in TMs, which can help improve the overall accuracy and consistency of the translations produced by the LLM.
However, the world of LLMs isn't simply a plug-and-play paradise; there are challenges in usability, safety, and computational demands. In this article, we will dive deep into the capabilities of Llama 2 , while providing a detailed walkthrough for setting up this high-performing LLM via Hugging Face and T4 GPUs on Google Colab.
In many generative AI applications, a large language model (LLM) like Amazon Nova is used to respond to a user query based on the models own knowledge or context that it is provided. Instead of relying on promptengineering, tool choice forces the model to adhere to the settings in place.
Current Landscape of AI Agents AI agents, including Auto-GPT, AgentGPT, and BabyAGI, are heralding a new era in the expansive AI universe. AI Agents vs. ChatGPT Many advanced AI agents, such as Auto-GPT and BabyAGI, utilize the GPT architecture. Their primary focus is to minimize the need for human intervention in AI task completion.
Instead of formalized code syntax, you provide natural language “prompts” to the models When we pass a prompt to the model, it predicts the next words (tokens) and generates a completion. 2022 where, instead of adding examples for Few Shot CoT, we just add “Let’s think step by step” to the prompt. Source : Wei et al.
Last time we delved into AutoGPT and GPT-Engineering , the early mainstream open-source LLM-based AI agents designed to automate complex tasks. Enter MetaGPT — a Multi-agent system that utilizes Large Language models by Sirui Hong fuses Standardized Operating Procedures (SOPs) with LLM-based multi-agent systems.
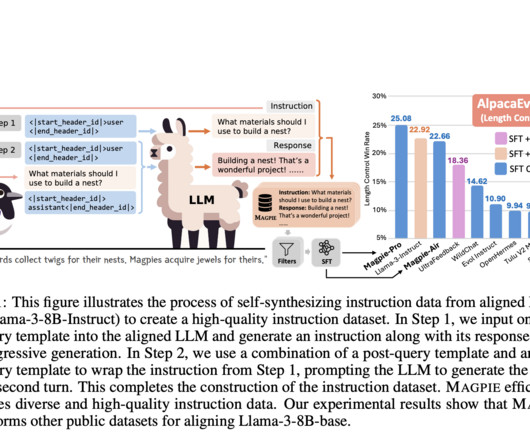
This limitation hinders the advancement of LLM capabilities and their application in diverse, real-world scenarios. Existing methods for generating instruction datasets fall into two categories: human-curated data and synthetic data produced by LLMs. The model then generates diverse user queries based on these templates.
LangChain is an open-source framework that allows developers to build LLM-based applications easily. It provides for easily connecting LLMs with external data sources to augment the capabilities of these models and achieve better results. It teaches how to build LLM-powered applications using LangChain using hands-on exercises.
Redfin Photo) “We’ve already found a number of places where AI tools are making our engineers more efficient. The auto-complete and auto-suggestions in Visual Studio Code are pretty good, too, without being annoying. ” We’ve also found ways to use these tools to help us serve customers more efficiently.
Here are ten proven strategies to reduce LLM inference costs while maintaining performance and accuracy: Quantization Quantization is a technique that decreases the precision of model weights and activations, resulting in a more compact representation of the neural network.
A prompt is the information you pass into an LLM to elicit a response. The process of designing and refining prompts to get specific responses from these models is called promptengineering. With prompt chaining, you construct a set of smaller subtasks as individual prompts.
Evolving Trends in PromptEngineering for Large Language Models (LLMs) with Built-in Responsible AI Practices Editor’s note: Jayachandran Ramachandran and Rohit Sroch are speakers for ODSC APAC this August 22–23. Various prompting techniques, such as Zero/Few Shot, Chain-of-Thought (CoT)/Self-Consistency, ReAct, etc.
TL;DR Hallucinations are an inherent feature of LLMs that becomes a bug in LLM-based applications. Effective mitigation strategies involve enhancing data quality, alignment, information retrieval methods, and promptengineering. What are LLM hallucinations? In 2022, when GPT-3.5
The following figure shows the Discovery Navigator generative AI auto-summary pipeline. Verisk’s evaluation involved three major parts: Promptengineering – Promptengineering is the process where you guide generative AI solutions to generate desired output.
It allows LLMs to reference authoritative knowledge bases or internal repositories before generating responses, producing output tailored to specific domains or contexts while providing relevance, accuracy, and efficiency. Generation is the process of generating the final response from the LLM.
Combined with large language models (LLM) and Contrastive Language-Image Pre-Training (CLIP) trained with a large quantity of multimodality data, visual language models (VLMs) are particularly adept at tasks like image captioning, object detection and segmentation, and visual question answering.
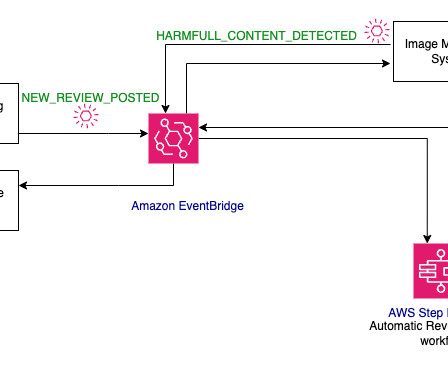
The insurance provider receives payout claims from the beneficiary’s attorney for different insurance types, such as home, auto, and life insurance. When this is complete, the document can be routed to the appropriate department or downstream process. The following diagram outlines the proposed solution architecture. append(e["Text"].upper())
To improve the quality of output, approaches like n-short learning, Promptengineering, Retrieval Augmented Generation (RAG) and fine tuning are used. In addition to QLoRA, bitsanbytes is used to convert to 4-bit precision to quantize frozen LLM to 4-bit and attach LoRA adapters on it.
Whether you’re interfacing with models remotely or running them locally, understanding key techniques like promptengineering and output structuring can substantially improve performance for your specific applications. These services handle the complex computational requirements, allowing developers to focus on implementation.
TL;DR LLMOps involves managing the entire lifecycle of Large Language Models (LLMs), including data and prompt management, model fine-tuning and evaluation, pipeline orchestration, and LLM deployment. Prompt-response management: Refining LLM-backed applications through continuous prompt-response optimization and quality control.
To store information in Secrets Manager, complete the following steps: On the Secrets Manager console, choose Store a new secret. Complete the following steps: On the Secrets Manager console, choose Store a new secret. This adaptation is facilitated through the use of LLMprompts.
Foundation models, Alex said, yield results that are “nothing short of breathtaking,” but they’re not a complete answer for enterprises who aim to solve challenges using machine learning. “We We are, in our view, in a bit of a hype cycle,” he said.
Foundation models, Alex said, yield results that are “nothing short of breathtaking,” but they’re not a complete answer for enterprises who aim to solve challenges using machine learning. “We We are, in our view, in a bit of a hype cycle,” he said.
The platform also offers features for hyperparameter optimization, automating model training workflows, model management, promptengineering, and no-code ML app development. Can you see the complete model lineage with data/models/experiments used downstream? Is it fast and reliable enough for your workflow?
Ali Arsanjani, director of cloud partner engineering at Google Cloud , presented a talk entitled “Challenges and Ethics of DLM and LLM Adoption in the Enterprise” at Snorkel AI’s recent Foundation Model Virtual Summit. Others, toward language completion and further downstream tasks.
Ali Arsanjani, director of cloud partner engineering at Google Cloud , presented a talk entitled “Challenges and Ethics of DLM and LLM Adoption in the Enterprise” at Snorkel AI’s recent Foundation Model Virtual Summit. Others, toward language completion and further downstream tasks.
On a more advanced stance, everyone who has done SQL query optimisation will know that many roads lead to the same result, and semantically equivalent queries might have completely different syntax. 3] provides a more complete survey of Text2SQL data augmentation techniques.
Not only are large language models (LLMs) capable of answering a users question based on the transcript of the file, they are also capable of identifying the timestamp (or timestamps) of the transcript during which the answer was discussed. Each citation can point to a different video, or to different timestamps within the same video.
Two open-source libraries, Ragas (a library for RAG evaluation) and Auto-Instruct, used Amazon Bedrock to power a framework that evaluates and improves upon RAG. Generating improved instructions for each question-and-answer pair using an automatic promptengineering technique based on the Auto-Instruct Repository.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content