This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With advancements in deep learning, naturallanguageprocessing (NLP), and AI, we are in a time period where AI agents could form a significant portion of the global workforce. Current Landscape of AI Agents AI agents, including Auto-GPT, AgentGPT, and BabyAGI, are heralding a new era in the expansive AI universe.
It can also modernize legacy code and translate code from one programming language to another. Auto-generated code suggestions can increase developers’ productivity and optimize their workflow by providing straightforward answers, handling routine coding tasks, reducing the need to context switch and conserving mental energy.
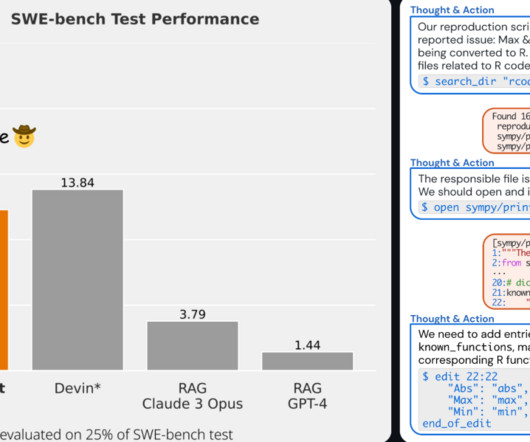
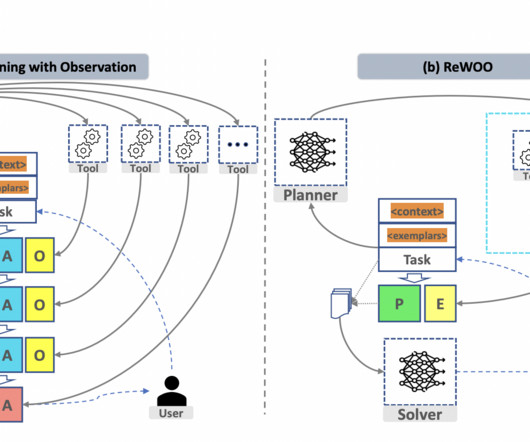
SWE agent LLMLLM Agents: Orchestrating Task Automation LLM agents are sophisticated software entities designed to automate the execution of complex tasks. The operation of an LLM agent can be visualized as a dynamic sequence of steps, meticulously orchestrated to fulfill the given task.
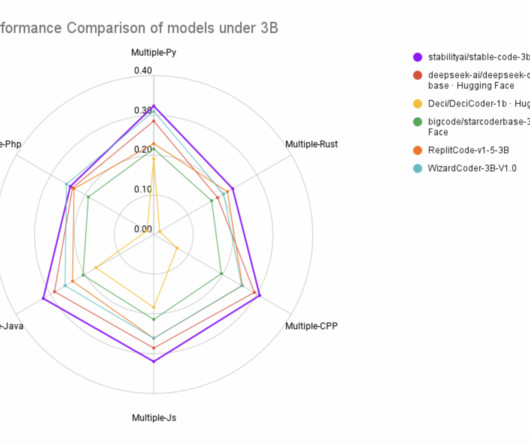
Stable AI has recently released a new state-of-the-art model, Stable-Code-3B , designed for code completion in various programming languages with multiple additional capabilities. trillion tokens including both naturallanguage data and code data in 18 programming languages and codes. It is trained on 1.3
As the demand for large language models (LLMs) continues to rise, ensuring fast, efficient, and scalable inference has become more crucial than ever. NVIDIA's TensorRT-LLM steps in to address this challenge by providing a set of powerful tools and optimizations specifically designed for LLM inference.
Large language models (LLMs) such as ChatGPT and Llama have garnered substantial attention due to their exceptional naturallanguageprocessing capabilities, enabling various applications ranging from text generation to code completion. Check out the Reference Page and Project Page.
By combining LLMs’ creative generation abilities with retrieval systems’ factual accuracy, RAG offers a solution to one of LLMs’ most persistent challenges: hallucination. They are crucial for machine learning applications, particularly those involving naturallanguageprocessing and image recognition.
Since Meta released the latest open-source Large Language Model (LLM), Llama3, various development tools and frameworks have been actively integrating Llama3. Copilot leverages naturallanguageprocessing and machine learning to generate high-quality code snippets and context information.
DeepSeek-R1 , developed by AI startup DeepSeek AI , is an advanced large language model (LLM) distinguished by its innovative, multi-stage training process. Model Variants The current DeepSeek model collection consists of the following models: DeepSeek-V3 An LLM that uses a Mixture-of-Experts (MoE) architecture.
Another innovative technique is the Tree of Thoughts (ToT) prompting, which allows the LLM to generate multiple lines of reasoning or “thoughts” in parallel, evaluate its own progress towards the solution, and backtrack or explore alternative paths as needed.
This advancement has spurred the commercial use of generative AI in naturallanguageprocessing (NLP) and computer vision, enabling automated and intelligent data extraction. Image and Document Processing Multimodal LLMs have completely replaced OCR.
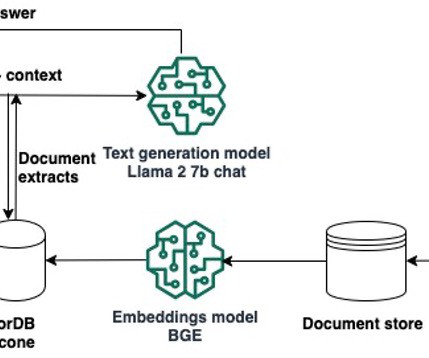
Retrieval Augmented Generation (RAG) allows you to provide a large language model (LLM) with access to data from external knowledge sources such as repositories, databases, and APIs without the need to fine-tune it. There are two models in this implementation: the embeddings model and the LLM that generates the final response.
Augmented LLMs are the ones that are added with external tools and skills in order to increase their performance so that they perform beyond their inherent capabilities. Applications like Auto-GPT for autonomous task execution have been made possible by Augmented Language Models (ALMs) only.
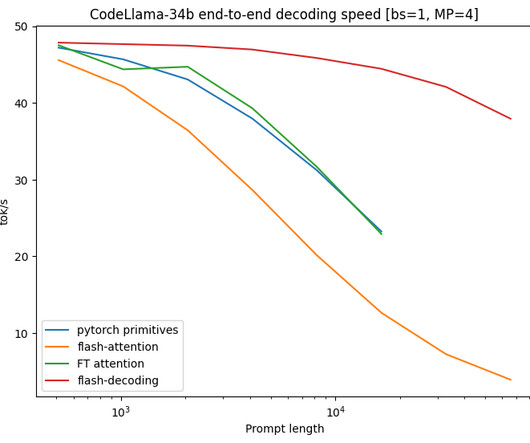
Transformer architectures have revolutionized NaturalLanguageProcessing (NLP), enabling significant language understanding and generation progress. One promising solution is Speculative Decoding (SD), a method designed to accelerate LLM inference without compromising generated output quality.
Visit octus.com to learn how we deliver rigorously verified intelligence at speed and create a complete picture for professionals across the entire credit lifecycle. With this LLM, CreditAI was now able to respond better to broader, industry-wide queries than before. Follow Octus on LinkedIn and X.
These technologies together enable NVIDIA Avatar Cloud Engine , or ACE, and multimodal language models to work together with the NVIDIA DRIVE platform to let automotive manufacturers develop their own intelligent in-car assistants. Li Auto unveiled its multimodal cognitive model, Mind GPT, in June.
Articles ThunderMLA from Stanford researchers, a new optimization approach for variable-length sequence processing to large language model inference that addresses critical performance bottlenecks in attention mechanisms. Moreover, users can easily extend to other LLM training and inference frameworks.
Today, as part of Amazon Web Services’ partnership with Hugging Face, we are excited to announce the release of a new Hugging Face Deep Learning Container (DLC) for inference with Large Language Models (LLMs). Hosting LLMs at scale presents a unique set of complex engineering challenges.
Next you need to index this data to make it available for a Retrieval Augmented Generation (RAG) approach where relevant passages are delivered with high accuracy to a large language model (LLM). Ensure the ingested documents are added in the Sync history tab and are in the Completed status. Sign in as user Alejandro Rosales.
Below, we'll give you the basic know-how you need to understand LLMs, how they work, and the best models in 2023. What Is a Large Language Model? A large language model (often abbreviated as LLM) is a machine-learning model designed to understand, generate, and interact with human language.
The LMI container has a powerful serving stack called DJL serving that is agnostic to the underlying LLM. It provides system-level configuration parameters that can be tuned for extracting the best performance of the hosting infrastructure for a given LLM. These cached key and value tensors are often referred to as the KV cache.
Einstein has a list of over 60 features, unlocked at different price points and segmented into four main categories: machine learning (ML), naturallanguageprocessing (NLP), computer vision, and automatic speech recognition. LMI containers are a set of high-performance Docker Containers purpose built for LLM inference.
This technique provides targeted yet broad-ranging search capabilities, furnishing the LLM with a wider perspective. It tackles the issue of information overload and irrelevant data processing head-on, leading to improved response quality, more cost-effective LLM operations, and a smoother overall retrieval process.
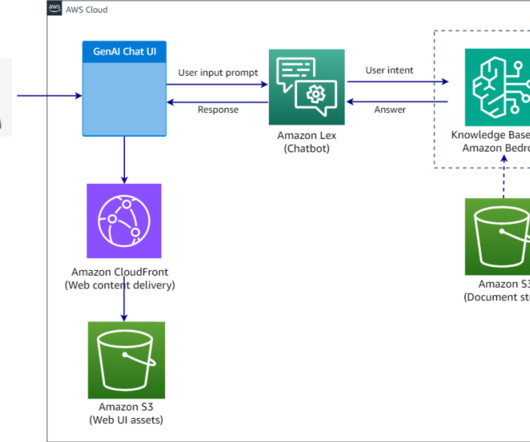
The user prompt is augmented along with the results returned from the knowledge base as an additional context and sent to the LLM to generate a response. Create a knowledge base To create a new knowledge base in Amazon Bedrock, complete the following steps. You should see a Successfully built message when the build is complete.
These models have revolutionized various computer vision (CV) and naturallanguageprocessing (NLP) tasks, including image generation, translation, and question answering. To make sure that our endpoint can scale down to zero, we need to configure auto scaling on the asynchronous endpoint using Application Auto Scaling.
Using machine learning (ML) and naturallanguageprocessing (NLP) to automate product description generation has the potential to save manual effort and transform the way ecommerce platforms operate. BLIP-2 consists of three models: a CLIP-like image encoder, a Querying Transformer (Q-Former) and a large language model (LLM).
Large language models (LLMs) used to generate text sequences need immense amounts of computing power and have difficulty accessing the available high bandwidth memory (HBM) and compute capacity. The parameters can be loaded one time and used to process multiple input sequences.
Unlike traditional machine learning where outcomes are often binary, LLM outputs dwell in a spectrum of correctness. Therefore, a holistic approach to evaluating LLMs must utilize a variety of approaches, such as using LLMs to evaluate LLMs (i.e., auto-evaluation) and using human-LLM hybrid approaches.
It also enables operational capabilities including automated testing, conversation analytics, monitoring and observability, and LLM hallucination prevention and detection. “We An optional CloudFormation stack to enable an asynchronous LLM hallucination detection feature. seconds or less. The stack will take about 10 minutes to deploy.
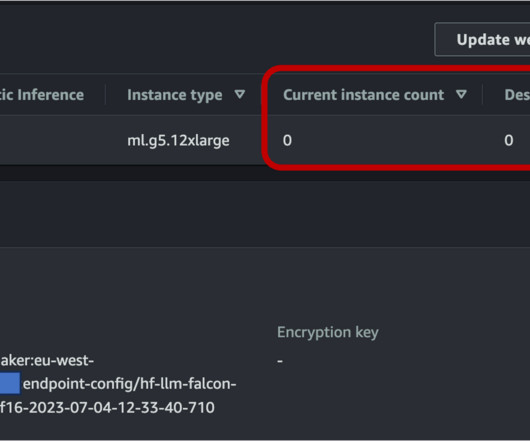
Last week, Technology Innovation Institute (TII) launched TII Falcon LLM , an open-source foundational large language model (LLM). The result of this effort is TII Falcon LLM. SageMaker large model inference DLCs simplify LLM hosting Hosting LLMs such as Falcon-40B and Falcon-7B can be challenging.
It’s a next generation model in the Falcon family—a more efficient and accessible large language model (LLM) that is trained on a 5.5 It’s built on causal decoder-only architecture, making it powerful for auto-regressive tasks. After deployment is complete, you will see that an endpoint is created.
Conversational AI refers to technology like a virtual agent or a chatbot that use large amounts of data and naturallanguageprocessing to mimic human interactions and recognize speech and text. Here are some other open-source large language models (LLMs) that are revolutionizing conversational AI. trillion tokens.
Visual languageprocessing (VLP) is at the forefront of generative AI, driving advancements in multimodal learning that encompasses language intelligence, vision understanding, and processing. Central to the architecture are the fine-tuned VLM and LLM, both instrumental in decoding visual and textual data streams.
Customers can create the custom metadata using Amazon Comprehend , a natural-languageprocessing (NLP) service managed by AWS to extract insights about the content of documents, and ingest it into Amazon Kendra along with their data into the index. For example, metadata can be used for filtering and searching. append(e["Text"].upper())
In recent years, we have seen a big increase in the size of large language models (LLMs) used to solve naturallanguageprocessing (NLP) tasks such as question answering and text summarization. This technique improves LLM inference throughput and output token latency (TPOT). compared to 76.4).
To get started, complete the following steps: On the File menu, choose New and Terminal. Use CodeWhisperer in Studio After we complete the installation steps, we can use CodeWhisperer by opening a new notebook or Python file. To get started, complete the following steps: On the File menu, choose New and Terminal.
You don’t need to have a PhD to understand the billion parameter language model GPT is a general-purpose naturallanguageprocessing model that revolutionized the landscape of AI. GPT-3 is a autoregressive language model created by OpenAI, released in 2020 . What is GPT-3?
Llama2 by Meta is an example of an LLM offered by AWS. Llama 2 is an auto-regressive language model that uses an optimized transformer architecture and is intended for commercial and research use in English. This results in faster restarts and workload completion.
LLMs’ generative abilities make them popular for text synthesis, summarization, machine translation, and more. The size of an LLM and its training data is a double-edged sword: it brings modeling quality, but entails infrastructure challenges. In the past few years, numerous customers have been using the AWS Cloud for LLM training.
In the field of NaturalLanguageProcessing (NLP), Retrieval Augmented Generation, or RAG, has attracted much attention lately. To make sure the knowledge base is as precise and complete as feasible, duplicates should also be removed. For this process, choosing the optimal embedding and reranked models is essential.
Imagine you’re facing the following challenge: you want to develop a Large Language Model (LLM) that can proficiently respond to inquiries in Portuguese. We will fine-tune different foundation LLM models on a dataset, evaluate them, and select the best model. You have a valuable dataset and can choose from various base models.
Be sure to check out their talk, “Evolving Trends in Prompt Engineering for Large Language Models (LLMs) with Built-in Responsible AI Practices,” there! At the core of efficient LLM utilization lies the art of prompt engineering which involves crafting prompts that guide LLMs effectively, paving the way for reliable responses.
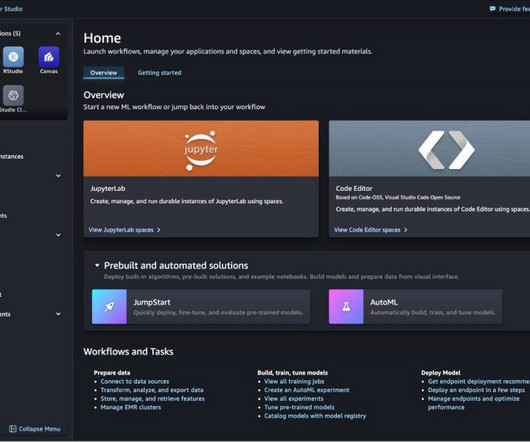
Complete the following steps to edit an existing space: On the space details page, choose Stop space. It serves as an essential tool for both beginner and seasoned coders, providing insights into best practices, accelerating the development process, and improving the overall quality of code. Choose Create JupyterLab space.
An application using the RAG approach retrieves information most relevant to the user’s request from the enterprise knowledge base or content, bundles it as context along with the user’s request as a prompt, and then sends it to the LLM to get a response. The LLM returns with a response that is based on the retrieved documents.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content