
FastGen: Cutting GPU Memory Costs Without Compromising on LLM Quality
Marktechpost
MAY 12, 2024
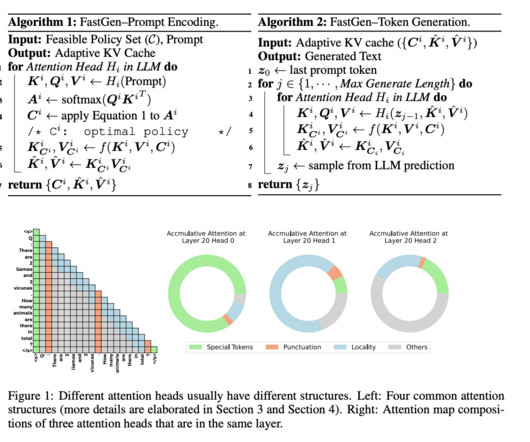
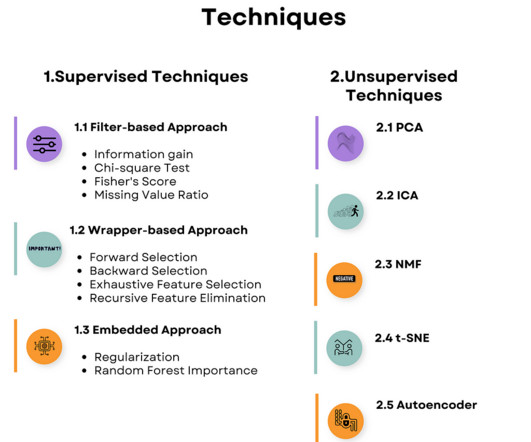
However, these models are only applied to non-autoregressive models and require an extra re-training phrase, making them less suitable for auto-regressive LLMs like ChatGPT and Llama. It is important to consider pruning tokens’ potential within the KV cache of auto-regressive LLMs to fill this gap.




























Let's personalize your content