This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Largelanguagemodels (LLMs) have demonstrated promising capabilities in machine translation (MT) tasks. Depending on the use case, they are able to compete with neural translation models such as Amazon Translate. When the indexing is complete, select the created index from the index dropdown.
70B marks an exciting advancement in largelanguagemodel (LLM) development, offering comparable performance to larger Llama versions with fewer computational resources. 70B using the SageMaker JumpStart UI, complete the following steps: In SageMaker Unified Studio, on the Build menu, choose JumpStart models.
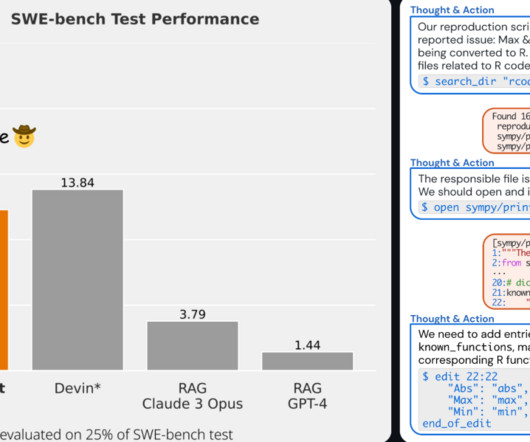
From self-driving cars to languagemodels that can engage in human-like conversations, AI is rapidly transforming various industries, and softwaredevelopment is no exception. However, the advent of AI-powered software engineers like SWE-Agent has the potential to disrupt this age-old paradigm.
Softwaredevelopment is one arena where we are already seeing significant impacts from generative AI tools. A McKinsey study claims that softwaredevelopers can complete coding tasks up to twice as fast with generative AI. This can aid in maintaining code quality and performance over time.
This enhancement builds upon the existing auto scaling capabilities in SageMaker, offering more granular control over resource allocation. Compressed model files may save storage space, but they require additional time to uncompress and files can’t be downloaded in parallel, which can slow down the scale-up process.
With LargeLanguageModels (LLMs) like ChatGPT, OpenAI has witnessed a surge in enterprise and user adoption, currently raking in around $80 million in monthly revenue. To actualize an agile, flexible software architecture that can adapt to dynamic programming tasks.
As the demand for largelanguagemodels (LLMs) continues to rise, ensuring fast, efficient, and scalable inference has become more crucial than ever. This comprehensive guide will explore all aspects of TensorRT-LLM, from its architecture and key features to practical examples for deploying models. build/tensorrt_llm*.whl
With the rise of largelanguagemodels (LLMs) like Meta Llama 3.1, there is an increasing need for scalable, reliable, and cost-effective solutions to deploy and serve these models. 8B model With the setup complete, you can now deploy the model using a Kubernetes deployment.
Using generative artificial intelligence (AI) solutions to produce computer code helps streamline the softwaredevelopment process and makes it easier for developers of all skill levels to write code. It can also modernize legacy code and translate code from one programming language to another.
Although blue/green deployment has been a reliable strategy for zero-downtime updates, its limitations become glaring when deploying large-scale largelanguagemodels (LLMs) or high-throughput models on premium GPU instances. Now another two free GPU slots are available.
Diamond Bishop , CEO and co-founder at Augmend , a Seattle collaboration software startup Diamond Bishop, CEO of Augmend. Augmend Photo) “AI is making it so small startups like ours can accelerate all aspects of the softwaredevelopment lifecycle. Intellisense and language plugins like Pylance have been around for a while.
One such model that has garnered considerable attention is OpenAI's ChatGPT , a shining exemplar in the realm of LargeLanguageModels. Prompt design and engineering are growing disciplines that aim to optimize the output quality of AI models like ChatGPT.
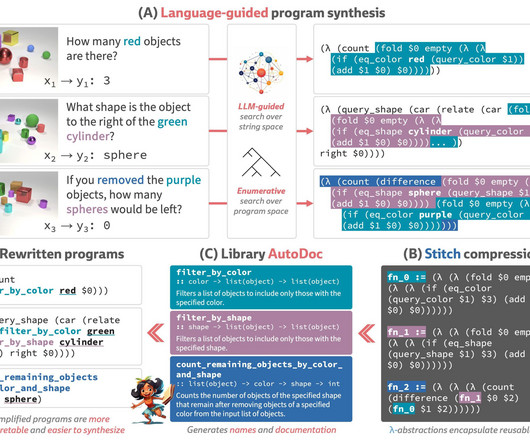
Big languagemodels (LLMs) are becoming increasingly skilled in programming in various contexts, such as finishing partly written code, interacting with human programmers, and even figuring out challenging programming riddles at the competition level. Figure 1: The LILO learning loop overview. (Al)
A recent MIT study points to this , showing how when white-collar workers had access to an assistive chatbot, it took them 40% less time to complete a task, while the quality of their work increased by 18%. When To Use A Tool Like Copilot ChatGPT isn’t the only largelanguagemodel-based tool out there.
Before MonsterAPI, he ran two startups, including one that developed a wearable safety device for women in India, in collaboration with the Government of India and IIT Delhi. Our Mission has always been “to help softwaredevelopers fine-tune and deploy AI models faster and in the easiest manner possible.”
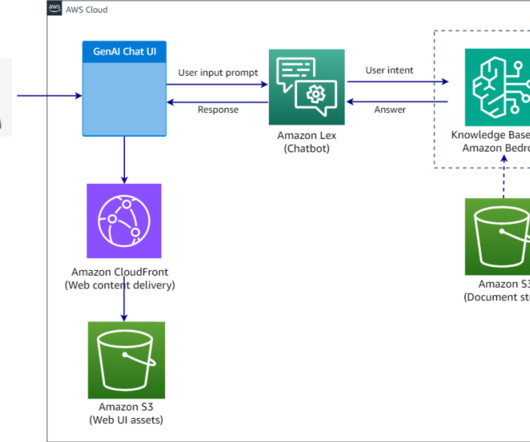
It features natural language understanding capabilities to recognize more accurate identification of user intent and fulfills the user intent faster. Amazon Bedrock simplifies the process of developing and scaling generative AI applications powered by largelanguagemodels (LLMs) and other foundation models (FMs).
The added benefit of asynchronous inference is the cost savings by auto scaling the instance count to zero when there are no requests to process. Hugging Face is a popular open source hub for machine learning (ML) models. Prerequisites Complete the following prerequisites: Create a SageMaker domain.
The following figure shows the Discovery Navigator generative AI auto-summary pipeline. The OCR converted medical record pages are processed through Verisk’s AI models and select pages are sent to Amazon Bedrock using AWS PrivateLink , for generating visit summaries. Kate Riordan is the Director of Automation Initiatives at Verisk.
Today, as part of Amazon Web Services’ partnership with Hugging Face, we are excited to announce the release of a new Hugging Face Deep Learning Container (DLC) for inference with LargeLanguageModels (LLMs). The Hugging Face LLM DLC provides these optimizations out of the box and makes it easier to host LLM models at scale.
Visit octus.com to learn how we deliver rigorously verified intelligence at speed and create a complete picture for professionals across the entire credit lifecycle. The Q&A handler, running on AWS Fargate, orchestrates the complete query response cycle by coordinating between services and processing responses through the LLM pipeline.
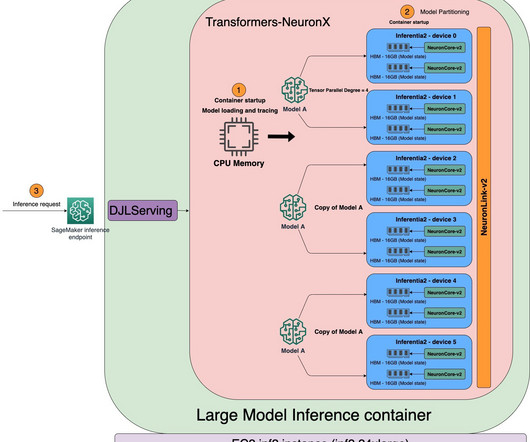
We use the AWS Neuron softwaredevelopment kit (SDK) to access the AWS Inferentia2 device and benefit from its high performance. We then use a largemodel inference container powered by Deep Java Library (DJLServing) as our model serving solution. GPU Optimized Kernel using a ml.g5.2xlarge instance type.
Amazon CodeWhisperer is a generative AI coding companion that speeds up softwaredevelopment by making suggestions based on the existing code and natural language comments, reducing the overall development effort and freeing up time for brainstorming, solving complex problems, and authoring differentiated code.
In recent years, we have seen a big increase in the size of largelanguagemodels (LLMs) used to solve natural language processing (NLP) tasks such as question answering and text summarization. Introduction Modern languagemodels are based on the transformer architecture. compared to 76.4).
What is the optimal framework and configuration for hosting largelanguagemodels (LLMs) for text-generating generative AI applications? The decode phase includes the following: Completion – After the prefill phase, you have a partially generated text that may be incomplete or cut off at some point. The default is 32.
Created Using Midjourney Largelanguagemodels (LLMs) pretrained on extensive source code, referred to as “Code LLMs,” have revolutionized code intelligence in recent years. Secondly, current models rely on a limited set of pretraining objectives that may not be optimal for certain downstream tasks.
This version offers support for new models (including Mixture of Experts), performance and usability improvements across inference backends, as well as new generation details for increased control and prediction explainability (such as reason for generation completion and token level log probabilities).
To give a sense for the change in scale, the largest pre-trained model in 2019 was 330M parameters. Now, the largest models are more than 500B parameters—a 1,600x increase in size in just a few years. Today’s FMs, such as the largelanguagemodels (LLMs) GPT3.5
Last week, Technology Innovation Institute (TII) launched TII Falcon LLM , an open-source foundational largelanguagemodel (LLM). Legacy hosting solutions used for smaller models typically don’t offer this type of functionality, adding to the difficulty. Qing Lan is a SoftwareDevelopment Engineer in AWS.
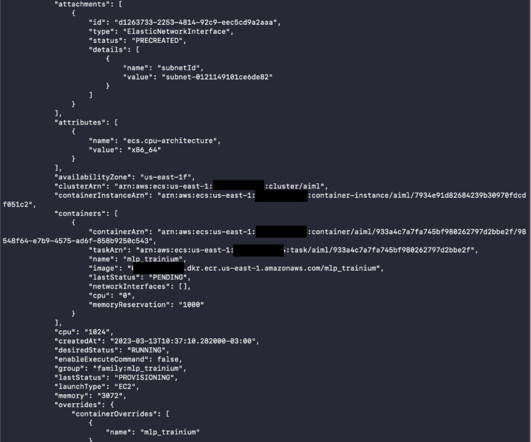
Complete the following steps: Launch the provided CloudFormation template. When the stack is complete, you can move to the next step. We use Amazon ECR to store a custom Docker image containing our scripts and Neuron packages needed to train a model with ECS jobs running on Trn1 instances. For this post, we use trainium-key.
Today, we are excited to announce that Amazon SageMaker supports AWS Inferentia2 (ml.inf2) and AWS Trainium (ml.trn1) based SageMaker instances to host generative AI models for real-time and asynchronous inference. ml.inf2 instances are available for model deployment on SageMaker in US East (Ohio) and ml.trn1 instances in US East (N.
The Test inference tab enables you to test your model by sending test requests to one of the in-service models directly from the SageMaker Studio interface. You can also edit the auto scaling policy on the Auto-scaling tab on this page. Some familiarity with SageMaker Studio is also assumed.
collection of multilingual largelanguagemodels (LLMs), which includes pre-trained and instruction tuned generative AI models in 8B, 70B, and 405B sizes, is available through Amazon SageMaker JumpStart to deploy for inference. is an auto-regressive languagemodel that uses an optimized transformer architecture.
We have also seen significant success in using largelanguagemodels (LLMs) trained on source code (instead of natural language text data) that can assist our internal developers, as described in ML-Enhanced Code Completion Improves Developer Productivity. (See paper for details.)
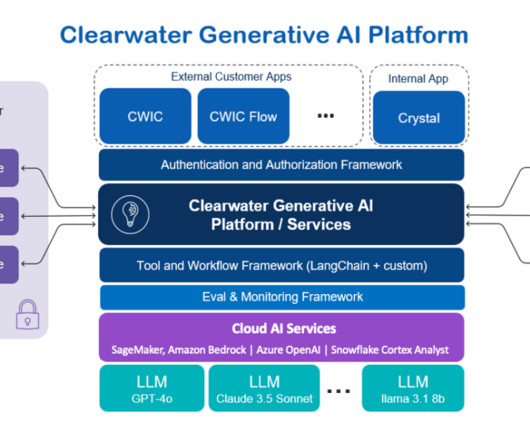
A great example of such innovation is our customer Clearwater Analytics and their use of largelanguagemodels (LLMs) hosted on Amazon SageMaker JumpStart , which has propelled asset management productivity and delivered AI-powered investment management productivity solutions to their customers.
Additionally, traditional forecasting models often require extensive domain knowledge and manual tuning, which can be time-consuming and complex. In this blog post, we explore a comprehensive approach to time series forecasting using the Amazon SageMaker AutoMLV2 SoftwareDevelopment Kit (SDK).
Quantization and compression can reduce model size and serving cost by reducing the precision of weights or reducing the number of parameters via pruning or distillation. Compilation can optimize the computation graph and fuse operators to reduce memory and compute requirements of a model. For more details, refer to the GitHub repo.
I think another huge component, as I kind of was mentioning earlier, is Conversational AI tends to require large pipelines of machine learning. You usually cannot do a one-shot, “here’s a model,” then it handles everything no matter what you’re reading today. And so we actually need to have a full pipeline of models.
Llama 2 stands at the forefront of AI innovation, embodying an advanced auto-regressive languagemodeldeveloped on a sophisticated transformer foundation. Its model parameters scale from an impressive 7 billion to a remarkable 70 billion. Assistant: Wow, you must be really curious about languagemodels!
The generative AI landscape has been rapidly evolving, with largelanguagemodels (LLMs) at the forefront of this transformation. These models have grown exponentially in size and complexity, with some now containing hundreds of billions of parameters and requiring hundreds of gigabytes of memory. cu124 Model Meta Llama3.1
SageMaker AI makes sure that sensitive data stays completely within each customer’s SageMaker environment and will never be shared with a third party. Their validation capabilities include automatic scoring, version comparison, and auto-calculated metrics for properties such as relevance, coverage, and grounded-in-context.
Next, you need to index this data to make it available for a Retrieval Augmented Generation (RAG) approach, where relevant passages are delivered with high accuracy to a largelanguagemodel (LLM). You also need to hire and staff a large team to build, maintain, and manage such a system. Choose Create application.
The integration of these multimodal capabilities has unlocked new possibilities for businesses and individuals, revolutionizing fields such as content creation, visual analytics, and softwaredevelopment. Vision Instruct models demonstrated impressive performance on the challenging DocVQA benchmark for visual question answering.
This process is like assembling a jigsaw puzzle to form a complete picture of the malwares capabilities and intentions, with pieces constantly changing shape. Deep Instinct, recognizing this need, has developed DIANNA (Deep Instincts Artificial Neural Network Assistant), the DSX Companion.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content