This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Largelanguagemodels (LLMs) have demonstrated promising capabilities in machine translation (MT) tasks. Depending on the use case, they are able to compete with neural translation models such as Amazon Translate. The solution proposed in this post relies on LLMs context learning capabilities and promptengineering.
The spotlight is also on DALL-E, an AI model that crafts images from textual inputs. One such model that has garnered considerable attention is OpenAI's ChatGPT , a shining exemplar in the realm of LargeLanguageModels. Our exploration into promptengineering techniques aims to improve these aspects of LLMs.
Promptengineering , the art and science of crafting prompts that elicit desired responses from LLMs, has become a crucial area of research and development. In this comprehensive technical blog, we'll delve into the latest cutting-edge techniques and strategies that are shaping the future of promptengineering.
. “weathered wooden rocking chair with intricate carvings,”) Meshy AI's technology understands both the geometry and materials of objects, creating realistic 3D models with proper depth, textures, and lighting! Describe what you want to create and the AI will generate a beautifully textured model in under a minute.
Current Landscape of AI Agents AI agents, including Auto-GPT, AgentGPT, and BabyAGI, are heralding a new era in the expansive AI universe. AI Agents vs. ChatGPT Many advanced AI agents, such as Auto-GPT and BabyAGI, utilize the GPT architecture. Their primary focus is to minimize the need for human intervention in AI task completion.
With LargeLanguageModels (LLMs) like ChatGPT, OpenAI has witnessed a surge in enterprise and user adoption, currently raking in around $80 million in monthly revenue. Last time we delved into AutoGPT and GPT-Engineering , the early mainstream open-source LLM-based AI agents designed to automate complex tasks.
LargeLanguageModels (LLMs) have become a cornerstone in artificial intelligence, powering everything from chatbots and virtual assistants to advanced text generation and translation systems. Despite their prowess, one of the most pressing challenges associated with these models is the high cost of inference.
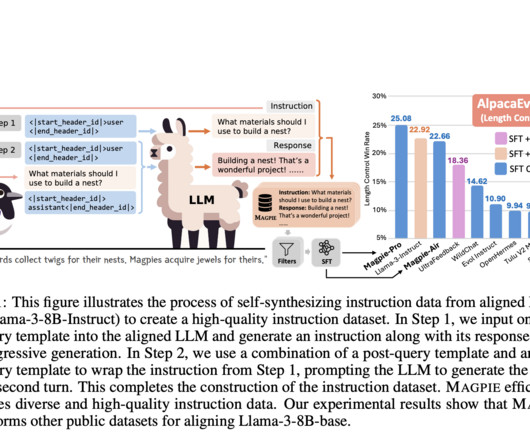
Artificial intelligence’s largelanguagemodels (LLMs) have become essential tools due to their ability to process and generate human-like text, enabling them to perform various tasks. MAGPIE leverages the auto-regressive nature of aligned LLMs to generate high-quality instruction data at scale.
Evolving Trends in PromptEngineering for LargeLanguageModels (LLMs) with Built-in Responsible AI Practices Editor’s note: Jayachandran Ramachandran and Rohit Sroch are speakers for ODSC APAC this August 22–23. Auto Eval Common Metric Eval Human Eval Custom Model Eval 3.
The performance and quality of the models also improved drastically with the number of parameters. These models span tasks like text-to-text, text-to-image, text-to-embedding, and more. You can use largelanguagemodels (LLMs), more specifically, for tasks including summarization, metadata extraction, and question answering.
Source : Image generated by author using Yarnit It is quite astonishing how LargeLanguageModels or LLMs (GPT, Claude, Gemini etc.) It’s a powerful technology that can tackle a variety of natural language tasks. In their paper, “Chain-of-Thought Prompting Elicits Reasoning in LargeLanguageModels”, Wei et.
Running largelanguagemodels (LLMs) presents significant challenges due to their hardware demands, but numerous options exist to make these powerful tools accessible. Plug in the coffee maker and press the POWER button. Press the BREW button to start brewing.
Quick Start Guide to LargeLanguageModels This book guides how to work with, integrate, and deploy LLMs to solve real-world problems. The book covers the inner workings of LLMs and provides sample codes for working with models like GPT-4, BERT, T5, LLaMA, etc.
Largelanguagemodels are great at this kind of focused, pattern-based code building. This said, it’s important to emphasize that we still need experienced and skilled engineers for 90% of our work. The auto-complete and auto-suggestions in Visual Studio Code are pretty good, too, without being annoying.
The following figure shows the Discovery Navigator generative AI auto-summary pipeline. The OCR converted medical record pages are processed through Verisk’s AI models and select pages are sent to Amazon Bedrock using AWS PrivateLink , for generating visit summaries.
They’re capable of performing a wide variety of general tasks with a high degree of accuracy based on input prompts. Largelanguagemodels (LLMs) are one class of FMs. This includes task context, data that you pass to the model, conversation and action history, instructions, and even examples.
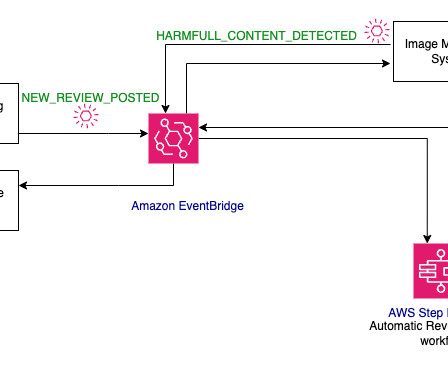
The insurance provider receives payout claims from the beneficiary’s attorney for different insurance types, such as home, auto, and life insurance. When this is complete, the document can be routed to the appropriate department or downstream process. The following diagram outlines the proposed solution architecture. append(e["Text"].upper())
Quantization and compression can reduce model size and serving cost by reducing the precision of weights or reducing the number of parameters via pruning or distillation. Compilation can optimize the computation graph and fuse operators to reduce memory and compute requirements of a model. For more details, refer to the GitHub repo.
Retrieval Augmented Generation (RAG) is a technique that enhances largelanguagemodels (LLMs) by incorporating external knowledge sources. A score of 1 means that the generated answer conveys the same meaning as the ground truth answer, whereas a score of 0 suggests that the two answers have completely different meanings.
TL;DR LLMOps involves managing the entire lifecycle of LargeLanguageModels (LLMs), including data and prompt management, model fine-tuning and evaluation, pipeline orchestration, and LLM deployment. What is LargeLanguageModel Operations (LLMOps)? What the future of LLMOps looks like.
Hallucinations can be detected by verifying the accuracy and reliability of the model’s responses. Effective mitigation strategies involve enhancing data quality, alignment, information retrieval methods, and promptengineering. In extreme cases, certain tokens can completely break an LLM. In 2022, when GPT-3.5
W&B (Weights & Biases) W&B is a machine learning platform for your data science teams to track experiments, version and iterate on datasets, evaluate model performance, reproduce models, visualize results, spot regressions, and share findings with colleagues. Is it fast and reliable enough for your workflow?
Today we’re going to be talking essentially about how responsible generative-AI-model adoption can happen at the enterprise level, and what are some of the promises and compromises we face. The foundation of largelanguagemodels started quite some time ago. What are the promises? Billions of parameters.
Today we’re going to be talking essentially about how responsible generative-AI-model adoption can happen at the enterprise level, and what are some of the promises and compromises we face. The foundation of largelanguagemodels started quite some time ago. What are the promises? Billions of parameters.
They focussed largely on the challenges and opportunities in leveraging largelanguagemodels and foundation models , as well as data-centric AI development approaches. Across thirteen sessions, the speakers commented on the current and future state of artificial intelligence and machine learning.
They focussed largely on the challenges and opportunities in leveraging largelanguagemodels and foundation models , as well as data-centric AI development approaches. Across thirteen sessions, the speakers on the current and future state of artificial intelligence and machine learning. Learn more, live!
Then we show how you can enhance the in-notebook SQL experience using Text-to-SQL capabilities provided by advanced largelanguagemodels (LLMs) to write complex SQL queries using natural language text as input. Complete the following steps: On the Secrets Manager console, choose Store a new secret.
The company’s AI can learn from internal documents, email, chat and even old support tickets to automatically resolve auto-route tickets correctly, and quickly surface the most relevant institutional knowledge. But for example, GPT two was launched, I believe in 2018, 2019, and open source, and there were other models like T5.
LargeLanguageModels (LLMs) capable of complex reasoning tasks have shown promise in specialized domains like programming and creative writing. Developed by Meta with its partnership with Microsoft, this open-source largelanguagemodel aims to redefine the realms of generative AI and natural language understanding.
Visual language processing (VLP) is at the forefront of generative AI, driving advancements in multimodal learning that encompasses language intelligence, vision understanding, and processing. Additionally, you benefit from advanced features like auto scaling of inference endpoints, enhanced security, and built-in model monitoring.
In this article, we will consider the different implementation aspects of Text2SQL and focus on modern approaches with the use of LargeLanguageModels (LLMs), which achieve the best performance as of now (cf. [2]; 3] provides a more complete survey of Text2SQL data augmentation techniques.
Two open-source libraries, Ragas (a library for RAG evaluation) and Auto-Instruct, used Amazon Bedrock to power a framework that evaluates and improves upon RAG. Generating improved instructions for each question-and-answer pair using an automatic promptengineering technique based on the Auto-Instruct Repository.
Not only are largelanguagemodels (LLMs) capable of answering a users question based on the transcript of the file, they are also capable of identifying the timestamp (or timestamps) of the transcript during which the answer was discussed. The process takes approximately 20 minutes to complete.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content