This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
LargeLanguageModels (LLMs) are currently one of the most discussed topics in mainstream AI. These models are AI algorithms that utilize deep learning techniques and vast amounts of training data to understand, summarize, predict, and generate a wide range of content, including text, audio, images, videos, and more.
Largelanguagemodels (LLMs) have demonstrated promising capabilities in machine translation (MT) tasks. Depending on the use case, they are able to compete with neural translation models such as Amazon Translate. When the indexing is complete, select the created index from the index dropdown.
Evaluating LargeLanguageModels (LLMs) is a challenging problem in languagemodeling, as real-world problems are complex and variable. A recent LinkedIn post has emphasized a number of important measures that are essential to comprehend how well new models function, which are as follows.
TL;DR Multimodal LargeLanguageModels (MLLMs) process data from different modalities like text, audio, image, and video. Compared to text-only models, MLLMs achieve richer contextual understanding and can integrate information across modalities, unlocking new areas of application.
However, among all the modern-day AI innovations, one breakthrough has the potential to make the most impact: largelanguagemodels (LLMs). Largelanguagemodels can be an intimidating topic to explore, especially if you don't have the right foundational understanding. What Is a LargeLanguageModel?
Many applications have used largelanguagemodels (LLMs). They train a Llama1 7B model using the HumanEval coding dataset and feed it its initial prompt. The model defines and autocompletes the function’s body when the prompt comprises a docstring and a Python function header.
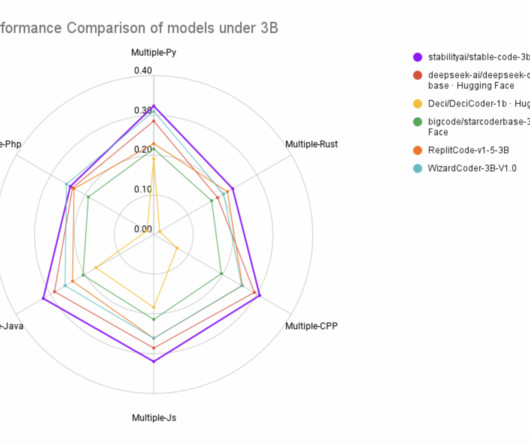
Stable AI has recently released a new state-of-the-art model, Stable-Code-3B , designed for code completion in various programming languages with multiple additional capabilities. The model is a follow-up on the Stable Code Alpha 3B. It is trained on 1.3 It is trained on 1.3
This enhancement builds upon the existing auto scaling capabilities in SageMaker, offering more granular control over resource allocation. Compressed model files may save storage space, but they require additional time to uncompress and files can’t be downloaded in parallel, which can slow down the scale-up process.
As the demand for largelanguagemodels (LLMs) continues to rise, ensuring fast, efficient, and scalable inference has become more crucial than ever. Kernel Auto-tuning : TensorRT automatically selects the best kernel for each operation, optimizing inference for a given GPU. build/tensorrt_llm*.whl
70B marks an exciting advancement in largelanguagemodel (LLM) development, offering comparable performance to larger Llama versions with fewer computational resources. 70B using the SageMaker JumpStart UI, complete the following steps: In SageMaker Unified Studio, on the Build menu, choose JumpStart models.
. “weathered wooden rocking chair with intricate carvings,”) Meshy AI's technology understands both the geometry and materials of objects, creating realistic 3D models with proper depth, textures, and lighting! Describe what you want to create and the AI will generate a beautifully textured model in under a minute.
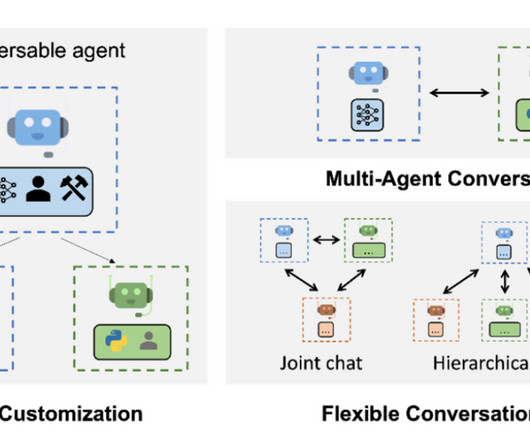
Current Landscape of AI Agents AI agents, including Auto-GPT, AgentGPT, and BabyAGI, are heralding a new era in the expansive AI universe. AI Agents vs. ChatGPT Many advanced AI agents, such as Auto-GPT and BabyAGI, utilize the GPT architecture. Their primary focus is to minimize the need for human intervention in AI task completion.
LargeLanguageModels (LLMs) capable of complex reasoning tasks have shown promise in specialized domains like programming and creative writing. Developed by Meta with its partnership with Microsoft, this open-source largelanguagemodel aims to redefine the realms of generative AI and natural language understanding.
The KL730 auto-grade NPU chip packs an integrated Image Signal Processor (ISP) and promises to bring secure and energy-efficient AI capabilities to an extensive range of applications, spanning from enterprise-edge servers to smart home appliances and advanced driving assistance systems. The KL730 is a game-changer for edge AI.
Today, generative AI on PC is getting up to 4x faster via TensorRT-LLM for Windows, an open-source library that accelerates inference performance for the latest AI largelanguagemodels, like Llama 2 and Code Llama. This follows the announcement of TensorRT-LLM for data centers last month.
These triggers are how you give your AI Agents tasks to complete. While the simplest way to give your AI agent a task to complete is by sending it a message, you'll often want to give your agent work from external systems. Since I want to create an AI agent that handles leads collected by Hubspot, I would connect my Hubspot.
Anyspheres Cursor tool, for example, helped advance the genre from simply completing lines or sections of code to building whole software functions based on the plain language input of a human developer. Or the developer can explain a new feature or function in plain language and the AI will code a prototype of it.
With the rise of largelanguagemodels (LLMs) like Meta Llama 3.1, there is an increasing need for scalable, reliable, and cost-effective solutions to deploy and serve these models. 8B model With the setup complete, you can now deploy the model using a Kubernetes deployment.
Using Automatic Speech Recognition (also known as speech to text AI , speech AI, or ASR), companies can efficiently transcribe speech to text at scale, completing what used to be a laborious process in a fraction of the time. It would take weeks to filter and categorize all of the information to identify common issues or patterns.
Scalable infrastructure – Bedrock Marketplace offers configurable scalability through managed endpoints, allowing organizations to select their desired number of instances, choose appropriate instance types, define custom auto scaling policies that dynamically adjust to workload demands, and optimize costs while maintaining performance.
Unlocking Unstructured Data with LLMs Leveraging largelanguagemodels (LLMs) for unstructured data extraction is a compelling solution with distinct advantages that address critical challenges. Context-Aware Data Extraction LLMs possess strong contextual understanding, honed through extensive training on large datasets.
With LargeLanguageModels (LLMs) like ChatGPT, OpenAI has witnessed a surge in enterprise and user adoption, currently raking in around $80 million in monthly revenue. Agile Development SOPs act as a meta-function here, coordinating agents to auto-generate code based on defined inputs.
It can also modernize legacy code and translate code from one programming language to another. Auto-generated code suggestions can increase developers’ productivity and optimize their workflow by providing straightforward answers, handling routine coding tasks, reducing the need to context switch and conserving mental energy.
Researchers want to create a system that eventually learns to bypass humans completely by completing the research cycle without human involvement. Fudan University and the Shanghai Artificial Intelligence Laboratory have developed DOLPHIN, a closed-loop auto-research framework covering the entire scientific research process.
Although blue/green deployment has been a reliable strategy for zero-downtime updates, its limitations become glaring when deploying large-scale largelanguagemodels (LLMs) or high-throughput models on premium GPU instances. Now another two free GPU slots are available.
Since Meta released the latest open-source LargeLanguageModel (LLM), Llama3, various development tools and frameworks have been actively integrating Llama3. Copilot leverages natural language processing and machine learning to generate high-quality code snippets and context information.
By harnessing the power of largelanguagemodels and machine learning algorithms, these AI systems can not only generate code but also identify and fix bugs, streamlining the entire development lifecycle. Described as an AI-powered programming companion, it presents auto-complete suggestions during code development.
LargeLanguageModels (LLMs) have become a cornerstone in artificial intelligence, powering everything from chatbots and virtual assistants to advanced text generation and translation systems. Despite their prowess, one of the most pressing challenges associated with these models is the high cost of inference.
This field primarily enhances machine understanding and generation of human language, serving as a backbone for various applications such as text summarization, translation, and auto-completion systems. Efficient languagemodeling faces significant hurdles, particularly with largemodels.
Scott Stevenson, is Co-Founder & CEO of Spellbook , a tool to automate legal work that is built on OpenAI's GPT-4 and other largelanguagemodels (LLMs). Spellbook is further tuning the model using proprietary legal datasets. How does Spellbook suggest language for legal contracts?
In many generative AI applications, a largelanguagemodel (LLM) like Amazon Nova is used to respond to a user query based on the models own knowledge or context that it is provided. If the model selects a tool, there will be a tool block and text block.
A McKinsey study claims that software developers can complete coding tasks up to twice as fast with generative AI. Repetitive, routine work like typing out standard functions can be expedited with auto-complete features.
Their DeepSeek-R1 models represent a family of largelanguagemodels (LLMs) designed to handle a wide range of tasks, from code generation to general reasoning, while maintaining competitive performance and efficiency. An S3 bucket prepared to store the custom model. Choose Import model.
Model Context Protocol (MCP) is a standardized open protocol that enables seamless interaction between largelanguagemodels (LLMs), data sources, and tools. Prerequisites To complete the solution, you need to have the following prerequisites in place: uv package manager Install Python using uv python install 3.13
LargeLanguageModels (LLMs) have successfully catered their way into the challenging areas of Artificial Intelligence. LargeLanguageModels are often augmented with reasoning skills and the ability to use different tools.
We fine-tuned a largelanguagemodel to proactively suggest relevant visuals in open-vocabulary conversations using a dataset we curated for this purpose. prompt": " →", "completion": " of " from " ; of " from " ; ?"} Examples of visual intent predictions by our model. We used 1276 (80%) examples from the VC1.5K
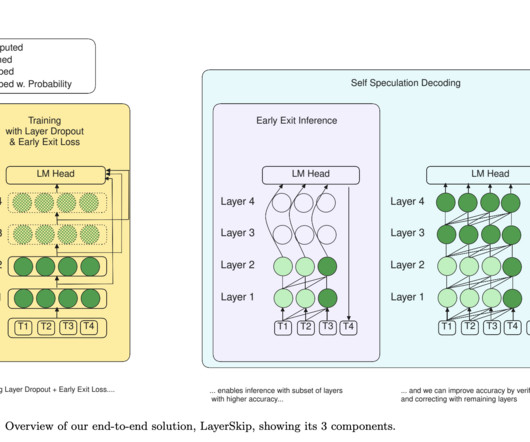
This new approach allows for the drafting of multiple tokens simultaneously using a single model, combining the benefits of auto-regressive generation and speculative sampling. The PaSS method was evaluated on text and code completion tasks, exhibiting promising performance without compromising model quality.
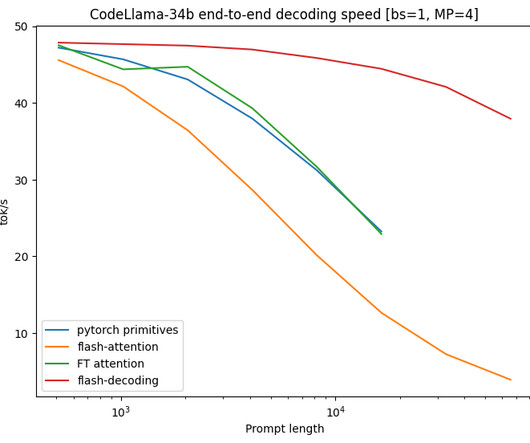
However, these models pose challenges, including computational complexity and GPU memory usage. Despite great success in various applications, there is an urgent need to find a cost-effective way to serve these models. Still, an increase in model size and generation length leads to an increase in memory usage of the KV cache.
That requires first preparing and encoding data to load into a vector database, and then retrieving data via search to add to any prompt as context as input to a LargeLanguageModel (LLM) that hasnt been trained using this data. Auto generation: Integration and GenAI are both hard.
Languagemodels are statistical methods predicting the succession of tokens in sequences, using natural text. Largelanguagemodels (LLMs) are neural network-based languagemodels with hundreds of millions ( BERT ) to over a trillion parameters ( MiCS ), and whose size makes single-GPU training impractical.
Largelanguagemodels (LLMs) such as ChatGPT and Llama have garnered substantial attention due to their exceptional natural language processing capabilities, enabling various applications ranging from text generation to code completion. Check out the Reference Page and Project Page.
The performance and quality of the models also improved drastically with the number of parameters. These models span tasks like text-to-text, text-to-image, text-to-embedding, and more. You can use largelanguagemodels (LLMs), more specifically, for tasks including summarization, metadata extraction, and question answering.
Conversational intelligence features and LargeLanguageModel (LLM) post-processing rely on knowing who said what to extract as much useful information as possible from this raw data. Try it today Get a free API key to try out our improved Speaker Diarization model Get an API key
Running largelanguagemodels (LLMs) presents significant challenges due to their hardware demands, but numerous options exist to make these powerful tools accessible. Plug in the coffee maker and press the POWER button. Press the BREW button to start brewing.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























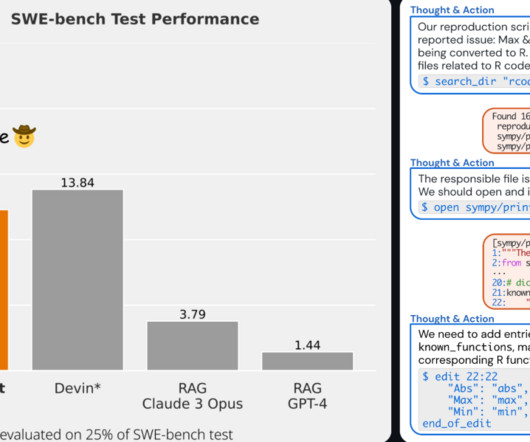






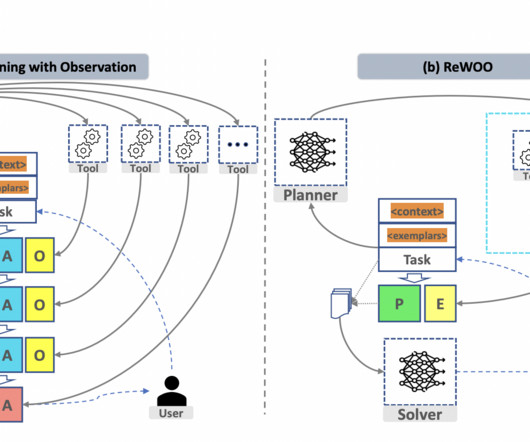


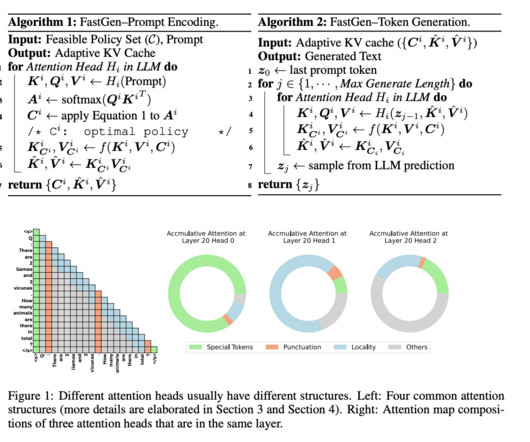










Let's personalize your content