This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This helps teams save time on training or looking up information, allowing them to focus on core operations. The system automatically tracks stock movements and allocates materials to orders (using a smart auto-booking engine) to maintain optimal inventory levels.
Amazon SageMaker provides capabilities to remove the undifferentiated heavy lifting of building and deploying ML models. SageMaker simplifies the process of managing dependencies, container images, auto scaling, and monitoring. They often work with DevOps engineers to operate those pipelines.
With the SageMaker HyperPod auto-resume functionality, the service can dynamically swap out unhealthy nodes for spare ones to ensure the seamless continuation of the workload. Also included are SageMaker HyperPod cluster software packages, which support features such as cluster health check and auto-resume.
Optionally, if Account A and Account B are part of the same AWS Organizations, and the resource sharing is enabled within AWS Organizations, then the resource sharing invitation are auto accepted without any manual intervention. Following are the steps completed by using APIs to create and share a model package group across accounts.
In a single visual interface, you can complete each step of a data preparation workflow: data selection, cleansing, exploration, visualization, and processing. Complete the following steps: Choose Prepare and analyze data. Complete the following steps: Choose Run Data quality and insights report. Choose Create.
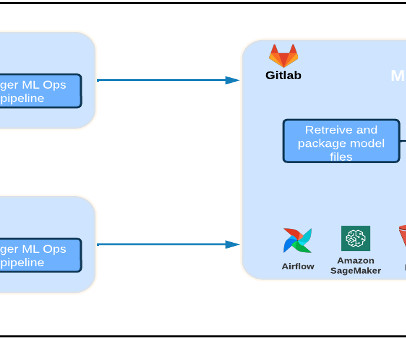
We orchestrate our ML training and deployment pipelines using Amazon Managed Workflows for Apache Airflow (Amazon MWAA), which enables us to focus more on programmatically authoring workflows and pipelines without having to worry about auto scaling or infrastructure maintenance.
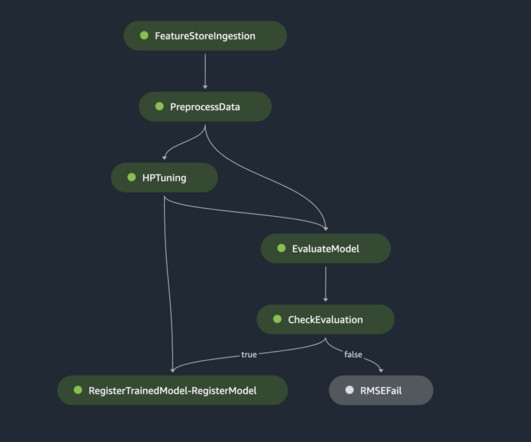
In addition to evaluating the accuracy of your models, processing jobs help you to make informed decisions about the tradeoffs between a model’s accuracy and its carbon footprint. Next, you can use governance to share information about the environmental impact of your model.
This post is co-written with Jad Chamoun, Director of Engineering at Forethought Technologies, Inc. and Salina Wu, Senior MLEngineer at Forethought Technologies, Inc. SupportGPT leverages state-of-the-art Information Retrieval (IR) systems and large language models (LLMs) to power over 30 million customer interactions annually.
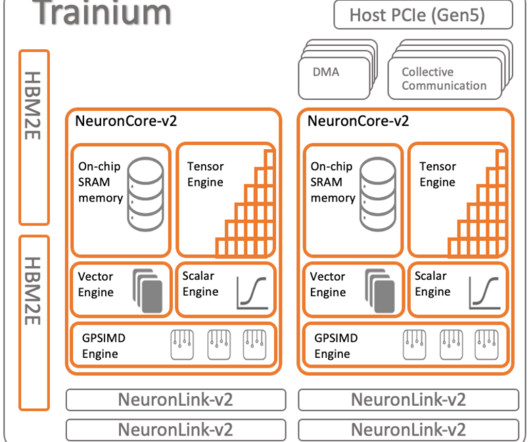
Regular CPU systems are completely memory bound for these calculations, and performance is limited by the time required to move the data into the CPU. In Trainium, the GP-SIMD engines are tightly coupled with the on-chip caches using a high bandwidth streaming interface, which can sustain 2 TB/sec of memory bandwidth.
MLengineers must handle parallelization, scheduling, faults, and retries manually, requiring complex infrastructure code. In this post, we discuss the benefits of using Ray and Amazon SageMaker for distributed ML, and provide a step-by-step guide on how to use these frameworks to build and deploy a scalable ML workflow.
Can you see the complete model lineage with data/models/experiments used downstream? Can you debug system information? Some of its features include a data labeling workforce, annotation workflows, active learning and auto-labeling, scalability and infrastructure, and so on. Is it fast and reliable enough for your workflow?
Comet Comet is a machine learning platform built to help data scientists and MLengineers track, compare, and optimize machine learning experiments. In the left panel, we can see other information, such as our hyperparameters, the code we use, and much more. This is how we can track all our experiments with the comet_ml library.
These types of data are historical raw data from an ML perspective. For example, each log is written in the format of timestamp, user ID, and event information. The ETL pipeline, MLOps pipeline, and ML inference should be rebuilt in a different AWS account. MLengineers no longer need to manage this training metadata separately.
DataRobot Notebooks is a fully hosted and managed notebooks platform with auto-scaling compute capabilities so you can focus more on the data science and less on low-level infrastructure management. Auto-scale compute. In the DataRobot left sidebar, there is a table of contents auto-generated from the hierarchy of Markdown cells.
I believe the team will look something like this: Software delivery reliability: DevOps engineers and SREs ( DevOps vs SRE here ) ML-specific software: software engineers and data scientists Non-ML-specific software: software engineers Product: product people and subject matter experts Wait, where is the MLOps engineer?
You need to have a structured definition around what you’re trying to do so your data annotators can label information for you. And even on the operation side of things, is there a separate operations team, and then you have your research or mlengineers doing these pipelines and stuff? Now, we’re not perfect.
People will auto-scale up to 10 GPUs to handle the traffic. Does it mean that the production code has to be rewritten by, for example, MLengineers manually to be optimized for GPU with each update? Each of them may be with separate resource constraints, auto-scaling policies, and such. That’ll be easier short term.
is an auto-regressive language model that uses an optimized transformer architecture. For more information about version updates, refer to Shut down and Update Studio Classic Apps. 405B-Instruct You can use Llama models for text completion for any piece of text. The Llama 3.1 At its core, Llama 3.1 You can find the Llama 3.1
Customers want to search through all of the data and applications across their organization, and they want to see the provenance information for all of the documents retrieved. The application needs to search through the catalog and show the metadata information related to all of the data assets that are relevant to the search context.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























Let's personalize your content