This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
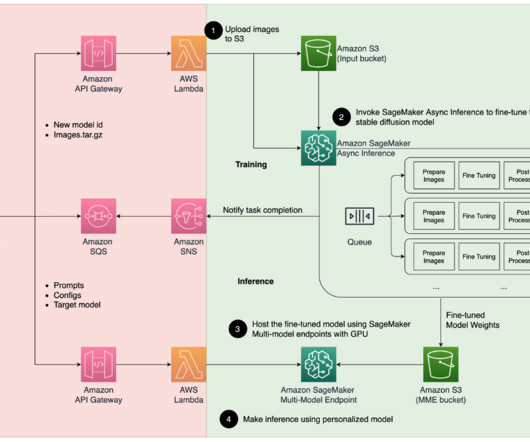
It also provides a built-in queuing mechanism for queuing up requests, and a task completion notification mechanism via Amazon SNS, in addition to other native features of SageMaker hosting such as auto scaling. To host the asynchronous endpoint, we must complete several steps. amazonaws.com/djl-inference:0.21.0-deepspeed0.8.3-cu117"
With kernel auto-tuning, the engine selects the best algorithm for the target GPU, maximizing hardware utilization. Additionally, TensorRT employs CUDA streams to enable parallel processing of models, further improving GPU utilization and performance. Note that the cell takes around 30 minutes to complete. !docker
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








Let's personalize your content