This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
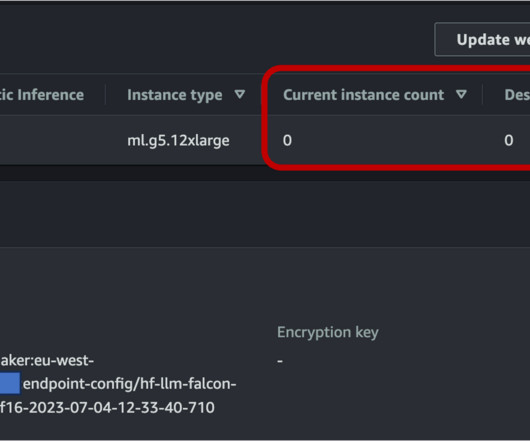
This enhancement builds upon the existing auto scaling capabilities in SageMaker, offering more granular control over resource allocation. You can now configure your scaling policies to include scaling to zero, allowing for more precise management of your AI inference infrastructure.
With advancements in deep learning, natural language processing (NLP), and AI, we are in a time period where AI agents could form a significant portion of the global workforce. These AI agents, transcending chatbots and voice assistants, are shaping a new paradigm for both industries and our daily lives.
The user enters a text prompt describing what the code should do, and the generativeAI code development tool automatically creates the code. How does generativeAI code generation work? Training code generally comes from publicly available code produced by open-source projects.
Today, Amazon Web Services (AWS) announced the general availability of Amazon Bedrock Knowledge Bases GraphRAG (GraphRAG), a capability in Amazon Bedrock Knowledge Bases that enhances Retrieval-Augmented Generation (RAG) with graph data in Amazon Neptune Analytics.
This advancement has spurred the commercial use of generativeAI in natural language processing (NLP) and computer vision, enabling automated and intelligent data extraction. Named Entity Recognition ( NER) Named entity recognition (NER), an NLP technique, identifies and categorizes key information in text.
Developed by Meta with its partnership with Microsoft, this open-source large language model aims to redefine the realms of generativeAI and natural language understanding. One that stresses an open-source approach as the backbone of AI development, particularly in the generativeAI space.
Businesses ranging from e-commerce to SaaS have leveraged Algomo to scale support without proportional headcount, thanks to its combination of AI efficiency and human fallback. Top Features: Multilingual AI Chatbots Converse with customers in over 100 languages, using NLP to understand and respond appropriately. Visit Dante 4.
From self-driving cars to language models that can engage in human-like conversations, AI is rapidly transforming various industries, and software development is no exception. Described as an AI-powered programming companion, it presents auto-complete suggestions during code development.
Agile Development SOPs act as a meta-function here, coordinating agents to auto-generate code based on defined inputs. With MetaGPT, you're not just automating code generation, you're automating intelligent project planning, thus providing a competitive edge in rapid application development.
By surrounding unparalleled human expertise with proven technology, data and AI tools, Octus unlocks powerful truths that fuel decisive action across financial markets. Visit octus.com to learn how we deliver rigorously verified intelligence at speed and create a complete picture for professionals across the entire credit lifecycle.
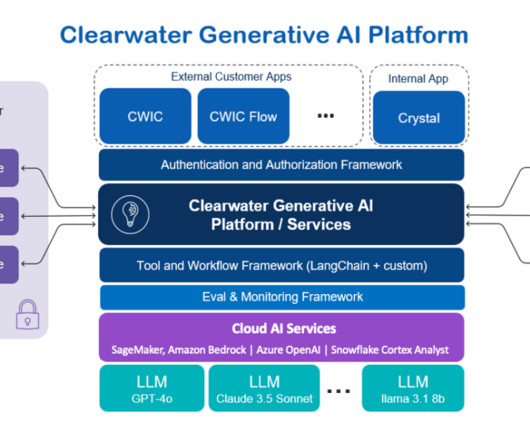
GenerativeAI , AI, and machine learning (ML) are playing a vital role for capital markets firms to speed up revenue generation, deliver new products, mitigate risk, and innovate on behalf of their customers. Crystal Clearwaters advanced AI assistant with expanded capabilities that empower internal teams operations.
For a complete list of runtime configurations, please refer to text-generation-launcher arguments. DeepSeek Deployment Patterns with TGI on Amazon SageMaker AI Amazon SageMaker AI offers a simple and streamlined approach to deploy DeepSeek-R1 models with just a few lines of code. 24xlarge , followed by ml.g6e.48xlarge
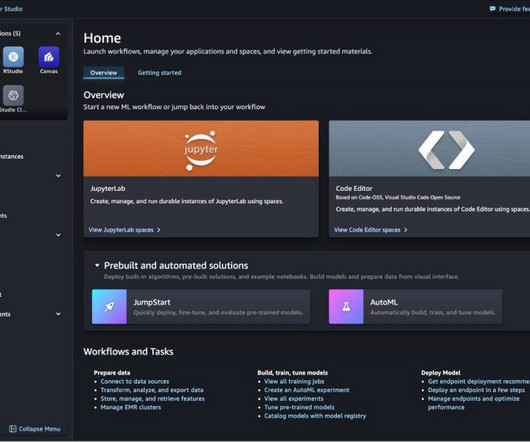
Additionally, we cover the seamless integration of generativeAI tools like Amazon CodeWhisperer and Jupyter AI within SageMaker Studio JupyterLab Spaces, illustrating how they empower developers to use AI for coding assistance and innovative problem-solving. Choose Create JupyterLab space. Choose Create space.
Retrieval Augmented Generation (RAG) allows you to provide a large language model (LLM) with access to data from external knowledge sources such as repositories, databases, and APIs without the need to fine-tune it. Use the deployed models in your question answering generativeAI applications. Deploy the BAAI/bge-small-en-v1.5
If you prefer to generate post call recording summaries with Amazon Bedrock rather than Amazon SageMaker, checkout this Bedrock sample solution. They are designed for real-time, interactive, and low-latency workloads and provide auto scaling to manage load fluctuations. The format of the recordings must be either.mp4,mp3, or.wav.
Using machine learning (ML) and natural language processing (NLP) to automate product description generation has the potential to save manual effort and transform the way ecommerce platforms operate. With the advancement of GenerativeAI , we can use vision-language models (VLMs) to predict product attributes directly from images.
The added benefit of asynchronous inference is the cost savings by auto scaling the instance count to zero when there are no requests to process. SageMaker features and capabilities help developers and data scientists get started with natural language processing (NLP) on AWS with ease.
The world of artificial intelligence (AI) and machine learning (ML) has been witnessing a paradigm shift with the rise of generativeAI models that can create human-like text, images, code, and audio. Compared to classical ML models, generativeAI models are significantly bigger and more complex.
model = AutoModelForCausalLM.from_pretrained(model_id, trust_remote_code=True, quantization_config=bnb_config, device_map="auto") With Hugging Face’s PEFT library, you can freeze most of the original model weights and replace or extend model layers by training an additional, much smaller, set of parameters.
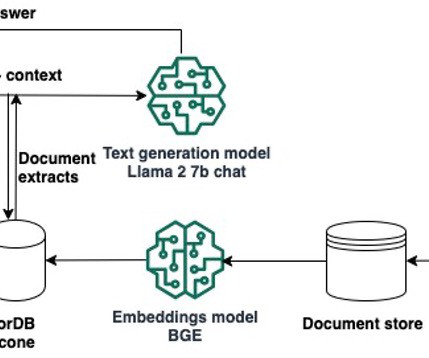
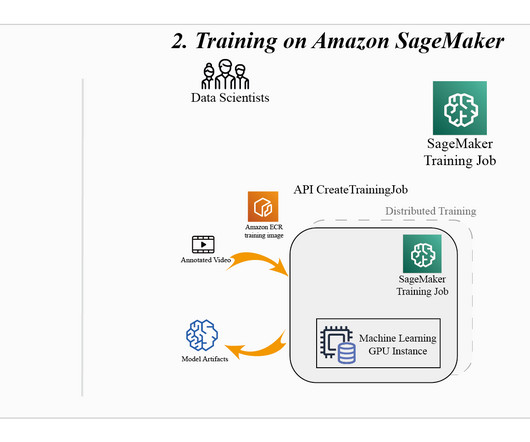
Forethought is a leading generativeAI suite for customer service. Once these gaps are identified, SupportGPT can automatically generate articles and other content to fill these knowledge voids, ensuring the support knowledge base remains customer-centric and up to date. The following diagram illustrates our legacy architecture.
Zero and Few-Shot Learning: Optimizing with Examples Generative Pretrained Transformers (GPT-3) marked an important turning point in the development of GenerativeAI models, as it introduced the concept of ‘ few-shot learning.' In zero-shot learning, no examples of task completion are provided in the model.
We’re at an exciting inflection point in the widespread adoption of machine learning (ML), and we believe most customer experiences and applications will be reinvented with generativeAI. GenerativeAI can create new content and ideas, including conversations, stories, images, videos, and music.
What is the optimal framework and configuration for hosting large language models (LLMs) for text-generatinggenerativeAI applications? This condition can be a maximum length for the generated text, a specific token that signals the end of the text, or any other criteria set by the user or the application.
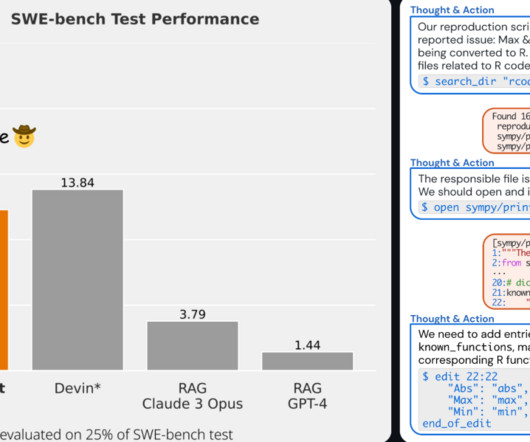
The success of generativeAI applications across a wide range of industries has attracted the attention and interest of companies worldwide who are looking to reproduce and surpass the achievements of competitors or solve new and exciting use cases. as the engines that power the generativeAI innovation.
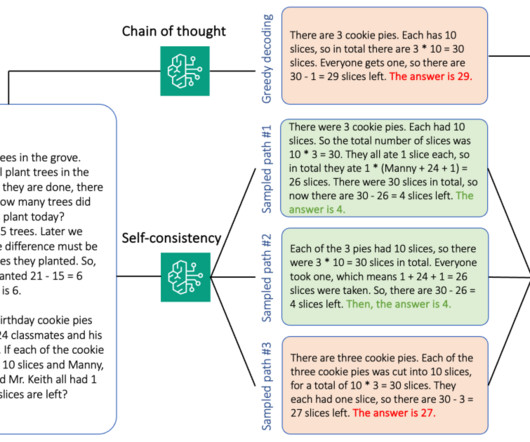
Generative language models have proven remarkably skillful at solving logical and analytical natural language processing (NLP) tasks. To additionally boost accuracy on tasks that involve reasoning, a self-consistency prompting approach has been suggested, which replaces greedy with stochastic decoding during language generation.
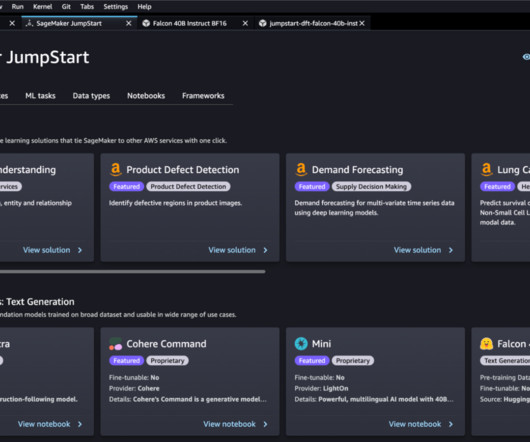
In this post, we showcase how to build an end-to-end generativeAI application for enterprise search with Retrieval Augmented Generation (RAG) by using Haystack pipelines and the Falcon-40b-instruct model from Amazon SageMaker JumpStart and Amazon OpenSearch Service.
Their impressive generative abilities have led to widespread adoption across various sectors and use cases, including content generation, sentiment analysis, chatbot development, and virtual assistant technology. This results in faster restarts and workload completion. Llama2 by Meta is an example of an LLM offered by AWS.
Customers can create the custom metadata using Amazon Comprehend , a natural-language processing (NLP) service managed by AWS to extract insights about the content of documents, and ingest it into Amazon Kendra along with their data into the index. For example, metadata can be used for filtering and searching. append(e["Text"].upper())
These models aren't just large in terms of size—they're also massive in their capacity to understand human prompts and generate vast amounts of original text. Original natural language processing (NLP) models were limited in their understanding of language. Read Introduction to Large Language Models for GenerativeAI.
These include computer vision (CV), natural language processing (NLP), and generativeAI models. Taking NLP models as an example, many of them exceed billions of parameters, which requires GPUs to satisfy low latency and high throughput requirements. 2xlarge, ml.g5.2xlarge, and ml.p3.2xlarge.
In recent years, we have seen a big increase in the size of large language models (LLMs) used to solve natural language processing (NLP) tasks such as question answering and text summarization. Next, we perform auto-regressive token generation where the output tokens are generated sequentially. compared to 76.4).
Salesforce Einstein is a set of AI technologies that integrate with Salesforce’s Customer Success Platform to help businesses improve productivity and client engagement. These models are designed to provide advanced NLP capabilities for various business applications.
Llama 2 is an auto-regressive generative text language model that uses an optimized transformer architecture. As a publicly available model, Llama 2 is designed for many NLP tasks such as text classification, sentiment analysis, language translation, language modeling, text generation, and dialogue systems.
Specify the new content to be generated using one of the following options: To add or replace an element, set the text parameter to a description of the new content. To remove an element, omit the text parameter completely. Use the BedrockRuntime client to invoke the Titan Image Generator model. Parse and decode the response.
It’s a next generation model in the Falcon family—a more efficient and accessible large language model (LLM) that is trained on a 5.5 It’s built on causal decoder-only architecture, making it powerful for auto-regressive tasks. After deployment is complete, you will see that an endpoint is created.
AI content creation tools can help you here, especially when saving time in social media post creation. These tools leverage artificial intelligence (AI) and natural language processing (NLP) technologies to assist in creating, optimizing, and managing content for various social media platforms. 🤔 Why go for it?
Limited options for auto-QA Many companies use automated QA (auto QA) services to monitor customer interactions. However, this is a relatively small market with limited solutions, and most auto-QA tools fail to deliver actionable results. Level AI offers QA-GPT , a powerful QA auditor you can tailor to your exact business.
Visual language processing (VLP) is at the forefront of generativeAI, driving advancements in multimodal learning that encompasses language intelligence, vision understanding, and processing. Solution overview The proposed VLP solution integrates a suite of state-of-the-art generativeAI modules to yield accurate multimodal outputs.
To learn more about SageMaker Studio JupyterLab Spaces, refer to Boost productivity on Amazon SageMaker Studio: Introducing JupyterLab Spaces and generativeAI tools. To store information in Secrets Manager, complete the following steps: On the Secrets Manager console, choose Store a new secret.
Now you can also fine-tune 7 billion, 13 billion, and 70 billion parameters Llama 2 text generation models on SageMaker JumpStart using the Amazon SageMaker Studio UI with a few clicks or using the SageMaker Python SDK. In this post, we walk through how to fine-tune Llama 2 pre-trained text generation models via SageMaker JumpStart.
An intelligent document processing (IDP) project usually combines optical character recognition (OCR) and natural language processing (NLP) to read and understand a document and extract specific terms or words. If you’re not actively using the endpoint for an extended period, you should set up an auto scaling policy to reduce your costs.
Prerequisites Before getting started, complete the following prerequisites: Create an AWS account or use an existing AWS account. Set up your resources After you complete all the prerequisites, you’re ready to deploy the solution. About the Authors Gordon Wang , is a Senior AI/ML Specialist TAM at AWS. medium instance type.
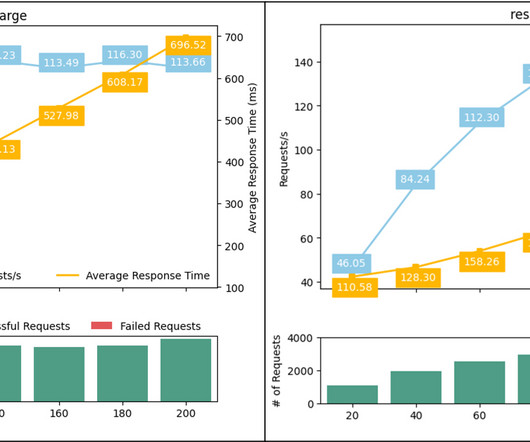
Furthermore, the CPUUtilization metric shows a classic pattern of periodic high and low CPU demand, which makes this endpoint a good candidate for auto scaling. SageMaker batch transform Batch inference, or offline inference , is the process of generating predictions on a batch of observations.
The built APP provides an easy web interface to access the large language models with several built-in application utilities for direct use, significantly lowering the barrier for the practitioners to use the LLM’s Natural Language Processing (NLP) capabilities in an amateur way focusing on their specific use cases.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content