This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
However, as the reach of live streams expands globally, language barriers and accessibility challenges have emerged, limiting the ability of viewers to fully comprehend and participate in these immersive experiences. For the complete list of model IDs, see Amazon Bedrock model IDs.
Today, Amazon Web Services (AWS) announced the general availability of Amazon Bedrock Knowledge Bases GraphRAG (GraphRAG), a capability in Amazon Bedrock Knowledge Bases that enhances Retrieval-Augmented Generation (RAG) with graph data in Amazon Neptune Analytics.
Open foundation models (FMs) have become a cornerstone of generativeAI innovation, enabling organizations to build and customize AI applications while maintaining control over their costs and deployment strategies. You can access your imported custom models on-demand and without the need to manage underlying infrastructure.
The user enters a text prompt describing what the code should do, and the generativeAI code development tool automatically creates the code. It can also modernize legacy code and translate code from one programming language to another. How does generativeAI code generation work?
To build a generativeAI -based conversational application integrated with relevant data sources, an enterprise needs to invest time, money, and people. Amazon Q Business offers multiple pre-built data source connectors that can connect to your data sources and help you create your generativeAI solution with minimal configuration.
With advancements in deep learning, naturallanguageprocessing (NLP), and AI, we are in a time period where AI agents could form a significant portion of the global workforce. These AI agents, transcending chatbots and voice assistants, are shaping a new paradigm for both industries and our daily lives.
This advancement has spurred the commercial use of generativeAI in naturallanguageprocessing (NLP) and computer vision, enabling automated and intelligent data extraction. Typically, the generativeAI model provides a prompt describing the desired data, and the ensuing response contains the extracted data.
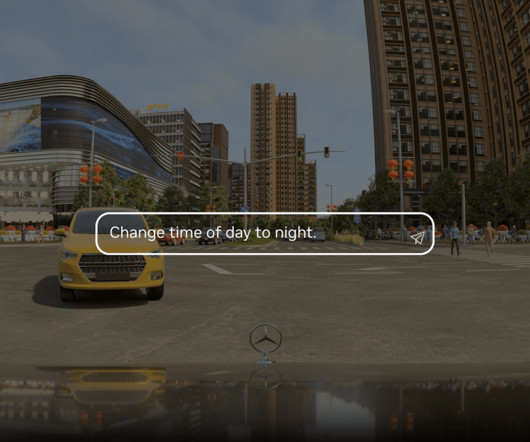
NVIDIA GTC , running this week at the San Jose Convention Center, will spotlight the groundbreaking work NVIDIA and its partners are doing to bring the transformative power of generativeAI , large language models and visual language models to the mobility sector.
Foundational models (FMs) and generativeAI are transforming how financial service institutions (FSIs) operate their core business functions. FMs are probabilistic in nature and produce a range of outcomes. This is where the combination of generativeAI and Automated Reasoning come into play.
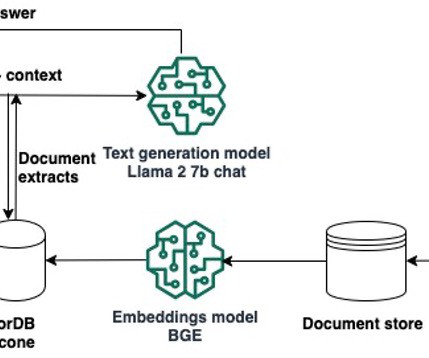
Retrieval Augmented Generation (RAG) allows you to provide a large language model (LLM) with access to data from external knowledge sources such as repositories, databases, and APIs without the need to fine-tune it. Use the deployed models in your question answering generativeAI applications.
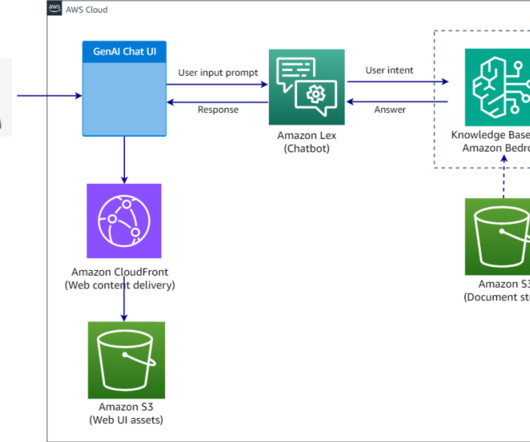
It features naturallanguage understanding capabilities to recognize more accurate identification of user intent and fulfills the user intent faster. Amazon Bedrock simplifies the process of developing and scaling generativeAI applications powered by large language models (LLMs) and other foundation models (FMs).
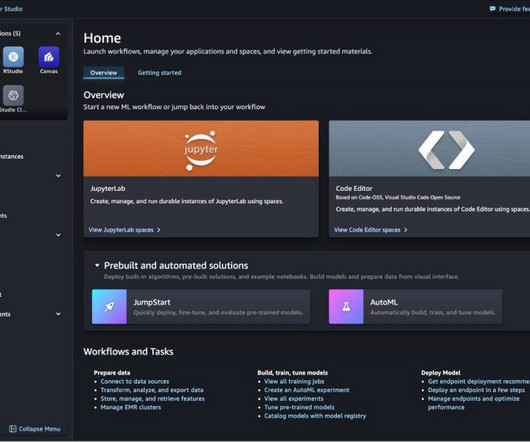
Additionally, we cover the seamless integration of generativeAI tools like Amazon CodeWhisperer and Jupyter AI within SageMaker Studio JupyterLab Spaces, illustrating how they empower developers to use AI for coding assistance and innovative problem-solving. Choose Create JupyterLab space. Choose Create space.
By surrounding unparalleled human expertise with proven technology, data and AI tools, Octus unlocks powerful truths that fuel decisive action across financial markets. Visit octus.com to learn how we deliver rigorously verified intelligence at speed and create a complete picture for professionals across the entire credit lifecycle.
Using machine learning (ML) and naturallanguageprocessing (NLP) to automate product description generation has the potential to save manual effort and transform the way ecommerce platforms operate. jpg and the complete metadata from styles/38642.json. lora_alpha=32, # the alpha parameter for Lora scaling.
To address this challenge, the contact center team at DoorDash wanted to harness the power of generativeAI to deploy a solution quickly, and at scale, while maintaining their high standards for issue resolution and customer satisfaction. The stack will take about a minute or two to deploy.
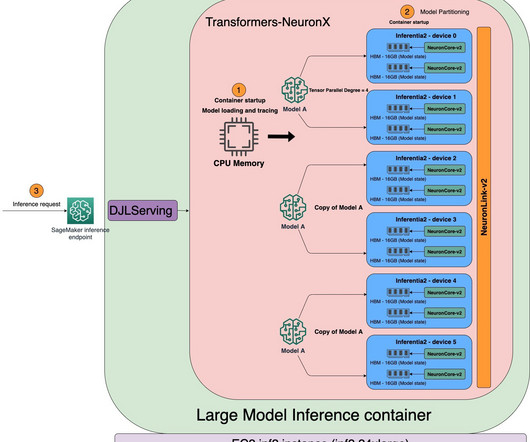
MAX_BATCH_PREFILL_TOKENS : This parameter caps the total number of tokens processed during the prefill stage across all batched requests, a phase that is both memory-intensive and compute-bound, thereby optimizing resource utilization and preventing out-of-memory errors. The best performance was observed on ml.p4dn.24xlarge 48xlarge , ml.g6e.12xlarge
The added benefit of asynchronous inference is the cost savings by auto scaling the instance count to zero when there are no requests to process. SageMaker features and capabilities help developers and data scientists get started with naturallanguageprocessing (NLP) on AWS with ease.
Second, using this graph database along with generativeAI to detect second and third-order impacts from news events. For instance, this solution can highlight that delays at a parts supplier may disrupt production for downstream auto manufacturers in a portfolio though none are directly referenced.
The success of generativeAI applications across a wide range of industries has attracted the attention and interest of companies worldwide who are looking to reproduce and surpass the achievements of competitors or solve new and exciting use cases. as the engines that power the generativeAI innovation.
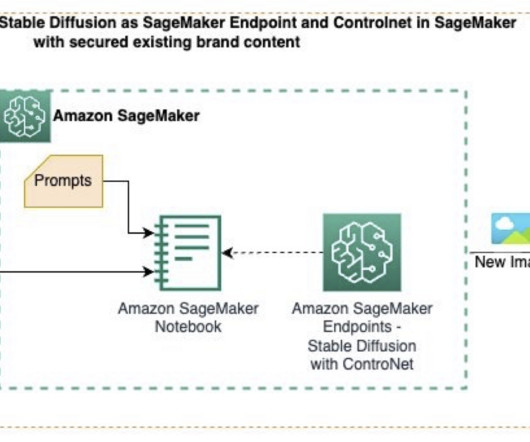
Advertising agencies can use generativeAI and text-to-image foundation models to create innovative ad creatives and content. In this post, we demonstrate how you can generate new images from existing base images using Amazon SageMaker , a fully managed service to build, train, and deploy ML models for at scale.
The world of artificial intelligence (AI) and machine learning (ML) has been witnessing a paradigm shift with the rise of generativeAI models that can create human-like text, images, code, and audio. Compared to classical ML models, generativeAI models are significantly bigger and more complex.
Open foundation models (FMs) have become a cornerstone of generativeAI innovation, enabling organizations to build and customize AI applications while maintaining control over their costs and deployment strategies. You can access your imported custom models on-demand and without the need to manage underlying infrastructure.
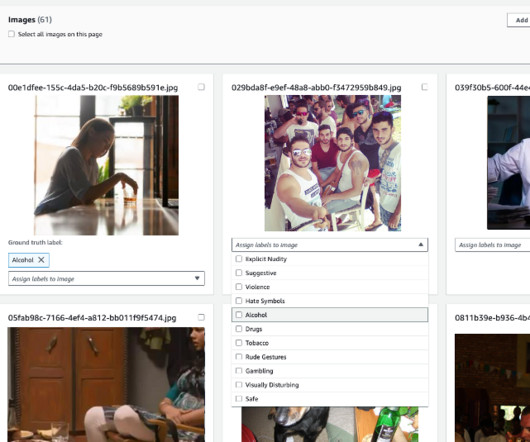
Solution overview Training a custom moderation adapter involves five steps that you can complete using the AWS Management Console or the API interface: Create a project Upload the training data Assign ground truth labels to images Train the adapter Use the adapter Let’s walk through these steps in more detail using the console.
These generativeAI applications are not only used to automate existing business processes, but also have the ability to transform the experience for customers using these applications. This identity is called the AWS account root user.
What is the optimal framework and configuration for hosting large language models (LLMs) for text-generatinggenerativeAI applications? This condition can be a maximum length for the generated text, a specific token that signals the end of the text, or any other criteria set by the user or the application.
We’re at an exciting inflection point in the widespread adoption of machine learning (ML), and we believe most customer experiences and applications will be reinvented with generativeAI. GenerativeAI can create new content and ideas, including conversations, stories, images, videos, and music.
These models aren't just large in terms of size—they're also massive in their capacity to understand human prompts and generate vast amounts of original text. Original naturallanguageprocessing (NLP) models were limited in their understanding of language. Want to dive deeper?
Their impressive generative abilities have led to widespread adoption across various sectors and use cases, including content generation, sentiment analysis, chatbot development, and virtual assistant technology. This results in faster restarts and workload completion. Llama2 by Meta is an example of an LLM offered by AWS.
Yes, we’re all still trying to get our heads around the fact that ChatGPT and AI like it is going to do more and more of our writing for us in coming years, more and more of our everyday jobs for us in coming years — and more and more of our day-to-day thinking for us in coming years.
It’s a next generation model in the Falcon family—a more efficient and accessible large language model (LLM) that is trained on a 5.5 It’s built on causal decoder-only architecture, making it powerful for auto-regressive tasks. After deployment is complete, you will see that an endpoint is created.
Customers can create the custom metadata using Amazon Comprehend , a natural-languageprocessing (NLP) service managed by AWS to extract insights about the content of documents, and ingest it into Amazon Kendra along with their data into the index. For example, metadata can be used for filtering and searching. append(e["Text"].upper())
In recent years, we have seen a big increase in the size of large language models (LLMs) used to solve naturallanguageprocessing (NLP) tasks such as question answering and text summarization. Introduction Modern language models are based on the transformer architecture. compared to 76.4).
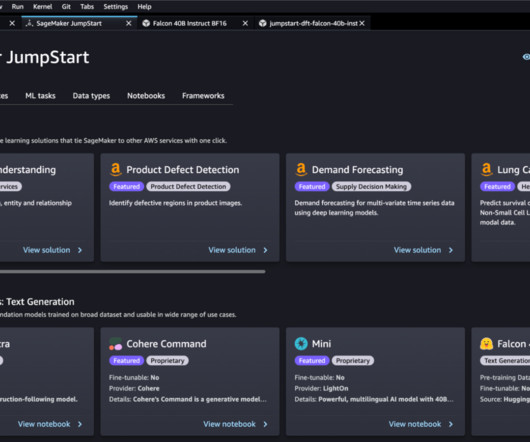
In this post, we showcase how to build an end-to-end generativeAI application for enterprise search with Retrieval Augmented Generation (RAG) by using Haystack pipelines and the Falcon-40b-instruct model from Amazon SageMaker JumpStart and Amazon OpenSearch Service.
Salesforce Einstein is a set of AI technologies that integrate with Salesforce’s Customer Success Platform to help businesses improve productivity and client engagement. SageMaker allowed the Einstein team to use auto-scaling of these GPUs to meet demand without manual intervention.
Introduction GenerativeAI is evolving and getting popular. The major reason for the exponentially increasing popularity is the development of Large Language Models. LLMs, the Artificial Intelligence models that are designed to processnaturallanguage and generate human-like responses, are trending.
Limited options for auto-QA Many companies use automated QA (auto QA) services to monitor customer interactions. However, this is a relatively small market with limited solutions, and most auto-QA tools fail to deliver actionable results. Level AI offers QA-GPT , a powerful QA auditor you can tailor to your exact business.
Auto-Recording & Transcription With MeetGeek AI, you can automatically record and transcribe your meetings for free without taking notes! MeetGeek generatesAI-powered meeting summaries with highlights and actionable tasks that can automatically be shared with others.
To learn more about SageMaker Studio JupyterLab Spaces, refer to Boost productivity on Amazon SageMaker Studio: Introducing JupyterLab Spaces and generativeAI tools. To store information in Secrets Manager, complete the following steps: On the Secrets Manager console, choose Store a new secret.
When the script ends, a completion status along with the time taken will be returned to the SageMaker studio console. Clean up When the Python script is complete, you can save costs by shutting down or stopping the Amazon SageMaker Studio notebook or container that you spun up. We have packaged this solution in a.ipynb script and.py
An intelligent document processing (IDP) project usually combines optical character recognition (OCR) and naturallanguageprocessing (NLP) to read and understand a document and extract specific terms or words. About the Authors Suyin Wang is an AI/ML Specialist Solutions Architect at AWS.
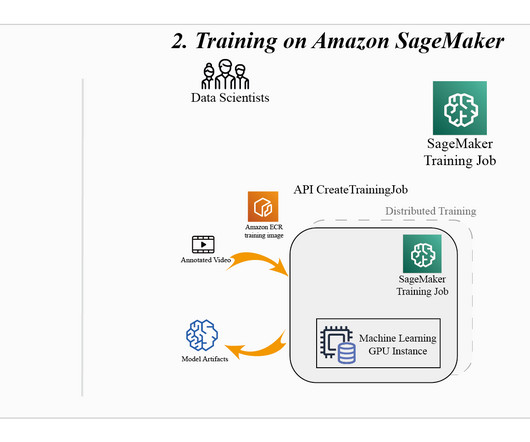
Deploy the trained ByteTrack model with different deployment options depending on your use case: real-time processing, asynchronous, or batch prediction. Prerequisites Before getting started, complete the following prerequisites: Create an AWS account or use an existing AWS account. Create a SageMaker notebook instance.
Be sure to check out their talk, “Evolving Trends in Prompt Engineering for Large Language Models (LLMs) with Built-in Responsible AI Practices,” there! The emergence of Large Language Models (LLMs) has inaugurated a new era in the realm of artificial intelligence, reshaping the possibilities for organizations across diverse sectors.
Now you can also fine-tune 7 billion, 13 billion, and 70 billion parameters Llama 2 text generation models on SageMaker JumpStart using the Amazon SageMaker Studio UI with a few clicks or using the SageMaker Python SDK. In this post, we walk through how to fine-tune Llama 2 pre-trained text generation models via SageMaker JumpStart.
The SageMaker option offers several advantages, including easy integration of image generation APIs with video generation endpoints to create end-to-end pipelines. Once the SageMaker HyperPod cluster deletion is complete, delete the CloudFormation stack. He is passionate about computer vision, NLP, generativeAI, and MLOps.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content