This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Home Table of Contents Getting Started with Python and FastAPI: A Complete Beginner’s Guide Introduction to FastAPI Python What Is FastAPI? Your First Python FastAPI Endpoint Writing a Simple “Hello, World!” Jump Right To The Downloads Section Introduction to FastAPI Python What Is FastAPI?
Agile Development SOPs act as a meta-function here, coordinating agents to auto-generate code based on defined inputs. Steps to Locally Installing MetaGPT on Your System NPM, Python Installation Check & Install NPM : First things first, ensure NPM is installed on your system. The data indicated an average cost of just $1.09
Import the model Complete the following steps to import the model: On the Amazon Bedrock console, choose Imported models under Foundation models in the navigation pane. Importing the model will take several minutes depending on the model being imported (for example, the Distill-Llama-8B model could take 520 minutes to complete).
When comparing ChatGPT with Autonomous AI agents such as Auto-GPT and GPT-Engineer, a significant difference emerges in the decision-making process. Rather than just offering suggestions, agents such as Auto-GPT can independently handle tasks, from online shopping to constructing basic apps. Massive Update for Auto-GPT: Code Execution!
Prerequisites To complete the solution, you need to have the following prerequisites in place: uv package manager Install Python using uv python install 3.13
Jump Right To The Downloads Section Building on FastAPI Foundations In the previous lesson , we laid the groundwork for understanding and working with FastAPI. Interactive Documentation: We showcased the power of FastAPIs auto-generated Swagger UI and ReDoc for exploring and testing APIs. Looking for the source code to this post?
Auto-GPT An open-source GPT-based app that aims to make GPT completely autonomous. What makes Auto-GPT such a popular project? Auto-GPT has “agents” built in to search the web, speak, keep track of conversations, and more. How to Set Up Auto-GPT in Minutes Configure `.env` One of the most popular ones?
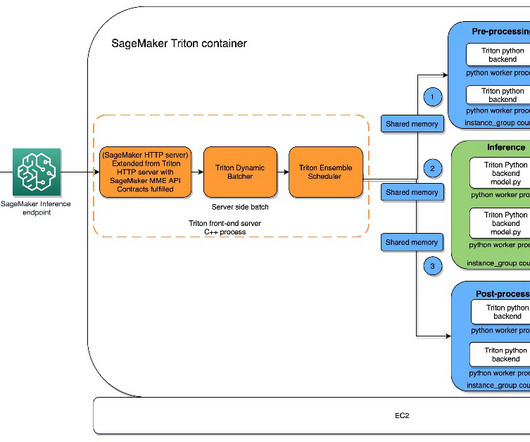
In this post, we help you understand the Python backend that is supported by Triton on SageMaker so that you can make an informed decision for your workloads and achieve great results. It dynamically downloads models from Amazon S3 to the instance’s storage volume if the invoked model isn’t available on the instance storage volume.
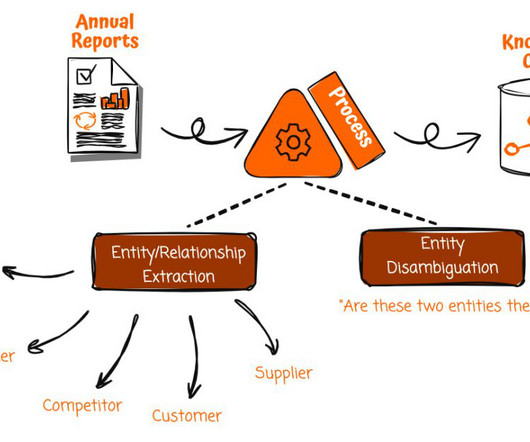
In this post, we look at how we can use AWS Glue and the AWS Lake Formation ML transform FindMatches to harmonize (deduplicate) customer data coming from different sources to get a complete customer profile to be able to provide better customer experience. The following diagram shows our solution architecture.
In this article I will show you how to run a version of the Vicuna model in WSL2 with GPU acceleration and prompt the model from Python via an API. The CUDA toolkit can be downloaded from the NVidia website. Once your CUDA installation completes, reboot your computer. Simply run pythondownload-model.py
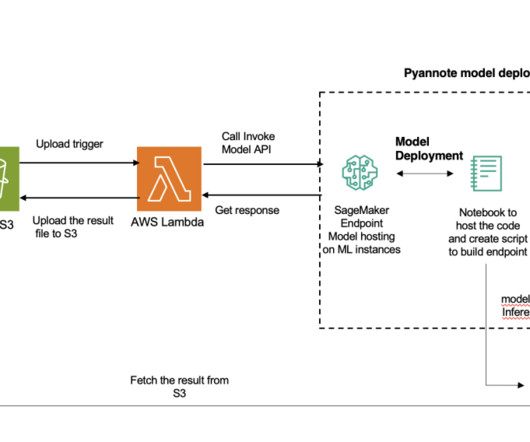
The added benefit of asynchronous inference is the cost savings by auto scaling the instance count to zero when there are no requests to process. PyAnnote is an open source toolkit written in Python for speaker diarization. Prerequisites Complete the following prerequisites: Create a SageMaker domain.
AI subtitle generator applies an AI model to auto-generate subtitles. Try AssemblyAI’s Python SDK to quickly transcribe an audio file The AI subtitle generator then takes this transcription data and outputs a transcription text that is displayed as the speaker speaks throughout the video.
Custom Queries provides a way for you to customize the Queries feature for your business-specific, non-standard documents such as auto lending contracts, checks, and pay statements, in a self-service way. This section will activate your next steps as you complete them sequentially. What is the account name/payer/drawer name?
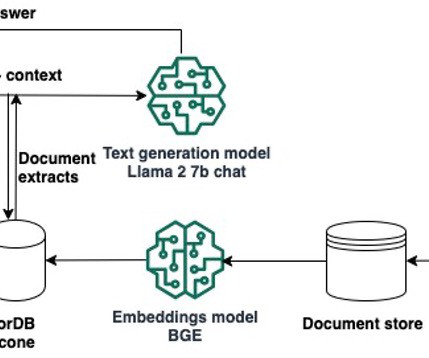
We also discuss how to transition from experimenting in the notebook to deploying your models to SageMaker endpoints for real-time inference when you complete your prototyping. After confirming your quota limit, you need to complete the dependencies to use Llama 2 7b chat. Python 3.10 transformers==4.33.0 accelerate==0.21.0
Python 3.10 The notebook queries the endpoint in three ways: the SageMaker Python SDK, the AWS SDK for Python (Boto3), and LangChain. To make sure that our endpoint can scale down to zero, we need to configure auto scaling on the asynchronous endpoint using Application Auto Scaling. CPU kernel.
x, there is no need to download it separately. You do not need to download the JupyterLab celltags extension separately because it is officially included with JupyterLab 3.x. Tabnine for JupyterLab Typing code is complex without auto-complete options, especially when first starting out.
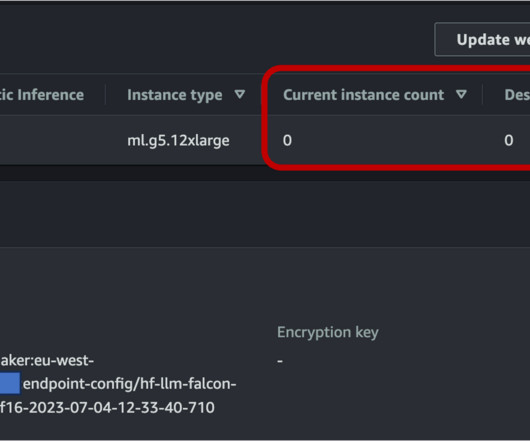
This time-consuming process must be completed before content can be dubbed into another language. SageMaker asynchronous endpoints support upload sizes up to 1 GB and incorporate auto scaling features that efficiently mitigate traffic spikes and save costs during off-peak times.
For instance, this solution can highlight that delays at a parts supplier may disrupt production for downstream auto manufacturers in a portfolio though none are directly referenced. To download actual news, the user chooses Download Latest News to download the top news happening today (powered by NewsAPI.org).
Deploy the CloudFormation template Complete the following steps to deploy the CloudFormation template: Save the CloudFormation template sm-redshift-demo-vpc-cfn-v1.yaml Choose Choose File and navigate to the location on your computer where the CloudFormation template was downloaded and choose the file. yaml locally.
With the SageMaker HyperPod auto-resume functionality, the service can dynamically swap out unhealthy nodes for spare ones to ensure the seamless continuation of the workload. Also included are SageMaker HyperPod cluster software packages, which support features such as cluster health check and auto-resume.
It allows you to easily download and train state-of-the-art pre-trained models. Next, when creating the classifier object, the model was downloaded. Our model gets a prompt and auto-completes it. Let’s go ahead and have a look at what the Transformers library is. What is the Transformers library? Let me explain.
Jump Right To The Downloads Section Building a Dataset for Triplet Loss with Keras and TensorFlow In the previous tutorial , we looked into the formulation of the simplest form of contrastive loss. Start by accessing the “Downloads” section of this tutorial to retrieve the source code and example images. The crop_faces.py
As you type, Path Intellisense will suggest appropriate path completions. On the Visual Studio Marketplace, you may download it for free. HTML, CSS, JavaScript, PHP, and Python are just some of the file formats that may be uploaded and run on Live Server. As you type, Copilot will offer appropriate coding completions.
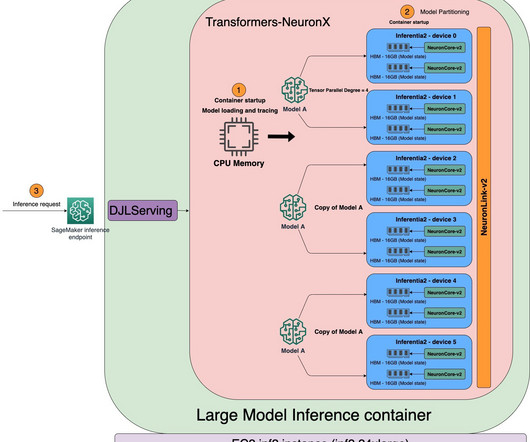
LMI DLCs are a complete end-to-end solution for hosting LLMs like Falcon-40B. The LMI container will help address much of the undifferentiated heavy lifting associated with hosting LLMs, including downloading the model and partitioning the model artifact so that its comprising parameters can be spread across multiple GPUs.
Jump Right To The Downloads Section Training a Custom Image Classification Network for OAK-D Before we start data loading, analysis, and training the classification network on the data, we must carefully pick the suitable classification architecture as it would finally be deployed on the OAK. Looking for the source code to this post?
Prerequisites The following are prerequisites for completing the walkthrough in this post: An AWS account Familiarity with SageMaker concepts, such as an Estimator, training job, and HPO job Familiarity with the Amazon SageMaker Python SDK Python programming knowledge Implement the solution The full code is available in the GitHub repo.
Use a Python notebook to invoke the launched real-time inference endpoint. Basic knowledge of Python, Jupyter notebooks, and ML. Another option is to downloadcomplete data for your ML model training use cases using SageMaker Data Wrangler processing jobs. This is a one-time setup.
Going from Data to Insights LexisNexis At HPCC Systems® from LexisNexis® Risk Solutions you’ll find “a consistent data-centric programming language, two processing platforms, and a single, complete end-to-end architecture for efficient processing.” became one of “the most downloaded interactive graphing libraries in the world.”
Llama 2 is an auto-regressive language model that uses an optimized transformer architecture and is intended for commercial and research use in English. This results in faster restarts and workload completion. Prerequisites You need to complete some prerequisites before you can run the first notebook.
Import the model Complete the following steps to import the model: On the Amazon Bedrock console, choose Imported models under Foundation models in the navigation pane. Importing the model will take several minutes depending on the model being imported (for example, the Distill-Llama-8B model could take 520 minutes to complete).
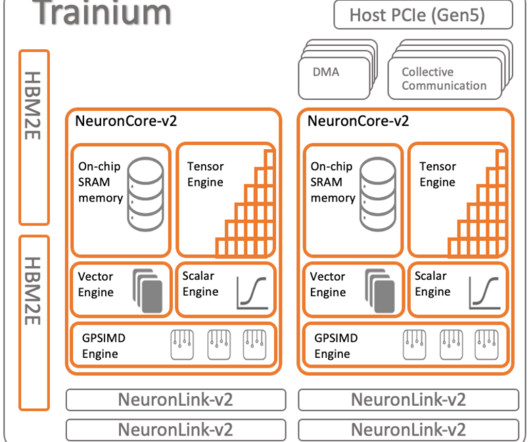
For ultra-large models that don’t fit into a single accelerator, data flows directly between accelerators with NeuronLink, bypassing the CPU completely. You can use the SageMaker Python SDK to deploy models using popular deep learning frameworks such as PyTorch, as shown in the following code.
Jupyter notebooks can differentiate between SQL and Python code using the %%sm_sql magic command, which must be placed at the top of any cell that contains SQL code. This command signals to JupyterLab that the following instructions are SQL commands rather than Python code. For Secret type , choose Other type of secret.
One of the primary reasons that customers are choosing a PyTorch framework is its simplicity and the fact that it’s designed and assembled to work with Python. TorchScript is a static subset of Python that captures the structure of a PyTorch model. Triton uses TorchScript for improved performance and flexibility. xlarge instance.
After this step, you now have a transcription complete with accurate speaker labels! Test AssemblyAI's Speaker Diarization for Free in AI Playground PyAnnote PyAnnote is an open source Speaker Diarization toolkit written in Python and built based on the PyTorch Machine Learning framework. or later, on Linux and MacOS.
Regular CPU systems are completely memory bound for these calculations, and performance is limited by the time required to move the data into the CPU. Note all necessary software, drivers, and tools have already been installed on the DLAMIs, and only the activation of the Python environment is needed to start working with the tutorial.
When training is complete (through the Lambda step), the deployed model is updated to the SageMaker endpoint. When the preprocessing batch was complete, the training/test data needed for training was partitioned based on runtime and stored in Amazon S3. This means keeping the same PyTorch and Python versions for training and inference.
Build and deploy your own sentiment classification app using Python and Streamlit Source:Author Nowadays, working on tabular data is not the only thing in Machine Learning (ML). In this article, you will learn about what sentiment analysis is and how you can build and deploy a sentiment analysis system in Python.
First, launch the notebook main.ipynb in SageMaker Studio by selecting the Image as Data Science and Kernel as Python 3. jpg and the complete metadata from styles/38642.json. You need to clone this GitHub repository for replicating the solution demonstrated in this post. lora_alpha=32, # the alpha parameter for Lora scaling.
Model downloading and loading Large language models incur long download times (for example, 40 minutes to download BLOOM-176B). It has faster loading and uses multi-process loading on Python. In this post, we showcase how to download the weights to Amazon S3 and then use them when configuring the container.
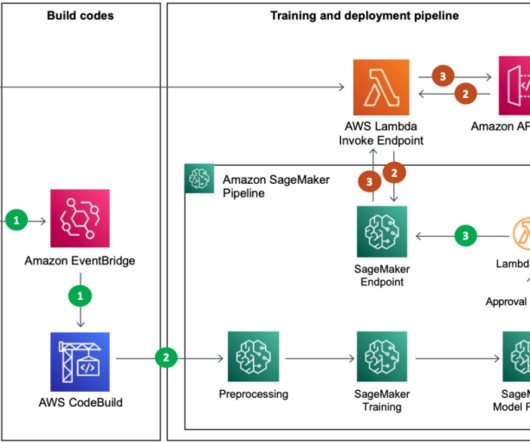
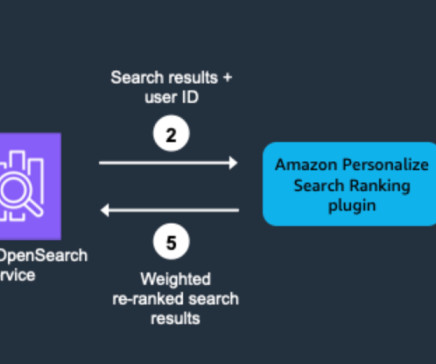
Complete the following steps to deploy the stack: Sign in to the AWS Management Console with your credentials in the account where you want to deploy the CloudFormation stack. Complete creating the stack and monitor the status on the stack details page. Set up and complete the Amazon Personalize workflow Open the 1.Configure_Amazon_Personalize.ipynb
Prerequisites Complete the following prerequisite steps: If you’re a first-time user of QuickSight in your AWS account, sign up for QuickSight. Dockerfile requirements.txt Create an Amazon Elastic Container Registry (Amazon ECR) repository in us-east-1 and push the container image created by the downloaded Dockerfile. Choose Next.
Scrapy A powerful, open-source Python framework called Scrapy was created for highly effective web scraping and data extraction. This tool’s AI-powered auto-detect functionality makes data collecting as simple as point-and-click by automatically recognizing data fields on the majority of websites. For enhanced privacy, Dexi.io
Life however decided to take me down a different path (partly thanks to Fujifilm discontinuing various films ), although I have never quite completely forgotten about glamour photography. Variational Auto-Encoder — Generates the final output image by decoding the latent space images to pixel space. Image created by the author.
In our case, we use some custom training code in Python based on Scikit-learn. We opted for providing our own Python script and using Scikit-learn as our framework. We provide the custom training code in Python, reference some dependent libraries, and make a test run. Next, prepare the training script and framework dependencies.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























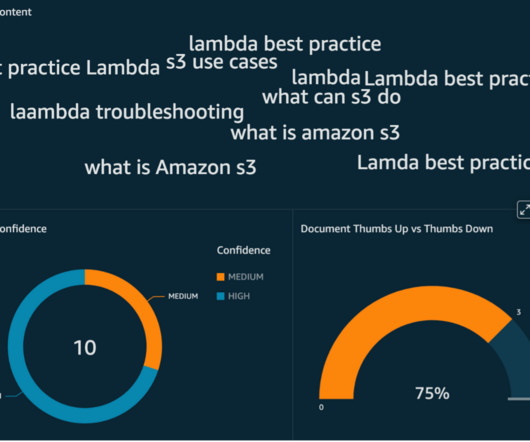


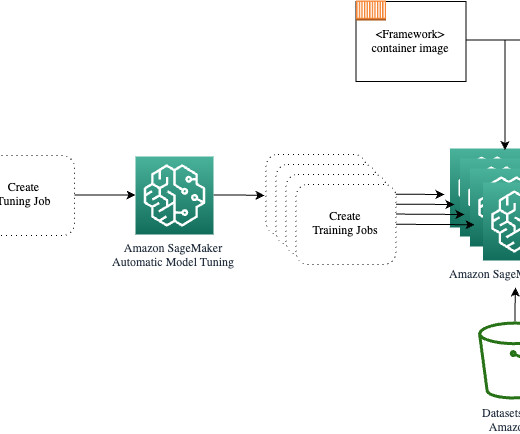






Let's personalize your content