This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It does this with AI-driven features like auto-reframing, generating dynamic captions in 50+ languages, and customization. AI Video Editing Features Klap AI's video editing features include the following: Content Extraction Auto-Reframing Caption Generation Customization 1. Auto: For TikTok, Instagram Reels, etc.
Agile Development SOPs act as a meta-function here, coordinating agents to auto-generate code based on defined inputs. If you're not up-to-date, download the latest version from the Python official website. The post MetaGPT: Complete Guide to the Best AI Agent Available Right Now appeared first on Unite.AI.
HF_TOKEN : This parameter variable provides the access token required to download gated models from the Hugging Face Hub, such as Llama or Mistral. For a complete list of runtime configurations, please refer to text-generation-launcher arguments. Model Base Model Download DeepSeek-R1-Distill-Qwen-1.5B meta-llama/Llama-3.2-11B-Vision-Instruct
A practical guide on how to perform NLP tasks with Hugging Face Pipelines Image by Canva With the libraries developed recently, it has become easier to perform deep learning analysis. Hugging Face is a platform that provides pre-trained language models for NLP tasks such as text classification, sentiment analysis, and more.
We are thrilled to release NLP Lab 5.4 which brings a host of exciting enhancements to further empower your NLP journey. Publish Models Directly into Models HUB We’re excited to introduce a streamlined way to publish NLP models to the NLP Models HUB directly from NLP Lab.
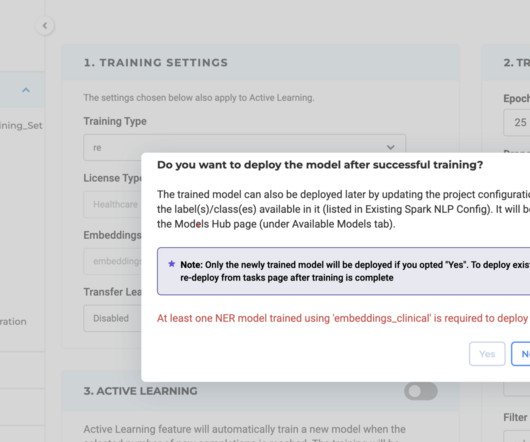
Training Relations Extraction (RE) Model We are excited to announce that NLP Lab 5.7 Key benefits include: Customizable RE Model Development: Tailor RE models to your specific needs for text analysis, expanding the breadth of Model Training and Active Learning within the NLP Lab.
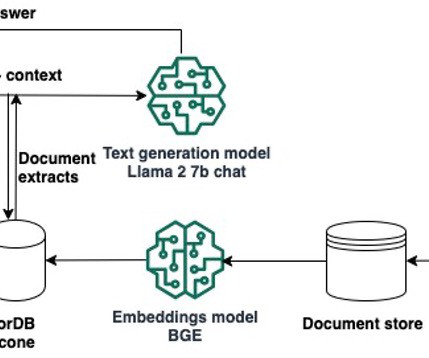
We also discuss how to transition from experimenting in the notebook to deploying your models to SageMaker endpoints for real-time inference when you complete your prototyping. After confirming your quota limit, you need to complete the dependencies to use Llama 2 7b chat. Download and save the model in the local directory in Studio.
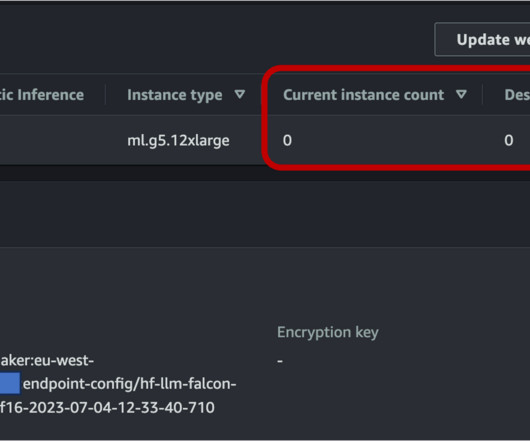
The added benefit of asynchronous inference is the cost savings by auto scaling the instance count to zero when there are no requests to process. SageMaker features and capabilities help developers and data scientists get started with natural language processing (NLP) on AWS with ease.
The CUDA toolkit can be downloaded from the NVidia website. Once your CUDA installation completes, reboot your computer. Download model Now that all dependencies are installed, we are ready to download a model. The text-generation-webui provides a handy script which will place the downloaded model in the correct location.
This time-consuming process must be completed before content can be dubbed into another language. SageMaker asynchronous endpoints support upload sizes up to 1 GB and incorporate auto scaling features that efficiently mitigate traffic spikes and save costs during off-peak times.
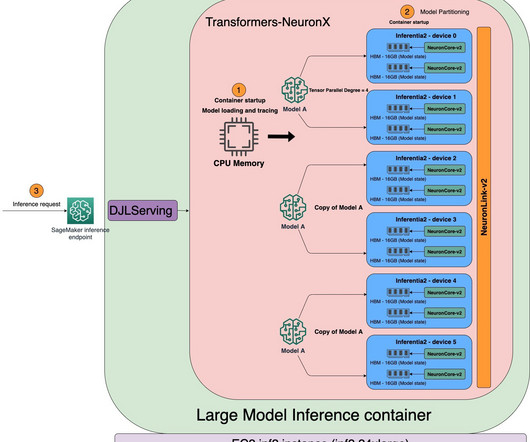
LMI DLCs are a complete end-to-end solution for hosting LLMs like Falcon-40B. The LMI container will help address much of the undifferentiated heavy lifting associated with hosting LLMs, including downloading the model and partitioning the model artifact so that its comprising parameters can be spread across multiple GPUs.
Going from Data to Insights LexisNexis At HPCC Systems® from LexisNexis® Risk Solutions you’ll find “a consistent data-centric programming language, two processing platforms, and a single, complete end-to-end architecture for efficient processing.” became one of “the most downloaded interactive graphing libraries in the world.”
Trusted by over 100,000 companies, Speak AI is a Toronto-based advanced transcription tool that uses artificial intelligence and natural language processing (NLP) to convert unstructured language data, such as important audio files, into text data. Auto-scroll: Highlight the sentence to show where you are in the transcript.
These models have revolutionized various computer vision (CV) and natural language processing (NLP) tasks, including image generation, translation, and question answering. To make sure that our endpoint can scale down to zero, we need to configure auto scaling on the asynchronous endpoint using Application Auto Scaling.
Llama 2 is an auto-regressive language model that uses an optimized transformer architecture and is intended for commercial and research use in English. This results in faster restarts and workload completion. Prerequisites You need to complete some prerequisites before you can run the first notebook.
There will be a lot of tasks to complete. I came up with an idea of a Natural Language Processing (NLP) AI program that can generate exam questions and choices about Named Entity Recognition (who, what, where, when, why). This is the link [8] to the article about this Zero-Shot Classification NLP. Are you ready to explore?
Using machine learning (ML) and natural language processing (NLP) to automate product description generation has the potential to save manual effort and transform the way ecommerce platforms operate. jpg and the complete metadata from styles/38642.json. From here, we can fetch the image for this product from images/38642.jpg
For computers to process, analyze, interpret, and reason about human language, a subfield of AI known as natural language processing (NLP) is required. Natural language processing (NLP) is an interdisciplinary field that draws on methods from disciplines as diverse as linguistics and computer science. With Nova A.I.,
Amazon Kendra is a highly accurate and intelligent search service that enables users to search unstructured and structured data using natural language processing (NLP) and advanced search algorithms. Prerequisites Complete the following prerequisite steps: If you’re a first-time user of QuickSight in your AWS account, sign up for QuickSight.
To store information in Secrets Manager, complete the following steps: On the Secrets Manager console, choose Store a new secret. Complete the following steps: On the Secrets Manager console, choose Store a new secret. Always make sure that sensitive data is handled securely to avoid potential security risks.
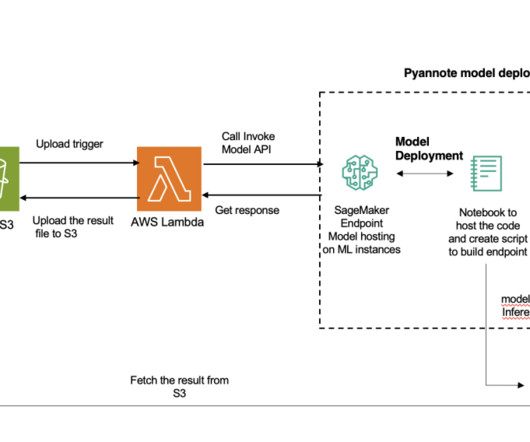
Model downloading and loading Large language models incur long download times (for example, 40 minutes to download BLOOM-176B). The faster option is to download the model weights into Amazon S3 and then use the LMI container to download them to the container from Amazon S3.
For ultra-large models that don’t fit into a single accelerator, data flows directly between accelerators with NeuronLink, bypassing the CPU completely. These endpoints are fully managed and support auto scaling. When the tracing is complete, the model is partitioned across the NeuronCores based on the tensor parallel degree.
Limited options for auto-QA Many companies use automated QA (auto QA) services to monitor customer interactions. However, this is a relatively small market with limited solutions, and most auto-QA tools fail to deliver actionable results. Oftentimes, they fail to produce accurate or relevant results. Get a free demo today!
It dynamically downloads models from Amazon S3 to the instance’s storage volume if the invoked model isn’t available on the instance storage volume. SageMaker MMEs can horizontally scale using an auto scaling policy and provision additional GPU compute instances based on specified metrics.
This version offers support for new models (including Mixture of Experts), performance and usability improvements across inference backends, as well as new generation details for increased control and prediction explainability (such as reason for generation completion and token level log probabilities).
With kernel auto-tuning, the engine selects the best algorithm for the target GPU, maximizing hardware utilization. It dynamically downloads models from Amazon Simple Storage Service (Amazon S3) to the instance’s storage volume if the invoked model isn’t available on the instance storage volume. script from the following cell.
SpanCategorizer for predicting arbitrary and overlapping spans A common task in applied NLP is extracting spans of texts from documents, including longer phrases or nested expressions. skweak Toolkit for weak supervision applied to NLP tasks ? en_ner_fashion./output output --build wheel cd. spaCy v3.1 : What’s new in v3.1
It’s much easier to configure and train your pipeline, and there are lots of new and improved integrations with the rest of the NLP ecosystem. And since modern NLP workflows often consist of multiple steps, there’s a new workflow system to help you keep your work organized. See NLP-progress for more results. Flair 2 89.7
Prerequisites Before getting started, complete the following prerequisites: Create an AWS account or use an existing AWS account. Set up your resources After you complete all the prerequisites, you’re ready to deploy the solution. He is passionate about computer vision, NLP, Generative AI and MLOps. medium instance type.
Smart assistants such as Siri and Alexa, YouTube video recommendations, conversational bots, among others all use some form of NLP similar to GPT-3. According to OpenAI , “Over 300 applications are delivering GPT-3–powered search, conversation, text completion, and other advanced AI features through our API.” Download now.
After you have achieved your desired results with filters and groupings, you can either download your results by choosing Download as CSV or save the report by choosing Save to report library. If all are successful, then the batch transform job is marked as complete. SageMaker supports auto scaling for asynchronous endpoints.
What is Llama 2 Llama 2 is an auto-regressive language model that uses an optimized transformer architecture. Write a response that appropriately completes the request.nn### Instruction:nWhen did Felix Luna die?nn### In this post, we walk through how to fine-tune Llama 2 pre-trained text generation models via SageMaker JumpStart.
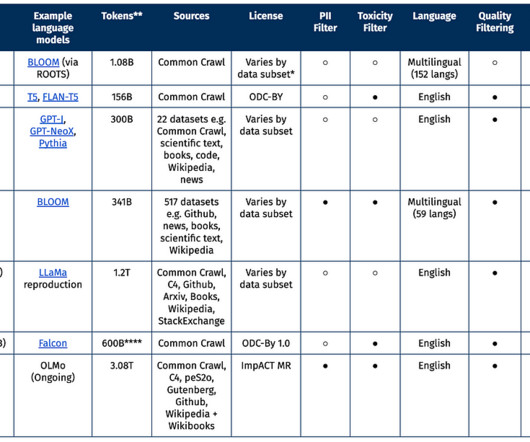
AI2 Dolma: 3 Trillion Token Open Corpus for Language Model Pretraining Since March, we at the Allen Institute for AI have been creating OLMo , an open language model to promote the study of large-scale NLP systems. Openly available for download on the HuggingFace Hub under AI2’s ImpACT license , Dolma is the largest open dataset to date.
Dataset Description Auto-Arborist A multiview urban tree classification dataset that consists of ~2.6M Bazel GitHub Metrics A dataset with GitHub download counts of release artifacts from selected bazelbuild repositories. UGIF A multi-lingual, multi-modal UI grounded dataset for step-by-step task completion on the smartphone.
The preparation of a natural language processing (NLP) dataset abounds with share-nothing parallelism opportunities. For more information, refer to Train 175+ billion parameter NLP models with model parallel additions and Hugging Face on Amazon SageMaker. This results in faster restarts and workload completion.
from_disk("/path/to/s2v_reddit_2015_md") nlp.add_pipe(s2v) doc = nlp("A sentence about natural language processing.") The pattern files, datasets and training and evaluation scripts created for this blog post are available for download in our new projects repo. For more examples and the full API documentation, see the GitHub repo.
Also, science projects around technologies like predictive modeling, computer vision, NLP, and several profiles like commercial proof of concepts and competitions workshops. When we speak about like NLP problems or classical ML problems with tabular data when the data can be spread in huge databases. This is a much harder thing.
We’ll discuss how it streamlines workflows for NLP tasks, enables real-time conversations with giant conversational models, and much more. In this article, we will explore beam.cloud , an easy and powerful swiss-army-knife for running LLMs and code directly on the cloud.
Related post Tokenization in NLP: Types, Challenges, Examples, Tools Read more For training, we’ll create a so-called prompt that contains not only the question and the context but also the answer. <pre class =" hljs " style =" display : block; overflow-x: auto; padding: 0.5 For GPT2-large, instead of needing 2.9
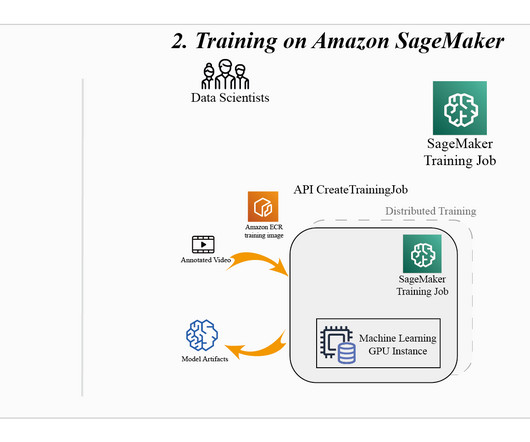
It manages the availability and scalability of the Kubernetes control plane, and it provides compute node auto scaling and lifecycle management support to help you run highly available container applications. Training Now that our data preparation is complete, we’re ready to train our model with the created dataset.
These tools leverage artificial intelligence (AI) and natural language processing (NLP) technologies to assist in creating, optimizing, and managing content for various social media platforms. With this tool, you get a complete picture of your brand's performance on social.
This enhancement builds upon the existing auto scaling capabilities in SageMaker, offering more granular control over resource allocation. Compressed model files may save storage space, but they require additional time to uncompress and files can’t be downloaded in parallel, which can slow down the scale-up process.
Technical Deep Dive of Llama 2 For training the Llama 2 model; like its predecessors, it uses an auto-regressive transformer architecture , pre-trained on an extensive corpus of self-supervised data. Email Confirmation : Once the form is submitted, you'll receive an email from Meta with a link to download the model from their git repository.
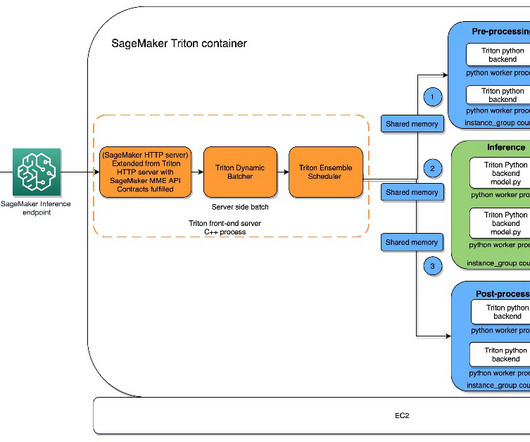
The models can be completely heterogenous, with their own independent serving stack. After these business logic steps are complete, the inputs are passed through to ML models. It can especially be handy in cases with NLP and computer vision, where there are large payloads that require longer preprocessing times.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content