This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This capability enhances responses from generative AI applications by automatically creating embeddings for semantic search and generating a graph of the entities and relationships extracted from ingested documents. This new capability integrates the power of graph data modeling with advanced natural language processing (NLP).
This advancement has spurred the commercial use of generative AI in natural language processing (NLP) and computer vision, enabling automated and intelligent data extraction. Named Entity Recognition ( NER) Named entity recognition (NER), an NLP technique, identifies and categorizes key information in text.
It suggests code snippets and even completes entire functions based on natural language prompts. TabNine TabNine is an AI-powered code auto-completion tool developed by Codota, designed to enhance coding efficiency across a variety of Integrated Development Environments (IDEs).
Photo by Kunal Shinde on Unsplash NATURAL LANGUAGE PROCESSING (NLP) WEEKLY NEWSLETTER NLP News Cypher | 08.09.20 What is the state of NLP? For an overview of some tasks, see NLP Progress or our XTREME benchmark. In the next post, I will outline interesting research directions and opportunities in multilingual NLP.”
The traditional approach of manually sifting through countless research documents, industry reports, and financial statements is not only time-consuming but can also lead to missed opportunities and incomplete analysis. This event-driven architecture provides immediate processing of new documents. Follow Octus on LinkedIn and X.
Auto-generated code suggestions can increase developers’ productivity and optimize their workflow by providing straightforward answers, handling routine coding tasks, reducing the need to context switch and conserving mental energy. It includes code formatting, language detection and documentation.
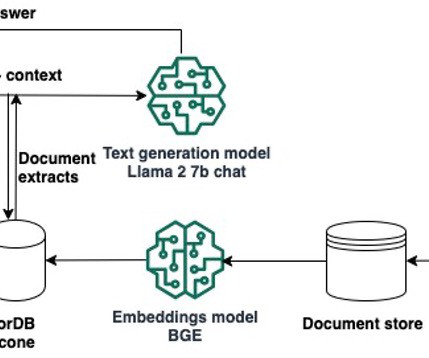
A typical RAG solution for knowledge retrieval from documents uses an embeddings model to convert the data from the data sources to embeddings and stores these embeddings in a vector database. When a user asks a question, it searches the vector database and retrieves documents that are most similar to the user’s query.
Agile Development SOPs act as a meta-function here, coordinating agents to auto-generate code based on defined inputs. link] MetaGPT Demo Run MetaGPT provided a system design document in Markdown—a commonly used lightweight markup language. Below is a video that showcases the actual run of the generated game code.
Enterprises may want to add custom metadata like document types (W-2 forms or paystubs), various entity types such as names, organization, and address, in addition to the standard metadata like file type, date created, or size to extend the intelligent search while ingesting the documents.
From completing entire lines of code and functions to writing comments and aiding in debugging and security checks, Copilot serves as an invaluable tool for developers. Mintlify Mintlify is a time-saving tool that auto-generates code documentation directly in your favorite code editor.
The NLP Lab, a No-Code prominent tool in this field, has been at the forefront of such evolution, constantly introducing cutting-edge features to simplify and improve document analysis tasks. The recently published enhancements of this feature have significantly boosted its utility when dealing with large documents.
In zero-shot learning, no examples of task completion are provided in the model. Chain-of-thought Prompting Chain-of-thought prompting leverages the inherent auto-regressive properties of large language models (LLMs), which excel at predicting the next word in a given sequence. On the other hand, CommonsenseQA 2.0,
From completing entire lines of code and functions to writing comments and aiding in debugging and security checks, Copilot serves as an invaluable tool for developers. Mintlify Mintlify is a time-saving tool that auto-generates code documentation directly in your favorite code editor.
Trusted by over 100,000 companies, Speak AI is a Toronto-based advanced transcription tool that uses artificial intelligence and natural language processing (NLP) to convert unstructured language data, such as important audio files, into text data. Auto-scroll: Highlight the sentence to show where you are in the transcript.
It also has a built-in plagiarism checker and uses natural language processing (NLP terms) to optimize content for SEO and provide relevant keyword suggestions, which search engines like Google will love. Scalenut is an all-in-one AI writing tool with a user-friendly interface and many useful features to speed up content creation.
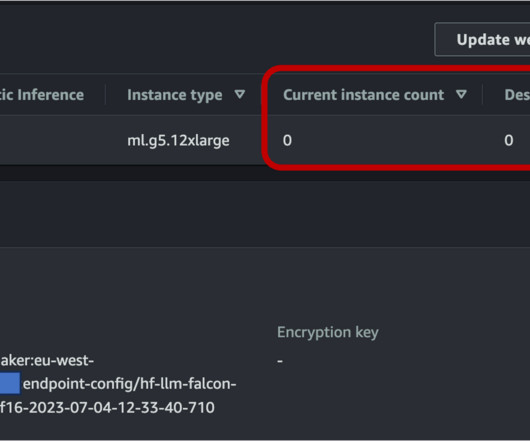
The added benefit of asynchronous inference is the cost savings by auto scaling the instance count to zero when there are no requests to process. SageMaker features and capabilities help developers and data scientists get started with natural language processing (NLP) on AWS with ease.
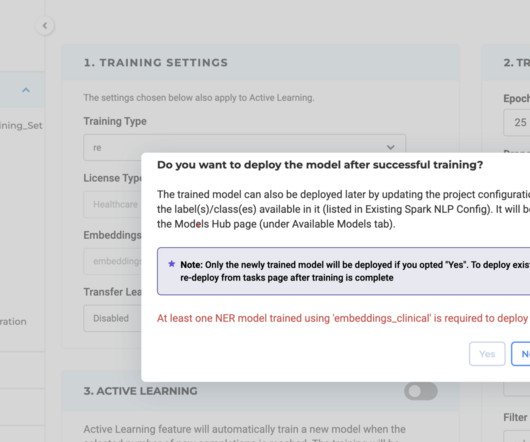
This new release demonstrates our continuous commitment to delivering advanced tools for text analysis and document processing tailored to address our users’ evolving needs. Training Relations Extraction (RE) Model We are excited to announce that NLP Lab 5.7 offers training features for Relation Extraction (RE) models.
To learn more about Hugging Face TGI support on Amazon SageMaker AI, refer to this announcement post and this documentation on deploy models to Amazon SageMaker AI. For a complete list of runtime configurations, please refer to text-generation-launcher arguments. The best performance was observed on ml.p4dn.24xlarge 48xlarge , ml.g6e.12xlarge
These models have revolutionized various computer vision (CV) and natural language processing (NLP) tasks, including image generation, translation, and question answering. To make sure that our endpoint can scale down to zero, we need to configure auto scaling on the asynchronous endpoint using Application Auto Scaling.
Kernel Auto-tuning : TensorRT automatically selects the best kernel for each operation, optimizing inference for a given GPU. Natural Language Processing (NLP) : TensorRT improves the speed of NLP tasks like text generation, translation, and summarization, making them suitable for real-time applications. build/tensorrt_llm*.whl
The applications of graph classification are numerous, and they range from determining whether a protein is an enzyme or not in bioinformatics to categorizing documents in natural language processing (NLP) or social network analysis, among other things. In order to create a complete GCN, we can combine one or more layers.
An intelligent document processing (IDP) project usually combines optical character recognition (OCR) and natural language processing (NLP) to read and understand a document and extract specific terms or words. This can be achieved by updating the endpoint’s inference units (IUs).
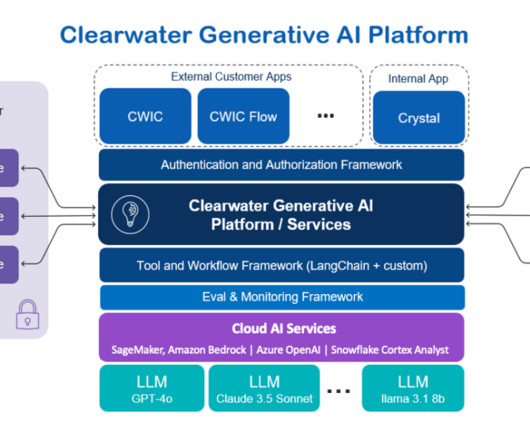
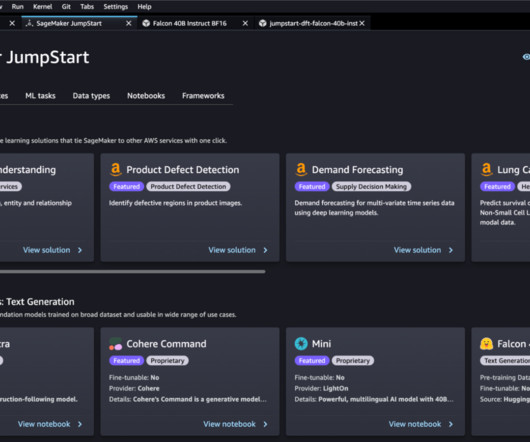
Each specialist is underpinned by thousands of pages of domain documentation, which feeds into the RAG system and is used to train smaller, specialized models with Amazon SageMaker JumpStart. Document assembly Gather all relevant documents that will be used for training.
Amazon Kendra is a highly accurate and intelligent search service that enables users to search unstructured and structured data using natural language processing (NLP) and advanced search algorithms. With Amazon Kendra, you can find relevant answers to your questions quickly, without sifting through documents. Choose Next.
Using machine learning (ML) and natural language processing (NLP) to automate product description generation has the potential to save manual effort and transform the way ecommerce platforms operate. jpg and the complete metadata from styles/38642.json. You can follow the steps in the documentation to enable model access.
Enterprise search is a critical component of organizational efficiency through document digitization and knowledge management. Enterprise search covers storing documents such as digital files, indexing the documents for search, and providing relevant results based on user queries. Initialize DocumentStore and index documents.
For computers to process, analyze, interpret, and reason about human language, a subfield of AI known as natural language processing (NLP) is required. Natural language processing (NLP) is an interdisciplinary field that draws on methods from disciplines as diverse as linguistics and computer science.
To get started, complete the following steps: On the File menu, choose New and Terminal. Use CodeWhisperer in Studio After we complete the installation steps, we can use CodeWhisperer by opening a new notebook or Python file. In this section, we look at the steps involved. For our example we will open a sample Notebook.
and NLP to determine what people were talking about. Using AI-powered insights, businesses arm themselves with a complete picture of the lead journey, from initial contact to final outcomes, across both digital and offline channels. Is the foundation of summaries, agent coaching, auto qualification, to name a few.
In recent years, we have seen a big increase in the size of large language models (LLMs) used to solve natural language processing (NLP) tasks such as question answering and text summarization. Next, we perform auto-regressive token generation where the output tokens are generated sequentially. compared to 76.4).
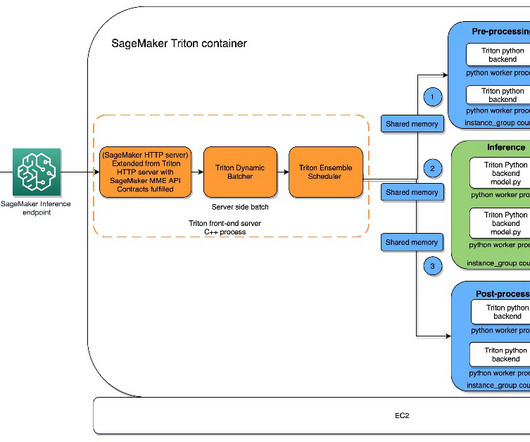
SageMaker MMEs can horizontally scale using an auto scaling policy and provision additional GPU compute instances based on specified metrics. Returns - pb_utils.ModelConfig An object containing the auto-completed model configuration """ def initialize(self, args): `initialize` is called only once when the model is being loaded.
In the field of Natural Language Processing (NLP), Retrieval Augmented Generation, or RAG, has attracted much attention lately. To make sure the knowledge base is as precise and complete as feasible, duplicates should also be removed.
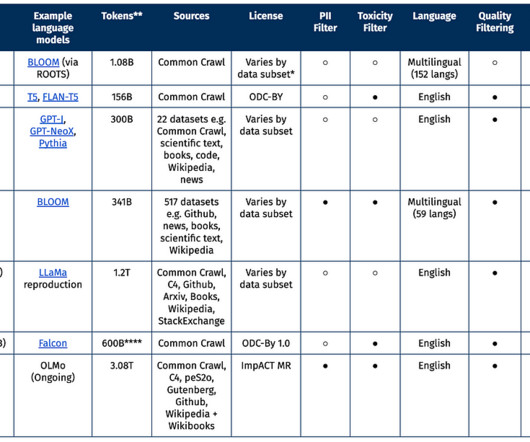
AI2 Dolma: 3 Trillion Token Open Corpus for Language Model Pretraining Since March, we at the Allen Institute for AI have been creating OLMo , an open language model to promote the study of large-scale NLP systems. For more details, we also release a data sheet (Gebru et al, 2018) as initial documentation. Representativeness.
With kernel auto-tuning, the engine selects the best algorithm for the target GPU, maximizing hardware utilization. SageMaker MMEs can horizontally scale using an auto scaling policy and provision additional GPU compute instances based on specified metrics. Note that the cell takes around 30 minutes to complete. !docker
Natural Language Processing (NLP) is one of the most important components of artificial intelligence. And companies across the world are investing more and more in NLP-based solutions. Chatbots use NLP to help your customers get immediate answers to any question, no matter the time of day or day of the week. How’s that possible?
Llama 2 is an auto-regressive language model that uses an optimized transformer architecture and is intended for commercial and research use in English. This results in faster restarts and workload completion. Prerequisites You need to complete some prerequisites before you can run the first notebook.
This time-consuming process must be completed before content can be dubbed into another language. SageMaker asynchronous endpoints support upload sizes up to 1 GB and incorporate auto scaling features that efficiently mitigate traffic spikes and save costs during off-peak times. The results are based mostly on the time of the segments.
To remove an element, omit the text parameter completely. You should be able to adapt the patterns for your own applications by referencing the parameter details for those task types detailed in Amazon Titan Image Generator documentation. Use the BedrockRuntime client to invoke the Titan Image Generator model.
SpanCategorizer for predicting arbitrary and overlapping spans A common task in applied NLP is extracting spans of texts from documents, including longer phrases or nested expressions. skweak Toolkit for weak supervision applied to NLP tasks ? en_ner_fashion./output output --build wheel cd. spaCy v3.1 : What’s new in v3.1
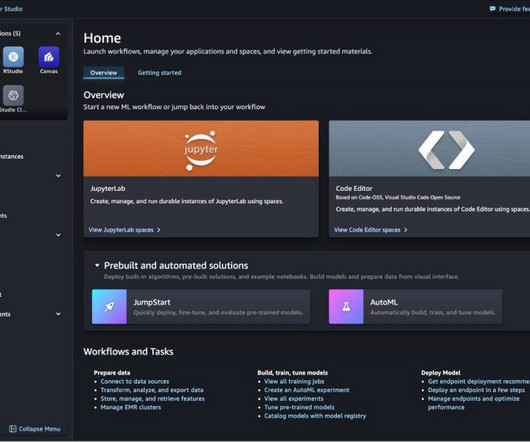
Complete the following steps to edit an existing space: On the space details page, choose Stop space. To start using Amazon CodeWhisperer, make sure that the Resume Auto-Suggestions feature is activated. Detailed information about this release is available in the official JupyterLab Documentation. Choose Create JupyterLab space.
The pay-off is the.pipe() method, which adds data-streaming capabilities to spaCy: import spacy nlp = spacy.load('de') for doc in nlp.pipe(texts, n_threads=16, batch_size=10000): analyse_text(doc) My favourite post on the Zen of Python iterators was written by Radim, the creator of Gensim. So, let’s start with the pay-off. Lower is better.
Are you curious about the groundbreaking advancements in Natural Language Processing (NLP)? Prepare to be amazed as we delve into the world of Large Language Models (LLMs) – the driving force behind NLP’s remarkable progress. Ever wondered how machines can understand and generate human-like text?
It’s much easier to configure and train your pipeline, and there are lots of new and improved integrations with the rest of the NLP ecosystem. And since modern NLP workflows often consist of multiple steps, there’s a new workflow system to help you keep your work organized. See NLP-progress for more results. Flair 2 89.7
In addition, the emergence of smartphones and electronic documents also lead to further advancements in OCR technology. In short, optical character recognition software helps convert images or physical documents into a searchable form. Since then, OCR technology has experienced multiple developmental phases.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content