This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Application modernization is the process of updating legacy applications leveraging modern technologies, enhancing performance and making it adaptable to evolving business speeds by infusing cloud native principles like DevOps, Infrastructure-as-code (IAC) and so on. Let us explore the GenerativeAI possibilities across these lifecycle areas.
Application Auto Scaling is enabled on AWS Lambda to automatically scale Lambda according to user interactions. The solution will confer with responsible AI policies and Guardrails for Amazon Bedrock will enforce organizational responsible AI policies.
By surrounding unparalleled human expertise with proven technology, data and AI tools, Octus unlocks powerful truths that fuel decisive action across financial markets. Visit octus.com to learn how we deliver rigorously verified intelligence at speed and create a complete picture for professionals across the entire credit lifecycle.
If you prefer to generate post call recording summaries with Amazon Bedrock rather than Amazon SageMaker, checkout this Bedrock sample solution. They are designed for real-time, interactive, and low-latency workloads and provide auto scaling to manage load fluctuations. The format of the recordings must be either.mp4,mp3, or.wav.
This post was written in collaboration with Bhajandeep Singh and Ajay Vishwakarma from Wipro’s AWS AI/ML Practice. Data science and DevOps teams may face challenges managing these isolated tool stacks and systems. AWS also helps data science and DevOps teams to collaborate and streamlines the overall model lifecycle process.
Launch the instance using Neuron DLAMI Complete the following steps: On the Amazon EC2 console, choose your desired AWS Region and choose Launch Instance. You can update your Auto Scaling groups to use new AMI IDs without needing to create new launch templates or new versions of launch templates each time an AMI ID changes.
It’s a next generation model in the Falcon family—a more efficient and accessible large language model (LLM) that is trained on a 5.5 It’s built on causal decoder-only architecture, making it powerful for auto-regressive tasks. After deployment is complete, you will see that an endpoint is created.
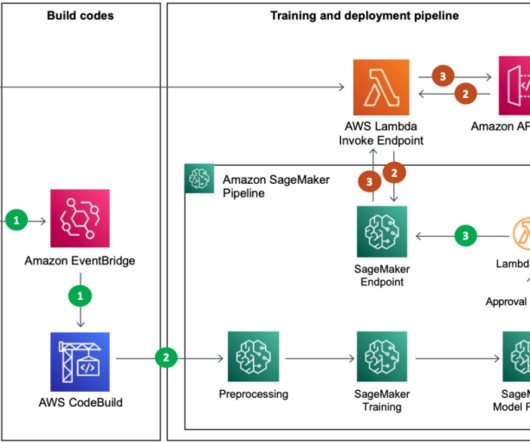
When training is complete (through the Lambda step), the deployed model is updated to the SageMaker endpoint. When the preprocessing batch was complete, the training/test data needed for training was partitioned based on runtime and stored in Amazon S3. We load tested it with Locust using five g4dn.2xlarge
NVIDIA NeMo Framework NVIDIA NeMo is an end-to-end cloud-centered framework for training and deploying generativeAI models with billions and trillions of parameters at scale. NVIDIA NeMo simplifies generativeAI model development, making it more cost-effective and efficient for enterprises. 24xlarge instances.
Software development is one arena where we are already seeing significant impacts from generativeAI tools. A McKinsey study claims that software developers can complete coding tasks up to twice as fast with generativeAI. GenerativeAI is just one tool in the toolbelt.
Gentrace , a cutting-edge platform for testing and monitoring generativeAI applications, has announced the successful completion of an $8 million Series A funding round led by Matrix Partners , with contributions from Headline and K9 Ventures. billion by 2030 , expanding at a compound annual growth rate (CAGR) of 34.2%.
Scalable infrastructure – Bedrock Marketplace offers configurable scalability through managed endpoints, allowing organizations to select their desired number of instances, choose appropriate instance types, define custom auto scaling policies that dynamically adjust to workload demands, and optimize costs while maintaining performance.
model = AutoModelForCausalLM.from_pretrained(model_id, trust_remote_code=True, quantization_config=bnb_config, device_map="auto") With Hugging Face’s PEFT library, you can freeze most of the original model weights and replace or extend model layers by training an additional, much smaller, set of parameters.
It is built on top of OpenAI’s Generative Pretrained Transformer (GPT-3.5 autogpt : Auto-GPT is an “Autonomous AI agent” that given a goal in natural language, will allow Large Language Models (LLMs) to think, plan, and execute actions for us autonomously. The complete code of the APP can be found here.
As organizations navigate the complexities of the digital realm, generativeAI has emerged as a transformative force, empowering enterprises to enhance productivity, streamline workflows, and drive innovation. It is redefining the way businesses approach data-driven decision-making, content generation, and secure task management.
GenerativeAI continues to push the boundaries of what’s possible. One area garnering significant attention is the use of generativeAI to analyze audio and video transcripts, increasing our ability to extract valuable insights from content stored in audio or video files. Current status is {job_status}.")
DSX provides unmatched prevention and explainability by using a powerful combination of deep learning-based DSX Brain and generativeAI DSX Companion to protect systems from known and unknown malware and ransomware in real-time.
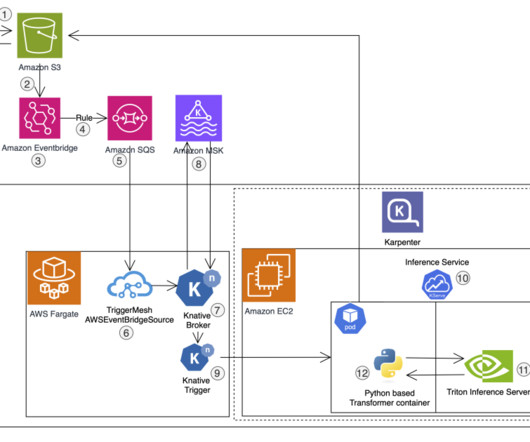
Deployment is fully automated with GitLab CI/CD pipelines, Terraform, and Helm, requiring less than an hour to complete without any downtime. We use Karpenter as the cluster auto scaler. These results can also serve as a data source for generativeAI features such as automated report generation.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















Let's personalize your content