This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With advancements in deeplearning, natural language processing (NLP), and AI, we are in a time period where AI agents could form a significant portion of the global workforce. Neural Networks & DeepLearning : Neural networks marked a turning point, mimicking human brain functions and evolving through experience.
Auto-generated code suggestions can increase developers’ productivity and optimize their workflow by providing straightforward answers, handling routine coding tasks, reducing the need to context switch and conserving mental energy. It can also modernize legacy code and translate code from one programming language to another.
Tabnine Although Tabnine is not an end-to-end code generator, it amps up the integrated development environment’s (IDE) auto-completion capability. Jacob Jackson created Tabnine in Rust when he was a student at the University of Waterloo, and it has now grown into a complete AI-based code completion tool.
sktime — Python Toolbox for Machine Learning with Time Series Editor’s note: Franz Kiraly is a speaker for ODSC Europe this June. Be sure to check out his talk, “ sktime — Python Toolbox for Machine Learning with Time Series ,” there! Welcome to sktime, the open community and Python framework for all things time series.
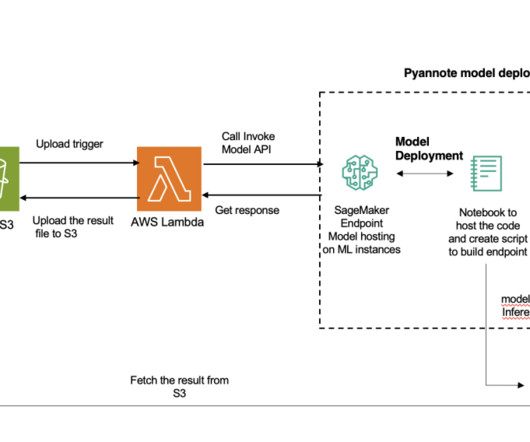
The added benefit of asynchronous inference is the cost savings by auto scaling the instance count to zero when there are no requests to process. Hugging Face is a popular open source hub for machine learning (ML) models. PyAnnote is an open source toolkit written in Python for speaker diarization.
Tabnine Although Tabnine is not an end-to-end code generator, it amps up the integrated development environment’s (IDE) auto-completion capability. Jacob Jackson created Tabnine in Rust when he was a student at the University of Waterloo, and it has now grown into a complete AI-based code completion tool.
AWS Neuron is the SDK used to run deeplearning workloads on AWS Inferentia and AWS Trainium based instances. AWS Neuron includes a deeplearning compiler , runtime , and tools that are natively integrated with popular frameworks like TensorFlow and PyTorch. GPU Optimized Kernel using a ml.g5.2xlarge instance type.
In this post, we look at how we can use AWS Glue and the AWS Lake Formation ML transform FindMatches to harmonize (deduplicate) customer data coming from different sources to get a complete customer profile to be able to provide better customer experience. The following diagram shows our solution architecture.
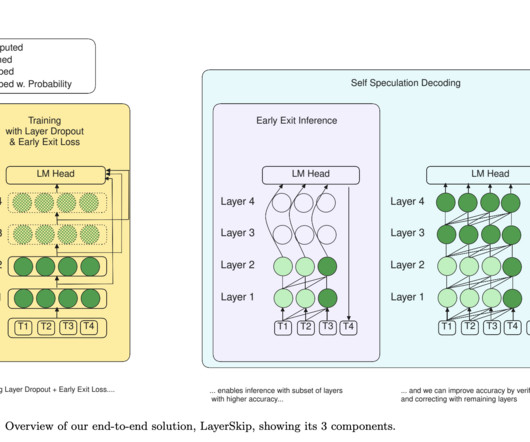
The model defines and autocompletes the function’s body when the prompt comprises a docstring and a Python function header. Instead of spreading computation across all levels, deeplearning models must be more motivated to forecast their final output early.
Custom Queries provides a way for you to customize the Queries feature for your business-specific, non-standard documents such as auto lending contracts, checks, and pay statements, in a self-service way. This section will activate your next steps as you complete them sequentially. What is the account name/payer/drawer name?
Another innovative framework, Chameleon, takes a “plug-and-play” approach, allowing a central LLM-based controller to generate natural language programs that compose and execute a wide range of tools, including LLMs, vision models, web search engines, and Python functions.
In late 2022, AWS announced the general availability of Amazon EC2 Trn1 instances powered by AWS Trainium accelerators, which are purpose built for high-performance deeplearning training. We use the Neuron SDK to run deeplearning workloads on AWS Inferentia and Trainium-based instances. Choose Create repository.
The compute clusters used in these scenarios are composed of more than thousands of AI accelerators such as GPUs or AWS Trainium and AWS Inferentia , custom machine learning (ML) chips designed by Amazon Web Services (AWS) to accelerate deeplearning workloads in the cloud.
Kernel Auto-tuning : TensorRT automatically selects the best kernel for each operation, optimizing inference for a given GPU. These techniques allow TensorRT-LLM to optimize inference performance for deeplearning tasks such as natural language processing, recommendation engines, and real-time video analytics.
Deeplearning and semantic parsing, do we still care about information extraction? This… github.com Kite AutoComplete For all the Jupyter notebook fans, Kite code autocomplete is now supported! GPT-3 hype is cool but needs fine-tuning to be anywhere near production-ready. Where are those graphs?
The AWS partnership with Hugging Face allows a seamless integration through SageMaker with a set of DeepLearning Containers (DLCs) for training and inference, and Hugging Face estimators and predictors for the SageMaker Python SDK. AWS CDK version 2.0 The following figure shows the input conversation and output summary.
The decode phase includes the following: Completion – After the prefill phase, you have a partially generated text that may be incomplete or cut off at some point. The decode phase is responsible for completing the text to make it coherent and grammatically correct. The default is 32.
This is because a large portion of the available memory bandwidth is consumed by loading the model’s parameters and by the auto-regressive decoding process.As Then we highlight how Amazon SageMaker large model inference (LMI) deeplearning containers (DLCs) can help with these techniques.
Today, many modern Speech-to-Text APIs and Speaker Diarization libraries apply advanced DeepLearning models to perform tasks (A) and (B) near human-level accuracy, significantly increasing the utility of Speaker Diarization APIs. An embedding is a DeepLearning model’s low-dimensional representation of an input.
You can use ml.trn1 and ml.inf2 compatible AWS DeepLearning Containers (DLCs) for PyTorch, TensorFlow, Hugging Face, and large model inference (LMI) to easily get started. For the full list with versions, see Available DeepLearning Containers Images. These endpoints are fully managed and support auto scaling.
Llama 2 is an auto-regressive language model that uses an optimized transformer architecture and is intended for commercial and research use in English. In high performance computing (HPC) clusters, such as those used for deeplearning model training, hardware resiliency issues can be a potential obstacle.
Deeplearning (DL) is a fast-evolving field, and practitioners are constantly innovating DL models and inventing ways to speed them up. Custom operators are one of the mechanisms developers use to push the boundaries of DL innovation by extending the functionality of existing machine learning (ML) frameworks such as PyTorch.
Therefore, we decided to introduce a deeplearning-based recommendation algorithm that can identify not only linear relationships in the data, but also more complex relationships. When training is complete (through the Lambda step), the deployed model is updated to the SageMaker endpoint.
In this post, we demonstrate how to deploy Falcon for applications like language understanding and automated writing assistance using large model inference deeplearning containers on SageMaker. SageMaker large model inference (LMI) deeplearning containers (DLCs) can help. See the following code: %%writefile./code_falcon40b_deepspeed/serving.properties
PyTorch is a machine learning (ML) framework based on the Torch library, used for applications such as computer vision and natural language processing. One of the primary reasons that customers are choosing a PyTorch framework is its simplicity and the fact that it’s designed and assembled to work with Python. xlarge instance.
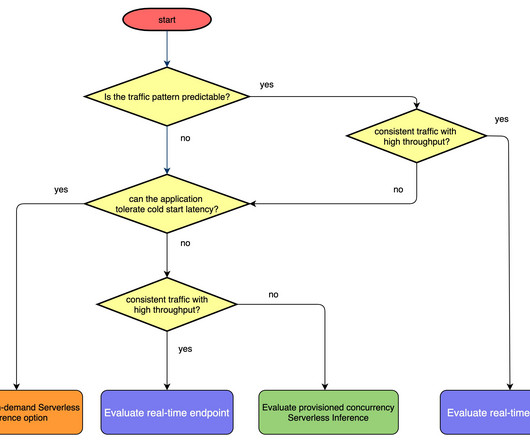
In addition, you can now use Application Auto Scaling with provisioned concurrency to address inference traffic dynamically based on target metrics or a schedule. In this post, we discuss what provisioned concurrency and Application Auto Scaling are, how to use them, and some best practices and guidance for your inference workloads.
This time-consuming process must be completed before content can be dubbed into another language. SageMaker asynchronous endpoints support upload sizes up to 1 GB and incorporate auto scaling features that efficiently mitigate traffic spikes and save costs during off-peak times. __dict__[WAV2VEC2_MODEL].get_model(dl_kwargs={"model_dir":
It’s built on causal decoder-only architecture, making it powerful for auto-regressive tasks. Discover Falcon 2 11B in SageMaker JumpStart You can access the FMs through SageMaker JumpStart in the SageMaker Studio UI and the SageMaker Python SDK. After deployment is complete, you will see that an endpoint is created.
Luckily, OpenCV is pip-installable: $ pip install opencv-contrib-python If you need help configuring your development environment for OpenCV, we highly recommend that you read our pip install OpenCV guide — it will have you up and running in a matter of minutes. . tensorflow and os ) on Lines 2 and 3. EPOCHS ) on Lines 20-23.
Furthermore, this tutorial aims to develop an image classification model that can learn to classify one of the 15 vegetables (e.g., If you are a regular PyImageSearch reader and have even basic knowledge of DeepLearning in Computer Vision, then this tutorial should be easy to understand. tomato, brinjal, and bottle gourd).
In addition, all SageMaker real-time endpoints benefit from built-in capabilities to manage and monitor models, such as including shadow variants , auto scaling , and native integration with Amazon CloudWatch (for more information, refer to CloudWatch Metrics for Multi-Model Endpoint Deployments ). 2xlarge instances.
Going from Data to Insights LexisNexis At HPCC Systems® from LexisNexis® Risk Solutions you’ll find “a consistent data-centric programming language, two processing platforms, and a single, complete end-to-end architecture for efficient processing.” These tools are designed to help companies derive insights from big data.
Deploy the CloudFormation template Complete the following steps to deploy the CloudFormation template: Save the CloudFormation template sm-redshift-demo-vpc-cfn-v1.yaml Launch SageMaker Studio Complete the following steps to launch your SageMaker Studio domain: On the SageMaker console, choose Domains in the navigation pane.
A practical guide on how to perform NLP tasks with Hugging Face Pipelines Image by Canva With the libraries developed recently, it has become easier to perform deeplearning analysis. Our model gets a prompt and auto-completes it. One of these libraries is Hugging Face. Let’s see how to perform a pipeline.
Knowledge and skills in the organization Evaluate the level of expertise and experience of your ML team and choose a tool that matches their skill set and learning curve. For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc.,
The CodeGen model allows users to translate natural language, such as English, into programming languages, such as Python. Salesforce developed an ensemble of CodeGen models (Inline for automatic code completion, BlockGen for code block generation, and FlowGPT for process flow generation) specifically tuned for the Apex programming language.
Hyperparameter optimization is highly computationally demanding for deeplearning models. script will create the VPC, subnets, auto scaling groups, the EKS cluster, its nodes, and any other necessary resources. script, you likely need to run a Python job to preprocess the data. eks-create.sh Instead of a data-prep.sh
Build and deploy your own sentiment classification app using Python and Streamlit Source:Author Nowadays, working on tabular data is not the only thing in Machine Learning (ML). In this article, you will learn about what sentiment analysis is and how you can build and deploy a sentiment analysis system in Python.
Popular Machine Learning Frameworks Tensorflow Tensorflow is a machine learning framework that was developed by Google’s brain team and has a variety of features and benefits. It supports languages like Python and R and processes the data with the help of data flow graphs. It is mainly used for deeplearning applications.
Prerequisites Complete the following prerequisite steps: If you’re a first-time user of QuickSight in your AWS account, sign up for QuickSight. amazonaws.com/ :latest Deploy the CloudFormation template Complete the following steps to deploy the CloudFormation template: Download the CloudFormation template kendrablog-sam-template.yml.
The AWS Python SDK Boto3 may also be combined with Torch Dataset classes to create custom data loading code. SageMaker jobs can be launched from a variety of programming languages, including Python and CLI. This results in faster restarts and workload completion. This reduces iteration time and inter-job placement variability.
It is handy when you are working on a machine learning project and want to understand which models and hyperparameters are most effective for your model. We can install this library in the same way as other Python libraries, using pip . We will build our deeplearning model using those parameters.
However, as the size and complexity of the deeplearning models that power generative AI continue to grow, deployment can be a challenging task. Then, we highlight how Amazon SageMaker large model inference deeplearning containers (LMI DLCs) can help with optimization and deployment.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content