This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With advancements in deeplearning, natural language processing (NLP), and AI, we are in a time period where AI agents could form a significant portion of the global workforce. Neural Networks & DeepLearning : Neural networks marked a turning point, mimicking human brain functions and evolving through experience.
Best Features: Predictive code generation: GitHub Copilot goes beyond simple auto-completion. The tool offers an impressive set of features that extend beyond the scope of code completion. This way, its suggestions become more personalized and accurate over time, making it a truly powerful companion in the programming process.
The practical success of deeplearning in processing and modeling large amounts of high-dimensional and multi-modal data has grown exponentially in recent years. Therefore, encoders, decoders, and auto-encoders can all be implemented using a roughly identical crate design. If you like our work, you will love our newsletter.
The KL730 auto-grade NPU chip packs an integrated Image Signal Processor (ISP) and promises to bring secure and energy-efficient AI capabilities to an extensive range of applications, spanning from enterprise-edge servers to smart home appliances and advanced driving assistance systems. The KL730 is a game-changer for edge AI.
Today, deeplearning technology, heavily influenced by Baidu’s seminal paper Deep Speech: Scaling up end-to-end speech recognition , dominates the field. In the next section, we’ll discuss how these deeplearning approaches work in more detail. How does speech recognition work?
It’s one of the prerequisite tasks to prepare training data to train a deeplearning model. Specifically, for deeplearning-based autonomous vehicle (AV) and Advanced Driver Assistance Systems (ADAS), there is a need to label complex multi-modal data from scratch, including synchronized LiDAR, RADAR, and multi-camera streams.
Auto-generated code suggestions can increase developers’ productivity and optimize their workflow by providing straightforward answers, handling routine coding tasks, reducing the need to context switch and conserving mental energy. It can also modernize legacy code and translate code from one programming language to another.
Tabnine Although Tabnine is not an end-to-end code generator, it amps up the integrated development environment’s (IDE) auto-completion capability. Jacob Jackson created Tabnine in Rust when he was a student at the University of Waterloo, and it has now grown into a complete AI-based code completion tool.
With nine times the speed of the Nvidia A100, these GPUs excel in handling deeplearning workloads. Image and Document Processing Multimodal LLMs have completely replaced OCR. Recent advancements in hardware such as Nvidia H100 GPU, have significantly enhanced computational capabilities.
Amazon Lex is powered by the same deeplearning technologies used in Alexa. Application Auto Scaling is enabled on AWS Lambda to automatically scale Lambda according to user interactions. Prerequisites The following prerequisites need to be completed before building the solution.
At its booth, NVIDIA will showcase how it’s building automotive assistants to enhance driver safety, security and comfort through enhanced perception, understanding and generative capabilities powered by deeplearning and transformer models. Li Auto unveiled its multimodal cognitive model, Mind GPT, in June.
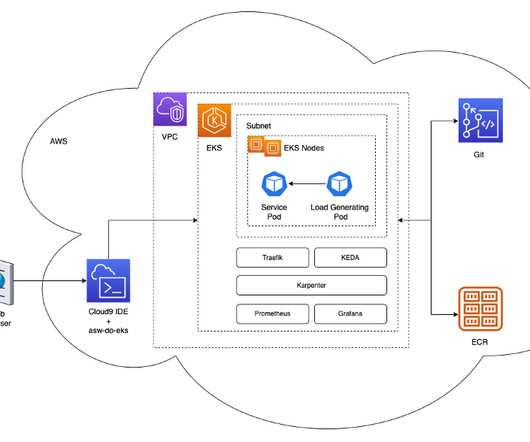
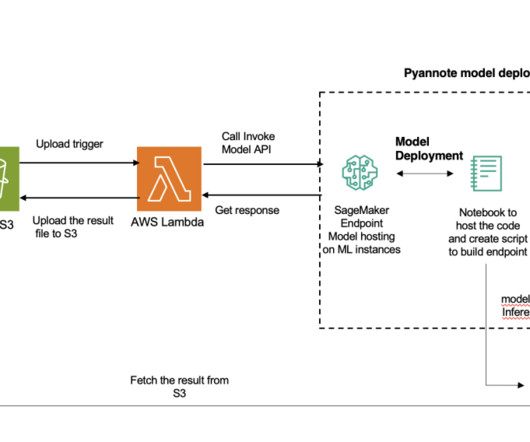
In this post, we look at how we can use AWS Glue and the AWS Lake Formation ML transform FindMatches to harmonize (deduplicate) customer data coming from different sources to get a complete customer profile to be able to provide better customer experience. The following diagram shows our solution architecture.
These models are AI algorithms that utilize deeplearning techniques and vast amounts of training data to understand, summarize, predict, and generate a wide range of content, including text, audio, images, videos, and more. If the system encounters any issue during the runtime, the process is repeated until it is resolved completely.
Our deeplearning models have non-trivial requirements: they are gigabytes in size, are numerous and heterogeneous, and require GPUs for fast inference and fine-tuning. We use Amazon EKS and were looking for the best solution to auto scale our worker nodes. This enables all steps to be completed from a web browser.
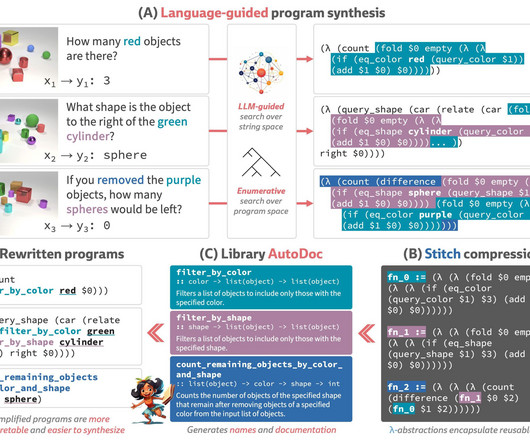
It will be necessary to expand the capabilities of current code completion tools—which are presently utilized by millions of programmers—to address the issue of library learning to solve this multi-objective optimization. Figure 1: The LILO learning loop overview. (Al)
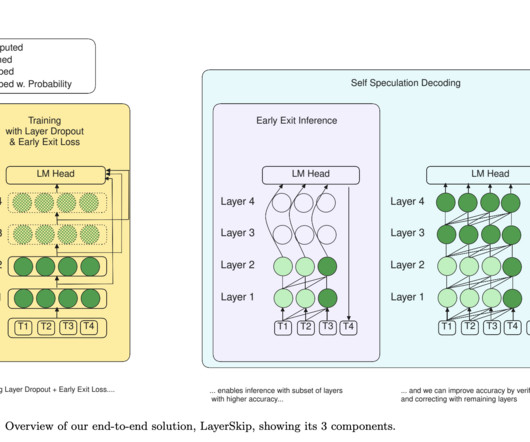
The model defines and autocompletes the function’s body when the prompt comprises a docstring and a Python function header. Instead of spreading computation across all levels, deeplearning models must be more motivated to forecast their final output early.
Custom Queries provides a way for you to customize the Queries feature for your business-specific, non-standard documents such as auto lending contracts, checks, and pay statements, in a self-service way. This section will activate your next steps as you complete them sequentially. What is the account name/payer/drawer name?
For years, Rad AI has been a reliable partner to radiology practices and health systems, consistently delivering high availability and generating complete results seamlessly in 0.5–3 Dmitry Soldatkin is a Senior Machine Learning Solutions Architect at Amazon Web Services (AWS), helping customers design and build AI/ML solutions.
Tabnine Although Tabnine is not an end-to-end code generator, it amps up the integrated development environment’s (IDE) auto-completion capability. Jacob Jackson created Tabnine in Rust when he was a student at the University of Waterloo, and it has now grown into a complete AI-based code completion tool.
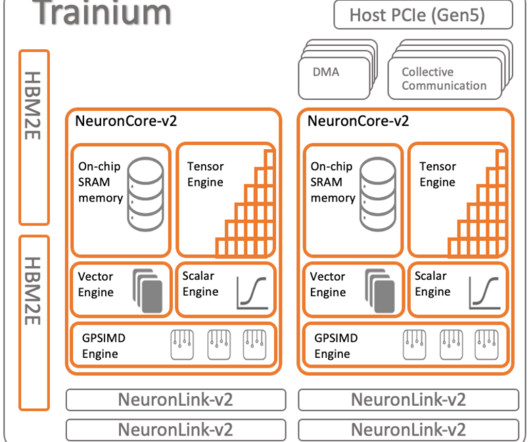
The compute clusters used in these scenarios are composed of more than thousands of AI accelerators such as GPUs or AWS Trainium and AWS Inferentia , custom machine learning (ML) chips designed by Amazon Web Services (AWS) to accelerate deeplearning workloads in the cloud.
release , you can now launch Neuron DLAMIs (AWS DeepLearning AMIs) and Neuron DLCs (AWS DeepLearning Containers) with the latest released Neuron packages on the same day as the Neuron SDK release. AWS DLCs provide a set of Docker images that are pre-installed with deeplearning frameworks.
The added benefit of asynchronous inference is the cost savings by auto scaling the instance count to zero when there are no requests to process. Hugging Face is a popular open source hub for machine learning (ML) models. Prerequisites Complete the following prerequisites: Create a SageMaker domain.
Currently chat bots are relying on rule-based systems or traditional machine learning algorithms (or models) to automate tasks and provide predefined responses to customer inquiries. Enterprise organizations (many of whom have already embarked on their AI journeys) are eager to harness the power of generative AI for customer service.
Let's explore some of these cutting-edge methods in detail: Auto-CoT (Automatic Chain-of-Thought Prompting) What It Is: Auto-CoT is a method that automates the generation of reasoning chains for LLMs, eliminating the need for manually crafted examples.
AWS Neuron is the SDK used to run deeplearning workloads on AWS Inferentia and AWS Trainium based instances. AWS Neuron includes a deeplearning compiler , runtime , and tools that are natively integrated with popular frameworks like TensorFlow and PyTorch.
The decode phase includes the following: Completion – After the prefill phase, you have a partially generated text that may be incomplete or cut off at some point. The decode phase is responsible for completing the text to make it coherent and grammatically correct. The default is 32.
For a complete list of runtime configurations, please refer to text-generation-launcher arguments. SageMaker endpoints also support auto-scaling, allowing DeepSeek-R1 to scale horizontally based on incoming request volume while seamlessly integrating with elastic load balancing. The best performance was observed on ml.p4dn.24xlarge
Traditional methods like ARIMA struggle with modern data complexities, but deeplearning has shown promise. Generating Longer Forecast Output Patches In Large Language Models (LLMs), output is generally produced in an auto-regressive manner, generating one token at a time. However, there is a trade-off.
This is because a large portion of the available memory bandwidth is consumed by loading the model’s parameters and by the auto-regressive decoding process.As Then we highlight how Amazon SageMaker large model inference (LMI) deeplearning containers (DLCs) can help with these techniques. Use MPI to enable continuous batching.
Deeplearning and semantic parsing, do we still care about information extraction? This… github.com Kite AutoComplete For all the Jupyter notebook fans, Kite code autocomplete is now supported! GPT-3 hype is cool but needs fine-tuning to be anywhere near production-ready. Where are those graphs?
In this post, we demonstrate how to deploy Falcon for applications like language understanding and automated writing assistance using large model inference deeplearning containers on SageMaker. SageMaker large model inference (LMI) deeplearning containers (DLCs) can help. code_falcon40b_deepspeed/model.py
of Large Model Inference (LMI) DeepLearning Containers (DLCs). The complete notebook with detailed instructions is available in the GitHub repo. For the TensorRT-LLM container, we use auto. In January 2024, Amazon SageMaker launched a new version (0.26.0) It is returned with the last streamed sequence chunk.
Deeplearning (DL) is a fast-evolving field, and practitioners are constantly innovating DL models and inventing ways to speed them up. Custom operators are one of the mechanisms developers use to push the boundaries of DL innovation by extending the functionality of existing machine learning (ML) frameworks such as PyTorch.
Llama 2 is an auto-regressive language model that uses an optimized transformer architecture and is intended for commercial and research use in English. In high performance computing (HPC) clusters, such as those used for deeplearning model training, hardware resiliency issues can be a potential obstacle.
Today, many modern Speech-to-Text APIs and Speaker Diarization libraries apply advanced DeepLearning models to perform tasks (A) and (B) near human-level accuracy, significantly increasing the utility of Speaker Diarization APIs. An embedding is a DeepLearning model’s low-dimensional representation of an input.
Further optimization is possible using SageMaker Training Compiler to compile deeplearning models for training on supported GPU instances. SageMaker Training Compiler converts deeplearning models from high-level language representation to hardware-optimized instructions.
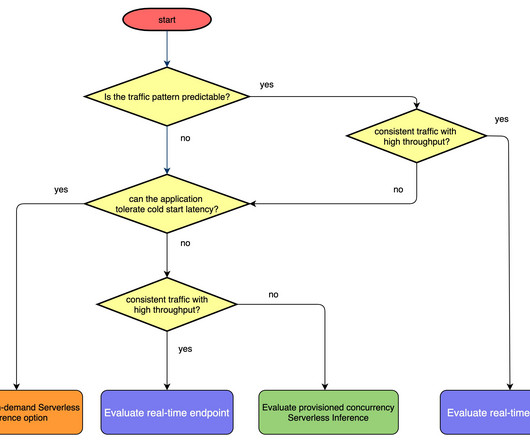
In addition, you can now use Application Auto Scaling with provisioned concurrency to address inference traffic dynamically based on target metrics or a schedule. In this post, we discuss what provisioned concurrency and Application Auto Scaling are, how to use them, and some best practices and guidance for your inference workloads.
Bigram Models Simplified Image generated by ChatGPT Introduction to Text Generation In Natural Language Processing, text generation creates text that can resemble human writing, ranging from simple tasks like auto-completing sentences to complex ones like writing articles or stories.
LLMs leverage deeplearning architectures to process and understand the nuances and context of human language. It offers a simple API for applying LLMs to up to 100 hours of audio data, even exposing endpoints for common use tasks It's smart enough to auto-generate subtitles, identify speakers, and transcribe audio in real time.
In late 2022, AWS announced the general availability of Amazon EC2 Trn1 instances powered by AWS Trainium accelerators, which are purpose built for high-performance deeplearning training. We use the Neuron SDK to run deeplearning workloads on AWS Inferentia and Trainium-based instances. Choose Create repository.
The AWS partnership with Hugging Face allows a seamless integration through SageMaker with a set of DeepLearning Containers (DLCs) for training and inference, and Hugging Face estimators and predictors for the SageMaker Python SDK. The following figure shows the input conversation and output summary.
Kernel Auto-tuning : TensorRT automatically selects the best kernel for each operation, optimizing inference for a given GPU. These techniques allow TensorRT-LLM to optimize inference performance for deeplearning tasks such as natural language processing, recommendation engines, and real-time video analytics.
Photo by NASA on Unsplash Hello and welcome to this post, in which I will study a relatively new field in deeplearning involving graphs — a very important and widely used data structure. This post includes the fundamentals of graphs, combining graphs and deeplearning, and an overview of Graph Neural Networks and their applications.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content