
Announcing Rekogniton Custom Moderation: Enhance accuracy of pre-trained Rekognition moderation models with your data
AWS Machine Learning Blog
OCTOBER 19, 2023
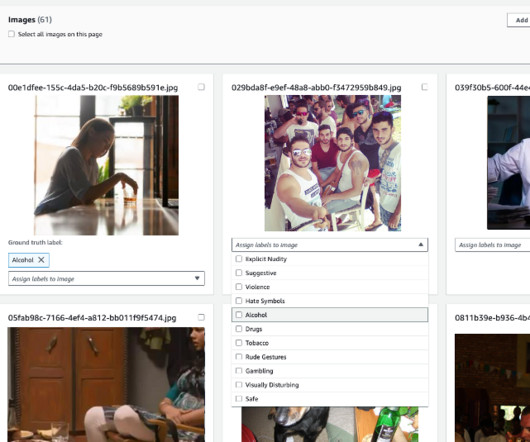
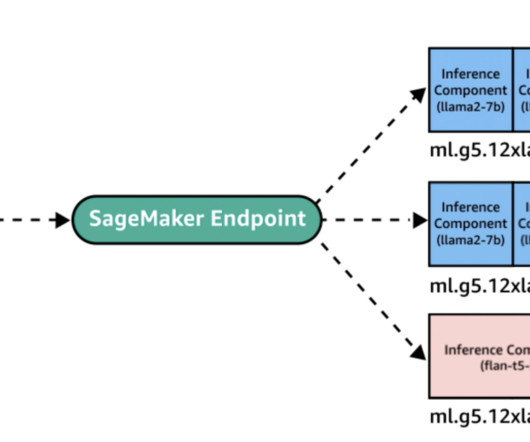
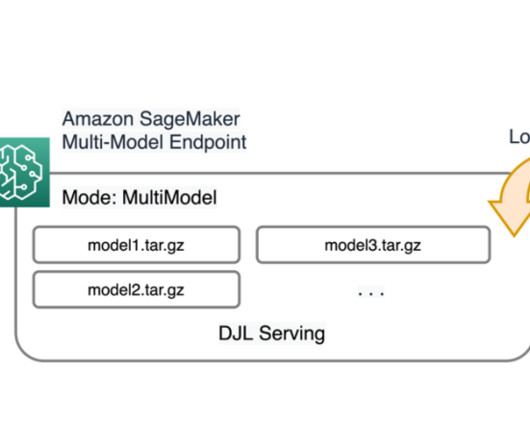
Content moderation in Amazon Rekognition Amazon Rekognition is a managed artificial intelligence (AI) service that offers pre-trained and customizable computer vision capabilities to extract information and insights from images and videos. Upload images from your computer and provide labels. Choose Create project.





















Let's personalize your content