This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Home Table of Contents Getting Started with Python and FastAPI: A Complete Beginner’s Guide Introduction to FastAPI Python What Is FastAPI? reload : Enables auto-reloading, so the server restarts automatically when you make changes to your code. Or requires a degree in computer science? Join me in computervision mastery.
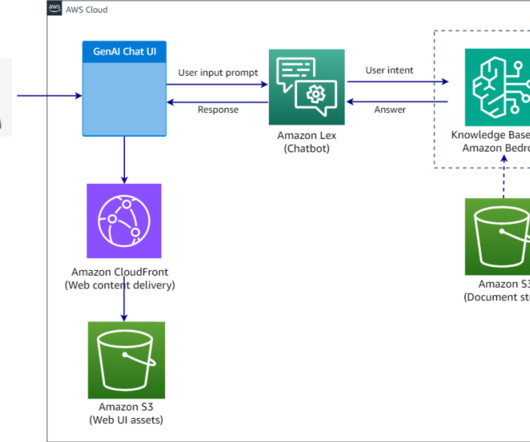
By linking this contextual information, the generative AI system can provide responses that are more complete, precise, and grounded in source data. Test the knowledge base Once the data sync is complete: Choose the expansion icon to expand the full view of the testing area.
Every episode is focused on one specific ML topic, and during this one, we talked to Michal Tadeusiak about managing computervision projects. I’m joined by my co-host, Stephen, and with us today, we have Michal Tadeusiak , who will be answering questions about managing computervision projects.
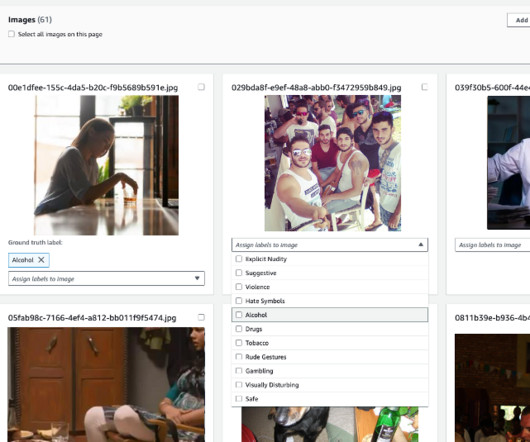
Content moderation in Amazon Rekognition Amazon Rekognition is a managed artificial intelligence (AI) service that offers pre-trained and customizable computervision capabilities to extract information and insights from images and videos. Upload images from your computer and provide labels. Choose Create project.
Create a knowledge base To create a new knowledge base in Amazon Bedrock, complete the following steps. For Data source name , Amazon Bedrock prepopulates the auto-generated data source name; however, you can change it to your requirements. You should see a Successfully built message when the build is complete. Choose Next.
This post details how Purina used Amazon Rekognition Custom Labels , AWS Step Functions , and other AWS Services to create an ML model that detects the pet breed from an uploaded image and then uses the prediction to auto-populate the pet attributes. Start the model version when training is complete.
The decode phase includes the following: Completion – After the prefill phase, you have a partially generated text that may be incomplete or cut off at some point. The decode phase is responsible for completing the text to make it coherent and grammatically correct. The default is 32.
In early trials, cuOpt delivered routing solutions in 10 seconds , achieving a 90% reduction in cloud costs and enabling technicians to complete more service calls daily. The company found that data scientists were having to remove features from algorithms just so they would run to completion.
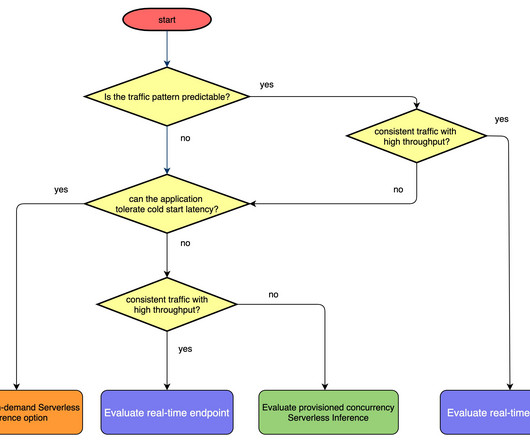
In addition, you can now use Application Auto Scaling with provisioned concurrency to address inference traffic dynamically based on target metrics or a schedule. In this post, we discuss what provisioned concurrency and Application Auto Scaling are, how to use them, and some best practices and guidance for your inference workloads.
This version offers support for new models (including Mixture of Experts), performance and usability improvements across inference backends, as well as new generation details for increased control and prediction explainability (such as reason for generation completion and token level log probabilities).
LMI DLCs are a complete end-to-end solution for hosting LLMs like Falcon-40B. You can monitor the status of the endpoint by calling DescribeEndpoint , which will tell you when everything is complete. His expertise lies in Deep Learning in the domains of Natural Language Processing (NLP) and ComputerVision.
I will begin with a discussion of language, computervision, multi-modal models, and generative machine learning models. Over the next several weeks, we will discuss novel developments in research topics ranging from responsible AI to algorithms and computer systems to science, health and robotics. Let’s get started!
You can also edit the auto scaling policy on the Auto-scaling tab on this page. You can see the network, security, and compute information for this endpoint on the Settings tab. Deploy a SageMaker JumpStart LLM To deploy a SageMaker JumpStart LLM, complete the following steps: Navigate to the JumpStart page in SageMaker Studio.
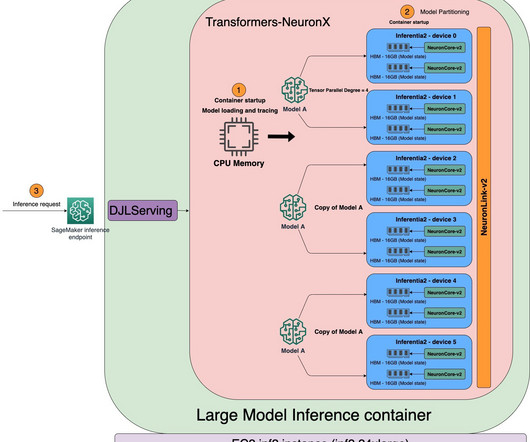
For ultra-large models that don’t fit into a single accelerator, data flows directly between accelerators with NeuronLink, bypassing the CPU completely. These endpoints are fully managed and support auto scaling. xlarge" ) Refer to Developer Flows for more details on typical development flows of Inf2 on SageMaker with sample scripts.
In this blog post, we explore a comprehensive approach to time series forecasting using the Amazon SageMaker AutoMLV2 SoftwareDevelopment Kit (SDK). In the training phase, CSV data is uploaded to Amazon S3, followed by the creation of an AutoML job, model creation, and checking for job completion.
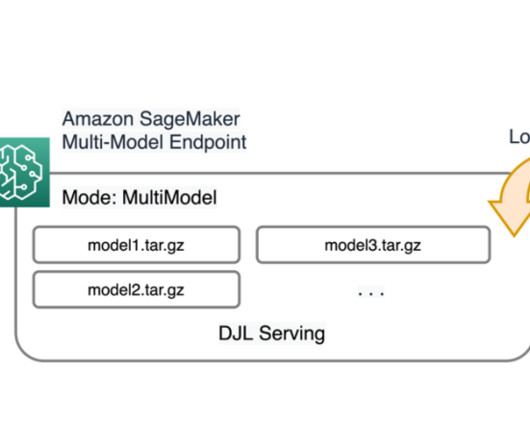
SageMaker LMI containers includes model download optimization by using the s5cmd library to speed up the model download time and container startup times, and eventually speed up auto scaling on SageMaker. A complete example that illustrates the no-code option can be found in the following notebook.
Llama 2 stands at the forefront of AI innovation, embodying an advanced auto-regressive language model developed on a sophisticated transformer foundation. The complete example is shown in the accompanying notebook. Its model parameters scale from an impressive 7 billion to a remarkable 70 billion.
With this feature, you can closely match your compute resource usage to your actual needs, potentially reducing costs during times of low demand. This enhancement builds upon the existing auto scaling capabilities in SageMaker, offering more granular control over resource allocation.
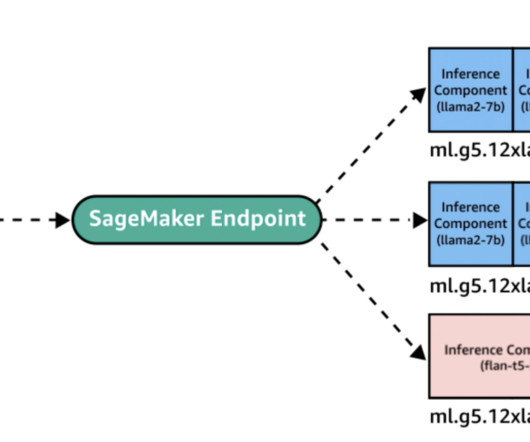
Because FM outputs could range from a single sentence to multiple paragraphs, the time it takes to complete the inference request varies significantly, leading to unpredictable spikes in latency if the requests are routed randomly between instances. In this post, we show you the new capabilities of IC-based SageMaker endpoints.
As a result, an initial invocation to a model might see higher inference latency than the subsequent inferences, which are completed with low latency. To take advantage of automated model scaling in SageMaker, make sure you have instance auto scaling set up to provision additional instance capacity.
is an auto-regressive language model that uses an optimized transformer architecture. You can now use state-of-the-art model architectures, such as language models, computervision models, and more, without having to build them from scratch. 405B-Instruct You can use Llama models for text completion for any piece of text.
Prime Air (our drones) and the computervision technology in Amazon Go (our physical retail experience that lets consumers select items off a shelf and leave the store without having to formally check out) use deep learning. This is a giant leap forward in developer productivity, and we believe this is only the beginning.
This process is like assembling a jigsaw puzzle to form a complete picture of the malwares capabilities and intentions, with pieces constantly changing shape. The meticulous nature of this process, combined with the continuous need for scaling, has subsequently led to the development of the auto-evaluation capability.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
























Let's personalize your content